

批量下载网页图片的插件总是层出不穷,Shortcuts 扒图动作也是 iOS 自动化玩家中的热门话题。但是相比 Chrome、Firefox 甚至 Shortcuts 的热闹,macOS 上的 Safari 似乎常常被冷落一旁,很少有为其定制的扒图插件:Safari 插件阙如是一个既成事实。
这一尴尬的现状,多少和 Safari 严格的权限控制有关。好在正如 Shortcuts 可以强化 iOS 版 Safari,原生自动化工具 Automator 也能够解决 macOS 版 Safari 批量下载图片的饥荒。
但是实话实说,每个网站的“反爬虫”措施或代码风格各有不同,不存在哪个插件能够在所有网页中游刃有余。例如微信公众号文章,就很难直接扒取图片;对此我也做了专门适配,提供了公众号页面的专用扒图工具;其他的特殊网页自然不可能穷尽,后文将提供一种釜底抽薪的方法、直接从网页原始资源中抽取图片,尽可能覆盖绝大部分网页的扒图场景。
通用版:批量下载普通网页图片
最原始的图片下载方式,估计就是“右键另存为”。而在这一功能附近,通常也有“拷贝图片地址(Copy Image Address)”选项,拷贝下来的就是图片地址——这相当于图片的门牌号,只要将其输入浏览器,就能打开对应的图片。
批量下载图片的基本思路就是抓取当前页面的所有图片地址,然后根据这些地址挨家挨户地“拜访”图片,将它们下载至本地。详言之:
- 获取当前 Safari 页面的网页源码(HTML 代码);
- 从中抽取所有链接;
- 从第二步的结构中过滤出所有图片链接,通常是“jpg”、“jpeg” 和 “png” 等图片格式结尾;
- 下载上述链接对应的图片。
即便捋顺了思路,一般用户至此也该打退堂鼓了,毕竟前述操作听上去都像是网页开发的专业机能。很幸运,四个步骤都有相应的 Automator 模块,连一行代码都不需要写,直接就能像搭积木一样搭建出一个自动化动作。
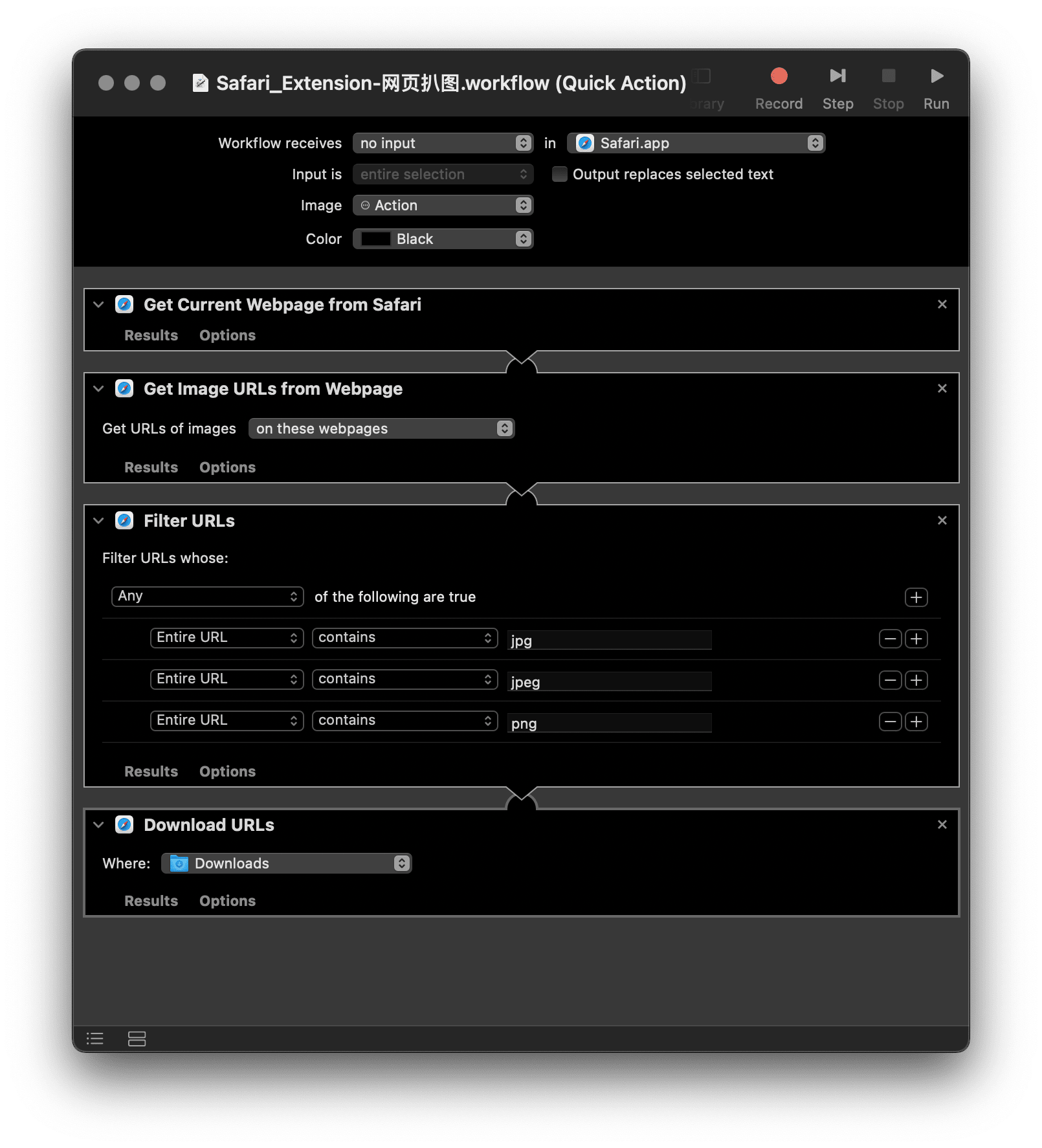
唯一需要注意的步骤是“Filter URLs(过滤 URL)”,动作默认设置了 3 种图片格式,网页上的图片只要符合任何一项即可被抓取到本地,你可以继续添加其他常用格式,比如 GIF、svg 或 webp。此外,过滤的条件是 contains(包含)而非以某种格式结尾,这是考虑到不少图片链接会带有后缀,限定过死会漏掉这些图片。
做好后的动作为 .workflow 格式,安装后可以在 Safari 的“服务(Services)”菜单中点击运行。
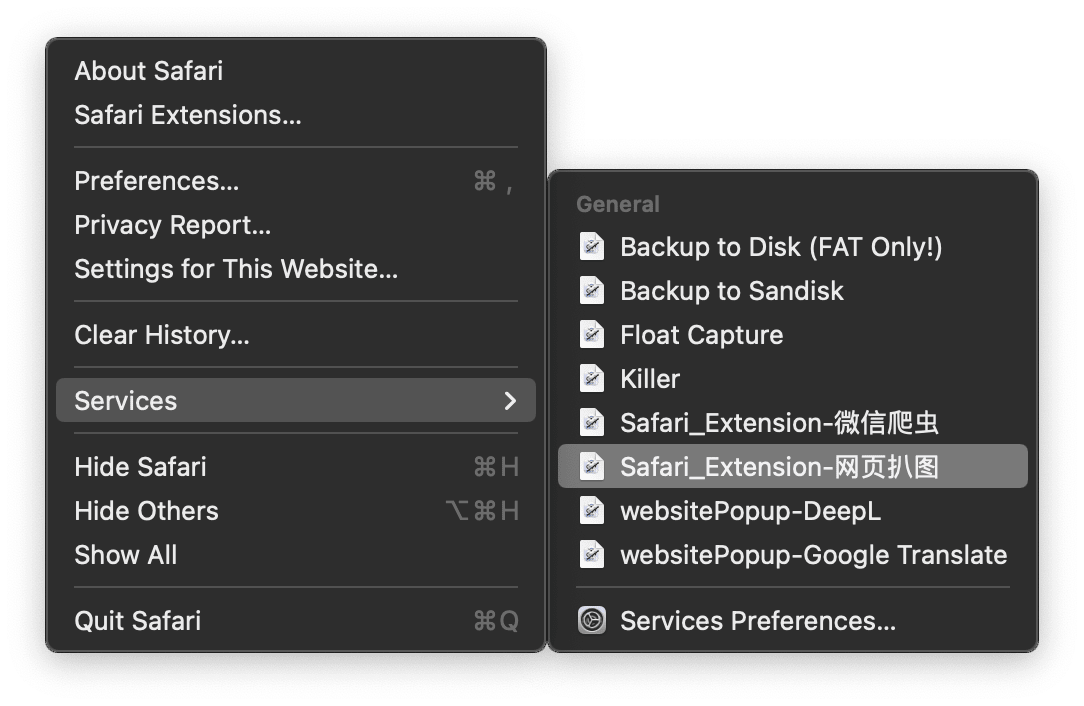
微信版:批量下载微信公众号文章图片
制作任何与网页交互的动作其实都是一件苦差事,毕竟总有些顽固份子,采取了较为严格的“反爬虫”措施,或者干脆代码写得不规整,总之很难批量下载图片。我在 Chrome 上安装过不少扒图插件,只要一次两次不奏效,就会怀疑这个插件已经废了——其实,通常只是遇上了一些顽固的网页。
没有通吃所有网页的万金油,但是有针对常用网页的特效药,比如,专治微信公众号1,很长一段时间里,公众号文章都让我头痛不已:不少法律资讯公众号会第一时间发布裁判文书和法律草案2,但往往是几十上百张图片(通常是照片或由 PDF 转换而来),不便于保存下来本地阅读。当然,喜欢发图的公众号远远不止它们,摄影类、美食类、家居类等等公众号也会发大量图片。上一节的动作面对这些文章无能为力,若你检查 Automator 运行结果,会发现它连一个图片链接都没有抓到。
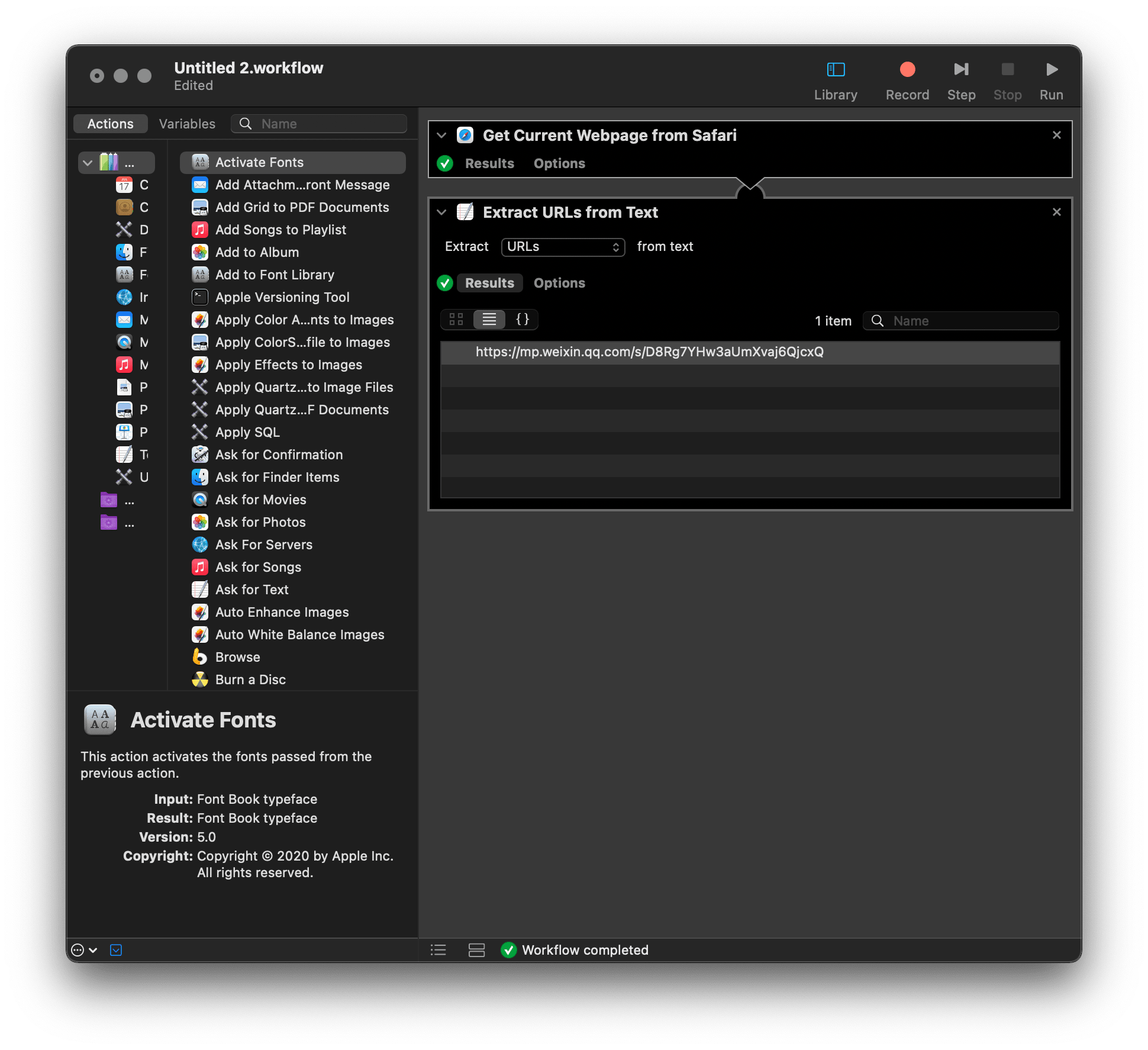
别说图片链接,就算试着用 Automator 抓其他类型的内容,基本也是竹篮打水。这种极端情况往往是网页编码(encode)方式特殊所致,不仅是图片链接,其他内容也被殃及。Automator 内置了 Shell 模板,可以运行命令行,而处理编码本身本身就是命令行的强项,对应的解决思路自此明朗:
- 获取网页源码,最常用的命令是
curl - 转换为更通用的编码,通常会用到命令
iconv
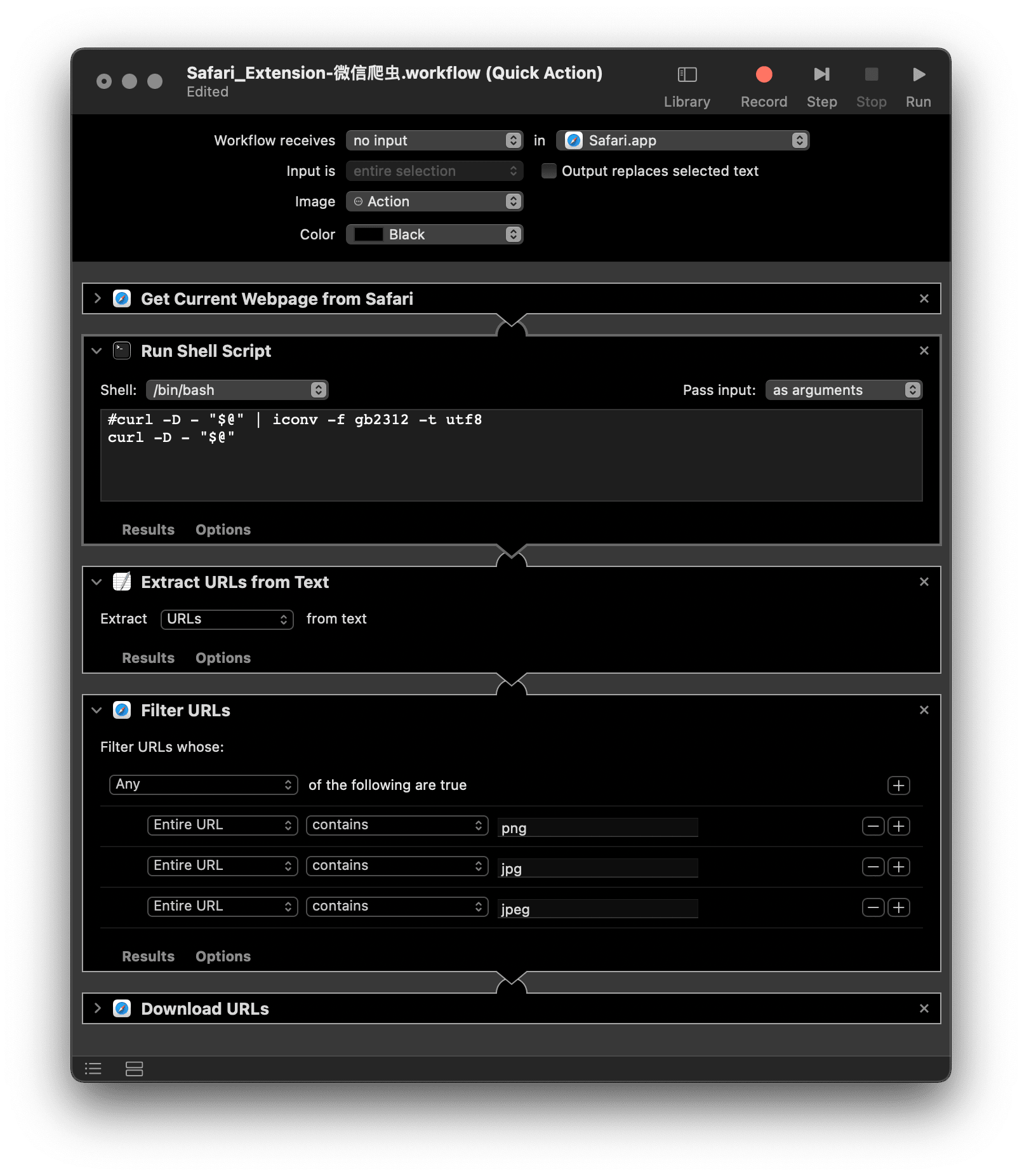
下载调整后的 Automator 动作,安装后再次尝试批量下载微信公众号文章配图,这次终于扒取正常。
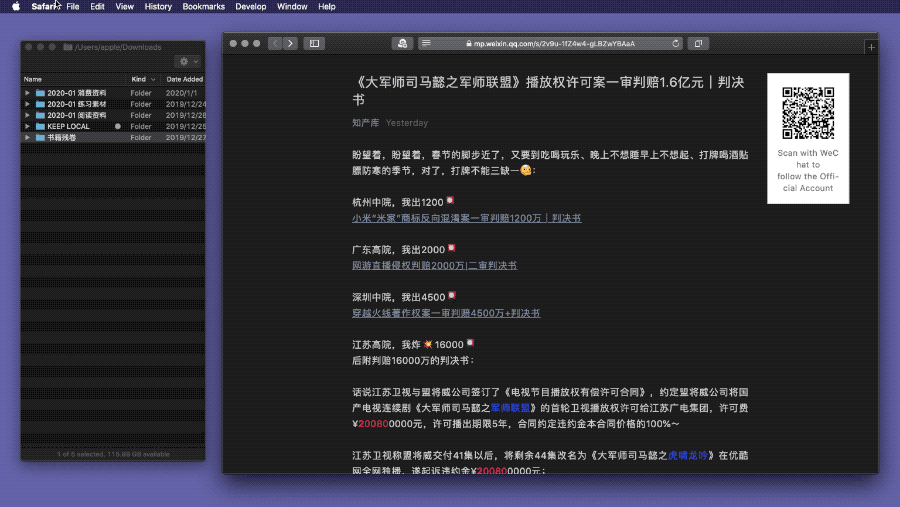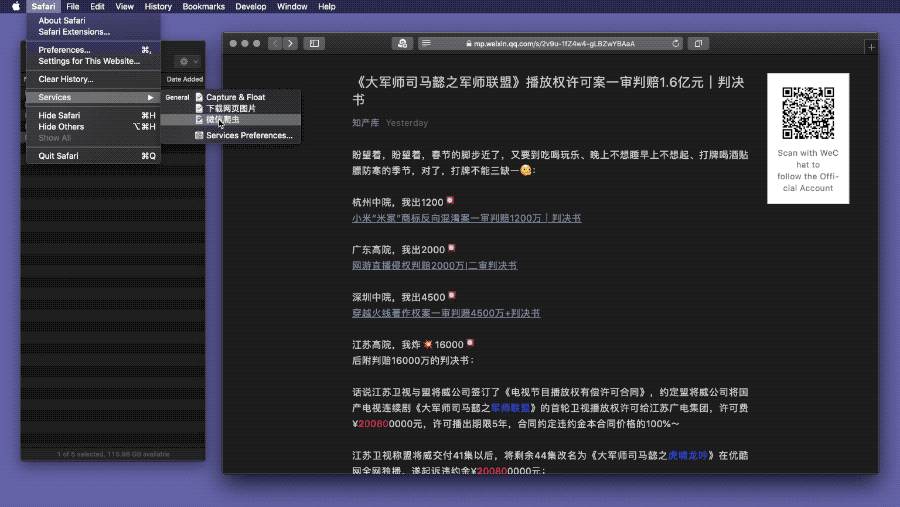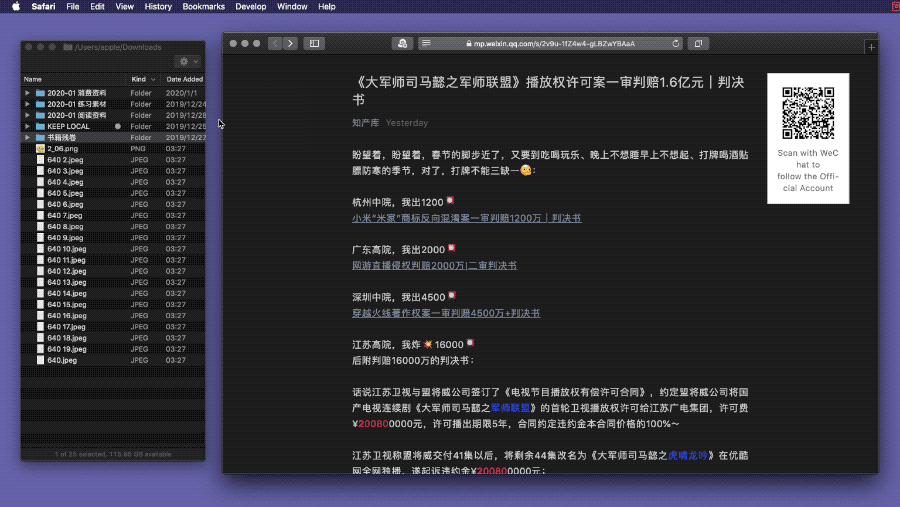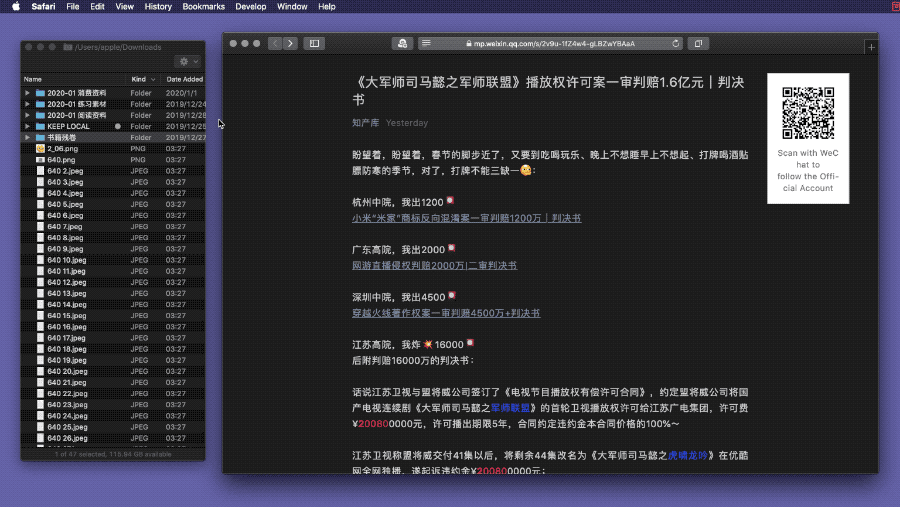
如果前一节的扒图动作在其他网站也不能正常使用,不妨检查一下其源代码,或者在 Automator 中检查“Extract URL from Text”步骤的结果,兴许和微信公众号页面存在类似的编码问题,那么微信扒图动作也能适用于它们。
杀手锏:从网页存档中抽取图片
遗憾的是,除了微信公众号,还有个别网站喜欢提防用户、妨碍下载图片,手段还是八仙过海;也有不少政府网站,单纯是年久失修、代码不规整,同样很难扒出其中的图片。对于这些网站,挨个定制扒图动作可能得不偿失,亟需一个兜底的方法。
适才面对公众号文章,已经初涉了网站源代码,现在可以再进一步,直接将整个网页的资源扒取到本地,随后慢条斯理地从中抽出图片。具体操作是先按下 ⌘Command-S 保存整个网页及其资源为 Webarchive 文件,然后选中该网页存档,右键运行 Automator 动作,即可在当前文件夹中创建一个新文件夹,内含该网页的所有资源,当然也包括了图片。
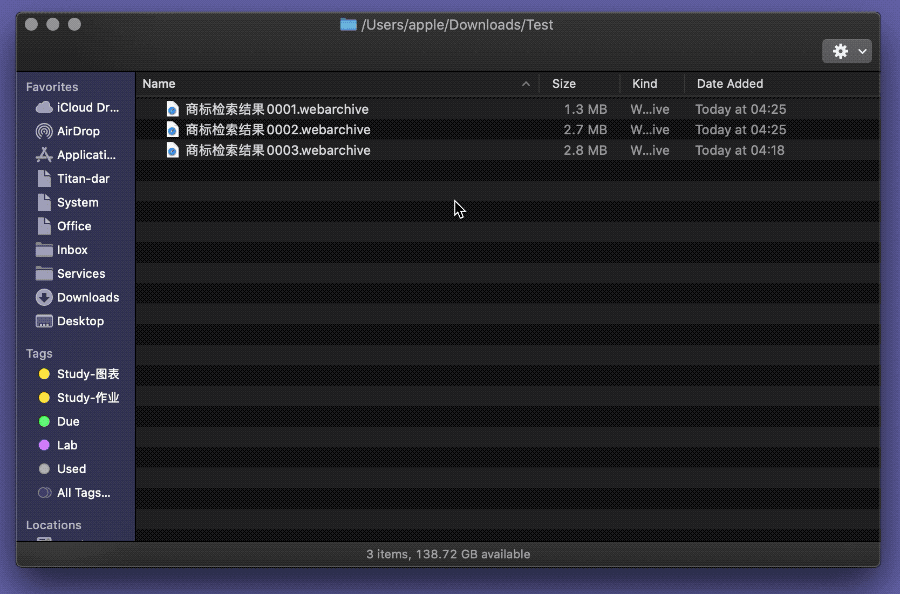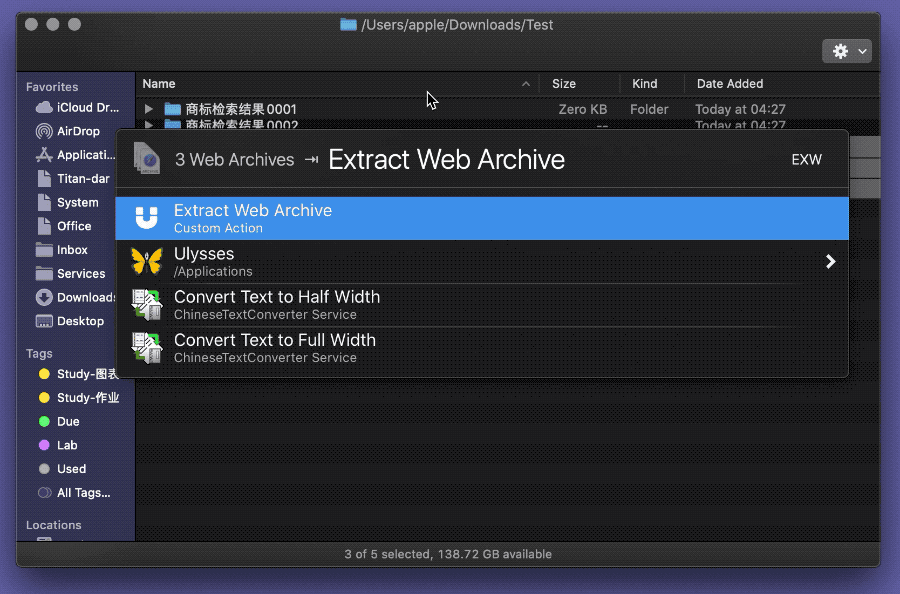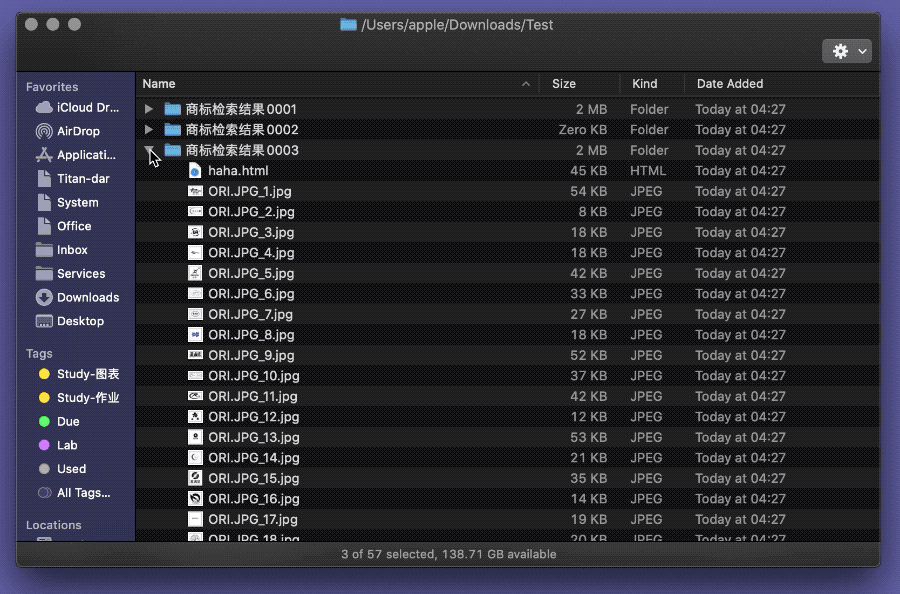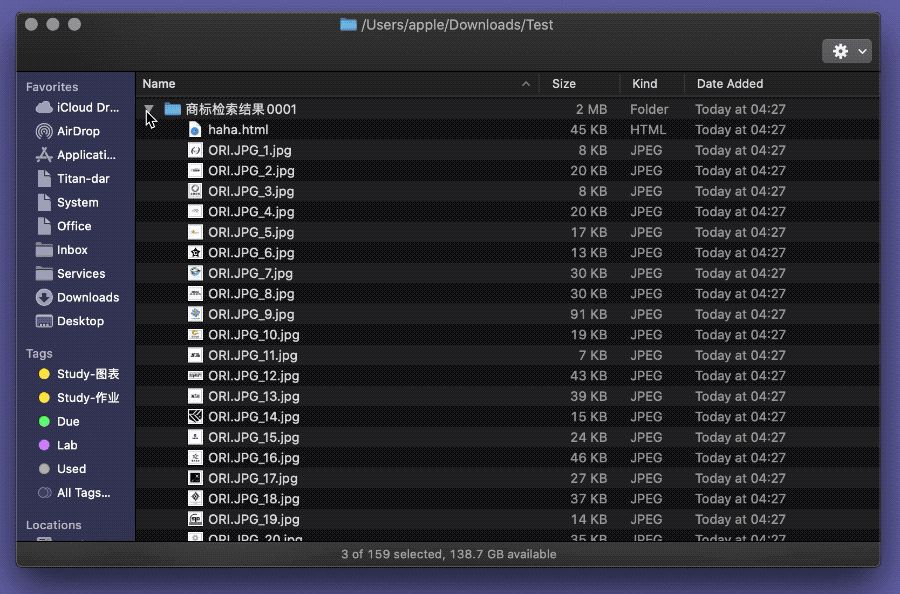
整个过程完全在本地完成,不涉及访问 API、发送请求等高阶操作,网页反而不会发现用户在“扒图”,即便是一些“反爬虫”严格的网页3,对用户的本地文件也是鞭长莫及,自然不可能阻止本节所介绍的方法。
我在工作中经常去商标局做商标检索,动辄需要采集成百上千张图片,虽然网页本身没有做什么限制,但是网站比较老,代码可能缺乏维护,一般的扒图动作对它不起作用,还好有这个兜底的方法。苦于网页扒图的人士多矣,也有人出过奇招,比如用“按键精灵”之类的工具重复千百次“右键另存为”,但还是直接从网页存档中抽取图片、直捣黄龙来得痛快。
此外,部分在线浏览的作品采取了版权保护措施,通过本文介绍的方式均无法下载。日本有几家户外杂志(包括著名的 GOOUT)就不允许下载图片,对此我无意评价道德问题,但既然连本文这些都自动化动作都“无隙可乘”,起码说明这些网站已经努力设下了法律上的“技术措施”,再设法突破就有点撬门溜锁的味道,没什么必要,可能还会惹一身腥(比如封号)。
小结
Safari 权限管理素来严格,到了 macOS Catalyna 之后更是步步紧缩,连使用插件都需要事先安装独立 App。Safari 插件——如果你还认为这算得上“插件”的话——市场一直不温不火,甚至开始显露出颓势,也是有以致之。
好在 Automator 终归是“自己人”,Apple 对它网开一面,提供了不少与 Safari 交互的原生模块,这样一来,普通用户也能够自制一些实用“插件”,同时保证了数据安全。在权限管控更为严苛的 iOS 上,想搞点自动化基本先要过问一下 Shortcuts,这种现象本身是好是坏难以评价,但至少启发了一种思路:先穷尽系统原生自动化工具,说不定就柳暗花明。