

苹果公司近日在 AI 领域迈出了重要一步,推出了全新的 OpenELM 系列开源 AI 模型。这些模型小巧而高效,专为在单一设备上运行而设计,无需依赖云端服务器。OpenELM 的问世,标志着苹果正式加入到 Google、三星、微软等巨头的 AI 竞赛中。
OpenELM 共包含 8 个模型,参数规模从 2.7 亿到 30 亿不等,覆盖了不同大小的需求。其中,4 个为预训练模型,4 个为指令调整模型。预训练模型能够生成连贯且可能有帮助的文本,而指令调整模型则能针对用户的具体请求提供更相关的输出。
苹果公司以 “示例代码许可” 的形式发布了 OpenELM 模型的权重,允许商业使用和修改,但要求保留相关声明。此外,苹果还提供了模型训练的检查点、性能统计数据以及预训练、评估、指令调整和参数高效微调的详细指南。
这些模型的预训练使用了 1.8 万亿个 token 的公共数据集,来源包括 Reddit、Wikipedia 和 arXiv.org 等。它们不仅适用于普通的笔记本电脑,甚至一些智能手机也能运行。苹果在高性能工作站和搭载 M2 Max 芯片的 MacBook Pro 上进行了基准测试。
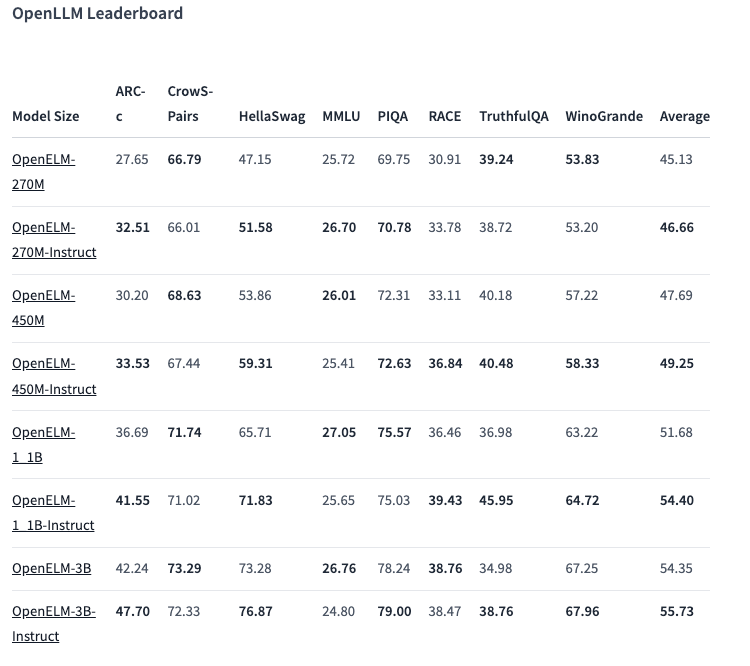
尽管 OpenELM 的模型规模不及市场上一些大型模型,但它们采用了逐层扩展策略,优化了准确性和计算效率。例如,450 百万参数的指令调整模型表现尤为出色。此外,1.1 亿参数的 OpenELM 模型在性能上超过了拥有 1.2 亿参数的 OLMo 模型,同时所需的预训练 token 数量仅为后者的一半。
OpenELM 的发布,不仅是苹果在开源 AI 领域的一次大胆尝试,也是对现有 AI 技术的一次重要补充。社区对苹果这一开放举措反响热烈,期待看到 OpenELM 在各种应用场景中发挥潜力。