
注:本文方案依赖于Python3、PyPDF2、LaunchBar。前两者是必要项,其安装方法很容易搜索到。LaunchBar严格地说并非必要项,只是起到代码容器和启动器的作用,个人认为LaunchBar是启动此类动作的最优方案,但如果你有不同的偏好,下载本文提供的LaunchBar动作,获取源代码后稍加改造即可。
不知是专业特色,还是国内电子书市场尚处草莽时代的缩影,想找我专业领域内的书籍,经常只能找到不带目录的扫描版。这里包括了两个问题,其一是扫描版文字默认不可复制或搜索,其二是默认不带可跳转的目录,扫描版PDF因其照片出身也无法基于原本的排版信息自动化生成目录。在OCR技术普及的今天,前者已经可以缓解;而后者依然没有一个便捷方案。
早在两年前,我和Minja讨论过如何为PDF添加目录,当时的一致结论是:找淘宝代劳1,无奈要处理的书太多,全都求诸淘宝成本太高。后者近期发布的基于 Keyboard Maestro 的半自动 PDF 目录做法介绍了一种模拟键鼠操作的低技术方案,具有相当强的通用性。本文的方案则借助PyPDF2,在自动化程度和生成层级目录方面有更好的表现。
本文将介绍:
- 一套经过检验的,从OCR获取文字目录后整理修正形成目录文件,并将目录导入PDF文件的操作流程;
- 一个基于Python、以LaunchBar整合的目录添加脚本。
第一步:获取并整理文字版目录
文字版目录,理论上可以尝试从豆瓣、电商网站、出版商网站获取,也可以自己手动OCR书籍文件目录页后复制。但实践中我已经不再尝试前一种方法,失败的次数太多,宁愿采用效率看似更低但确定性更强的后一种方式。需提醒的是,不同OCR软件的识别效果差距较大,值得在这一步挑一个更趁手的工具。比如从我个人实操经历来看,使用DEVONthink内置的OCR引擎得到的结果,与直接用ABBYY识别目录页得到的结果差距甚大,后者的后续工作量相对前者起码减半。
首先要做的是将文字版目录逐页复制,粘贴进文本编辑器中。最终目的是保存为一个以.bm为扩展名的纯文本目录文件(以下称bm文件),该文件将用于向PDF添加目录条目。bm文件内部的文本结构示例如下:
第一层级的标题1 1
第二层级的标题1 1
第三层级的标题1 1
第三层级的标题2 3
……
第二层级的标题2 5
……
每行可分为两个部分:第一部分是缩进与标题文本,缩进的一个层级用一个制表符表示,第一层级的标题无需缩进,第二层级的标题用一个制表符缩进,以此类推;第二部分是该标题文本对应的页码。两部分间以空格间隔。
对全部粘贴至文本编辑器的目录内容,我通常先进行一次繁体转简体的替换(使用LaunchBar内置的"Convert Text to Simplified Chinese"动作),原因是OCR识别出的中文可能繁简体混杂,有些甚至肉眼无法一眼分辨,无法排查替换,进而在后续搜索中造成问题。
处理文字版目录的文本编辑器并无过多要求,支持正则表达式查找与替换的即可3。正则表达式可以用于匹配和处理文本的特定模式(pattern),可以视为通配符的超级进阶版,是一种强大而灵活的工具,可以用于文本搜索、替换、验证、提取等操作。本文末尾的小结部分会提供目录制作场景下几个基础的正则表达式,但并一定不能适用于所有目录,也不一定是效率最高的表达式,因此强烈建议有需要的读者学习一下正则表达式的基础语法4,否则很难说不是欠下的又一笔技术债。
使用正则表达式构造出符合规则的文本结构后,肉眼核对一遍是否仍存在文字错误。我曾经想用AI来替代这一步,甚至为此写了一段Prompt5。无奈AI不争气,勤劳的时候提出一堆并不存在的问题,懒惰的时候甚至发现不了我草草一眼就看出的错误。不过在某种程度上,核对目录也可看作《如何阅读一本书》所称检视阅读的一部分,自己浏览一遍目录,似乎也不是太大的损失。
再下一步是把经过OCR得到的书籍目录页中的图书页码转换为PDF页码,即调整二者间的偏移量。这一步,Minja的文章用Numbers表格中的函数实现,本文则制作了一个LaunchBar动作来调节页码的偏移量,同时检测OCR得到的页码是否存在问题。其原因是,就我自己的经验来说,人眼对文字比较敏感,对数字大小不敏感,检查目录的同时检查数字页码是否存在问题有些强人所难。因此数字的部分让机器来核对更加适合,也更能胜任。该动作可以检查页码是否存在以下三类问题:1.内容行不以数字结尾(可能是由于错误的换行、OCR没有正确识别出数字等);2.页码倒挂,即下一行的页码数值小于上一行页码数值(可能是由于重复粘贴、OCR数字识别错误等);3.页码差值过大(提示粘贴的时候漏了一页目录的可能性),我将提醒阈值设为下一行的页码与上一行页码的差值大于等于20页,你也可以在动作内部自行修改。
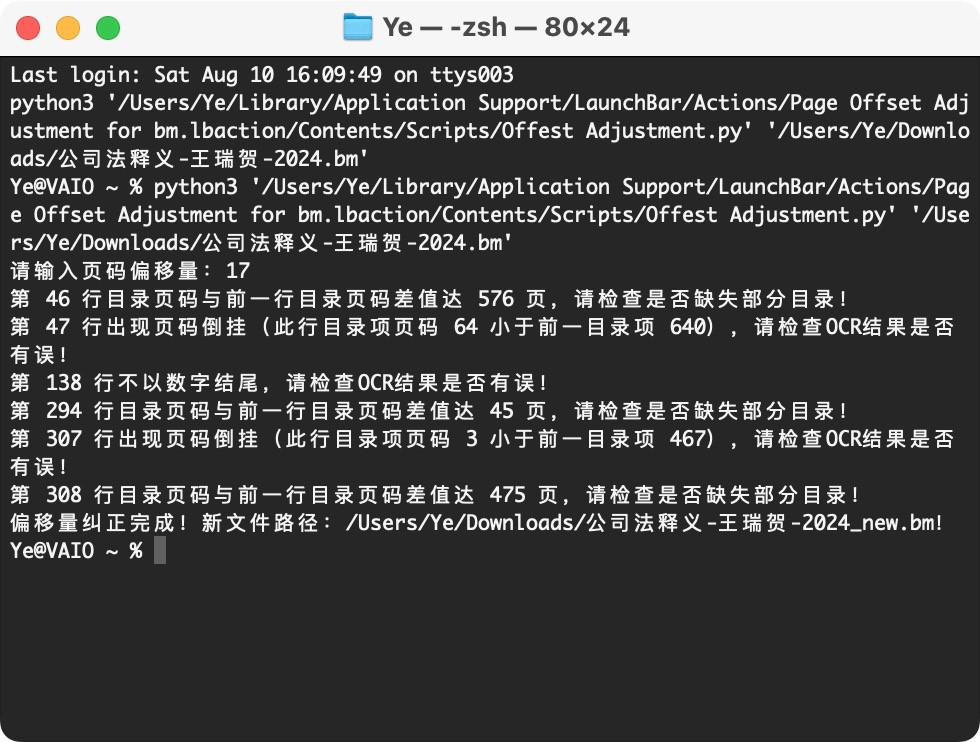
将bm文件发送到"Page Offset Adjustment for bm",即可运行该动作。交互页面采用唤出一个新终端窗口的方案,你需要先在终端窗口中按提示输入页码偏移量,随后动作会运行,调整页码并提示页码数值的以上三项异常,便于逐项排查和解决问题。动作运行完毕后,会在原bm文件的目录下生成一个新的,已调整页码偏移量的bm文件。
最后,视需要在新的bm文件中增加封面、版权、前言、目录等不在目录页中的条目,保存为以.bm结尾的纯文本文件。

第二步:将文字版目录注入PDF文件
这一步实现起来相对复杂,操作起来却非常简单,在LaunchBar中先选中bm文件,再选中PDF文件6,发送到LaunchBar动作“Bookmark to PDFdir via pyPDF2”即可。
如果在这一步报错,你可能需要检查:
- 你的设备上是否安装了Python3;
- 你的Python3解释器的路径是不是
/usr/local/bin/python3,如果不是,需要在LaunchBar脚本开头的Shebang行中把对应路径替换为你的Python3解释器路径; - 你的设备上是否安装了PyPDF2,以及是否安装在你的Python3解释器的对应路径下。
若动作成功运行,会在原PDF所在的文件夹下生成一个新的带目录的PDF文件,并自动打开,你可以检验生成的目录是否存在问题,即点击对应的目录,看是否能够跳转到对应的内容。如果不能,除了可能是bm文件的页码偏移量未设置正确外,还有可能是书籍PDF文件本身的问题。
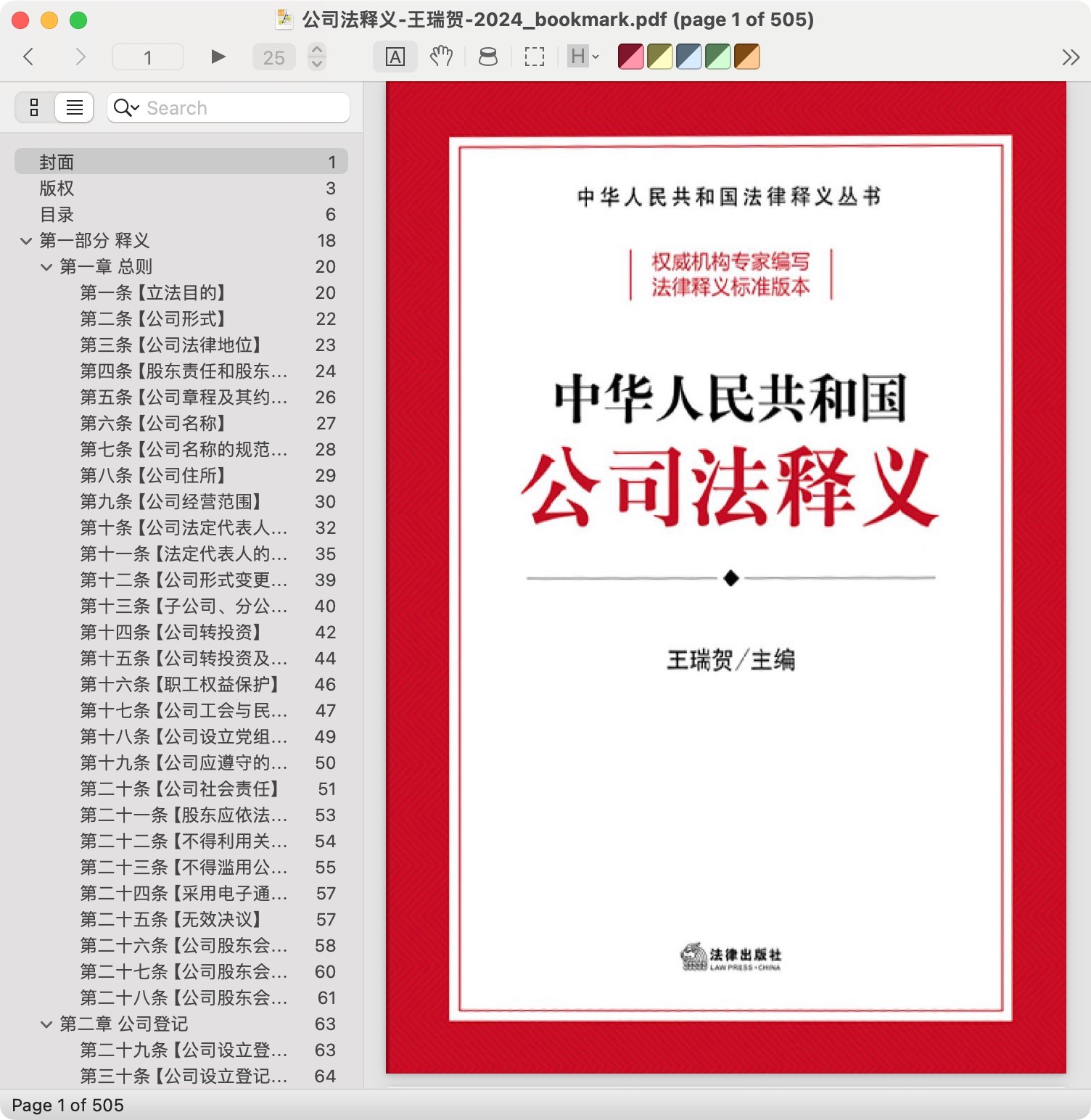
制作目录的过程也是检验书籍内容完整性的过程。我曾遇到过有100页重复页的PDF、大量漏页的PDF、奇偶数页面顺序错乱的PDF、前手好事之徒删除了空白页导致目录页码对不上的PDF。在按书籍目录页生成目录并注入文件后,这些问题马上原形毕露,很容易被发现。这些问题如果不是在书籍收录至数据库前(制作目录时)发现,而是在入库后甚至是阅读了一半时才发现,可能导致所有(更糟糕的情况是只有部分)引用至该书的链接都要修改,解决起来非常麻烦。
小结:书籍PDF目录制作指引
- 逐页复制目录页文字进空白文档;
- 繁体转简体;
- 删除所有行内空白字符,正则表达式
\s或[^\n\S](“或”之前的表达式适用于VSCode,“或”之后的表达式适用于BBEdit,如没有“或”则二者都适用,下同); - 浏览,手动修正OCR错误,重复错误内容可批量替换;
- 补充篇章页码(若篇章无页码);
- 页码前加空格,正则搜索
(\d+)$,替换为$1或\1; - 调整层级结构,注意低层级用制表符表示;同时给编章节后加空格。正则搜索
(第.{1,3}[编章节]),替换为$1或\t\1;注意有时手动更快(目录跳层级的情况); - 核对目录文字;
- 调整页码偏移量:运行LaunchBar动作“Page Offset Adjustment for bm”;
- 增加不在目录页中的条目(封面、版权、前言、目录等),保存bm文件;
- 依次选中bm、PDF文件,运行LaunchBar动作“Bookmark to PDFdir via pyPDF2”;
- 检查生成的PDF目录是否对应。
提醒:
- 在进行所有的全局替换前,都建议先确认一遍,这时BBEdit的Findall视图就显示出其优越性;
- 上述顺序和每一步的操作并不绝对,只是一个较为通用的流程,视书籍特点可以进行调整。
- Windows 上有一些简便的软件,但我们两人主要使用 Mac 电脑。——Minja 注 ↩
- "Bookmark to PDFdir via pyPDF2"动作的主要代码来自于qinshaoq/PdfBookmark: Auto export/import PDF's bookmark,但原库已经很久没有维护。我对原代码略作修改,使其适配了Python3和PyPDF2 3.0.x版本。若读者需将我的LaunchBar动作挪至其他代码容器或启动器,可右键点击该动作,选择“Show Package Contents”,进而在其中找到代码文件。 ↩
- 这里的编辑器,我早期使用的是VSCode(免费),近期在轻代码编辑器概念的影响下换到了BBEdit(高级功能付费),两者在功能上并没有太大差异,BBEdit的Findall视图有一定优势,二者正则表达式具体写法上有细微差别。 ↩
- 这是我学习正则表达式的文章链接:正则表达式30分钟入门教程。感谢deerchao! ↩
- “你是一名校对员。下面我会发给你一些书籍目录的OCR结果,其中可能会有一些错误。如果其中有错别字或不通顺的地方,请简明扼要指出错误之处;如果没有错误,回复“检查完毕,没有发现问题”就可以,不需要返回目录文本。谢谢!” ↩
- 在LaunchBar中多选文件的方法是:定位至某文件,同时按住
⌘和方向下(或方向上)键,该项即被固定选中。在此基础上,可以再选中第二个、第三个乃至更多文件。同时按住⇧和方向下(或方向上)键,可以连续选择多项。逻辑与使用鼠标+修饰键相同。 ↩