

翻译服务层出不穷,但多年过后,我依然在使用 Google。无他,限制最少而已,恰好足够翻译专业上的工具书和业余看的杂书。
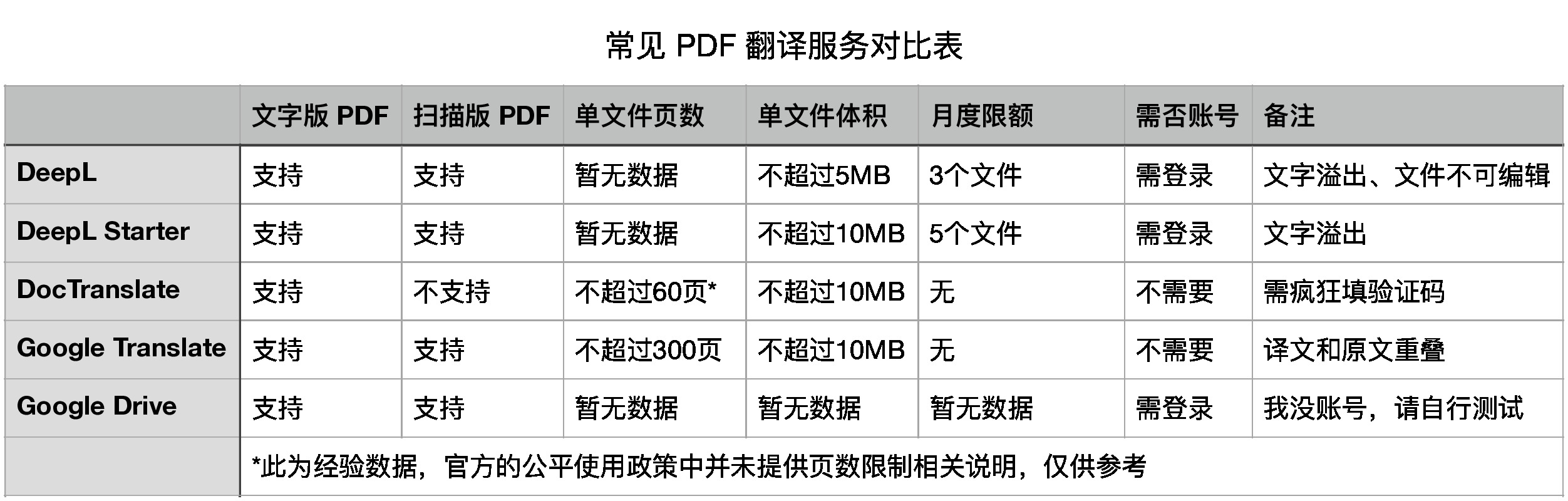
然而,扫描版的书籍,即便不考虑体积问题,成品往往也是译文与原文糊做一团,无法阅读。

好在此前绕过体积限制的方案,稍作调整,也可以修复扫描版 PDF 翻译后的显示问题。究其原因,不过是 PDF 大致呈皮影戏一般的分层结构,扫描版 PDF 通常最少有图片和文字两层,翻译后,文字被替换为译文,但图片原封不动,于是看上去就像是印刷错误的盗版书(尽管在某种意义上确实是盗版)。
这样想来,问题就转换为如何移除图片层。我依旧选择免费的命令行工具 ghostscript。

果然,移除背景后,Google 译得的翻译版 PDF 文件就没有了原始图片层,译文终得清楚显示。

顺予指出,作为附带好处,移除背景后的 PDF 通常也更加小巧,可避免占用过多体积。
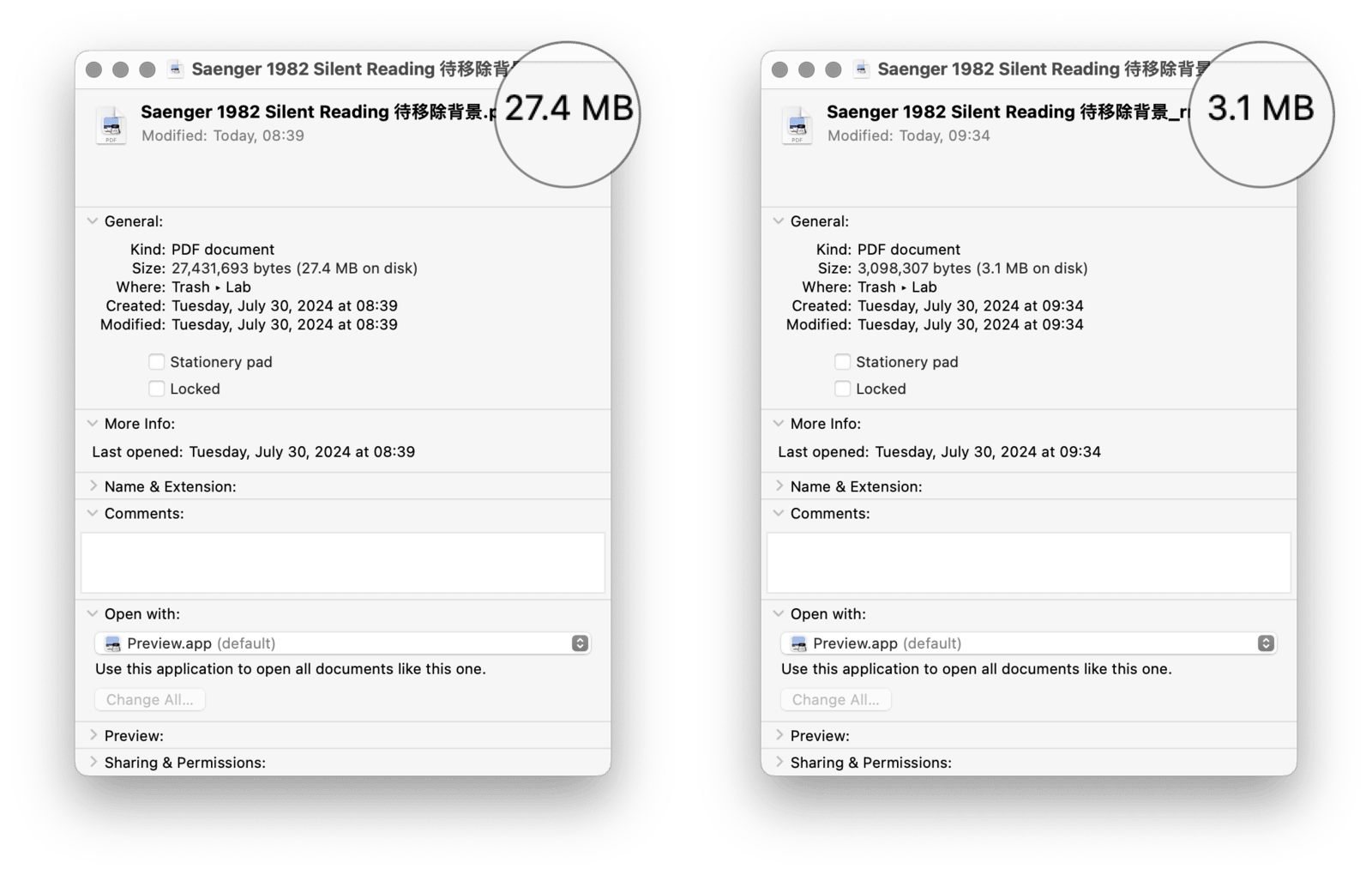
一旦把握 PDF 的分层结构,就像手握庖丁之刃的人抓住了筋骨之间的缝隙,之后的问题,旋迎刃而解。
(关于翻译质量:我有个在教会工作的熟人,他对机器翻译的吐槽十几年如一日。但吾辈不需要侍奉上帝,只求提高阅读速度。如果我读不出机器翻译的错误,那是我自己的问题。)