

前言
用 Shortcuts 扒网页是非常好玩的自动化探索,既能高效的获得自己想要的内容,又能学习到很多领域中的通用知识——正则表达式、HTML、CSS、网站运作原理。 但是,用 Shortcuts 扒网页实在是太麻烦了。我制作的用 Shortcuts 保存微博图文大概 80 个动作,这些动作都需要拖动和点击来完成,而且一经完成几乎不能修改。
Shortcuts 是一个强大的工具,提供了直观的图形化界面,让用户可以创建自动化任务。然而,当任务涉及到复杂的逻辑或需要处理大量的数据时,使用 Shortcuts 变得困难。每个步骤都需要手动添加和配置,需要大量的时间和精力。随着任务的复杂性增加,原本简单直观的特性限制了其更多应用的可能性。 这时,我们需要一个帮手——原本就被设计为处理复杂数据的编程语言。利用编程语言优化 Shortcuts 操作,为 Shortcuts 插上翅膀的同时进入一个更广阔的自动化世界。
Scriptable 是一个可以运行 JavaScript 代码的 iOS App(免费),提供了一种更加灵活、强大的方式来处理自动化任务。与 Shortcuts 不同,Scriptable 可以用编程技术来创造复杂的脚本,而不仅仅是简单的步骤。Scriptable 甚至还可以用来制作小组件!
Scriptable 提供了大量的 API,可以访问和控制设备的各种功能,包括文件系统、网络、设备传感器等,可以创建更加复杂和强大的脚本。
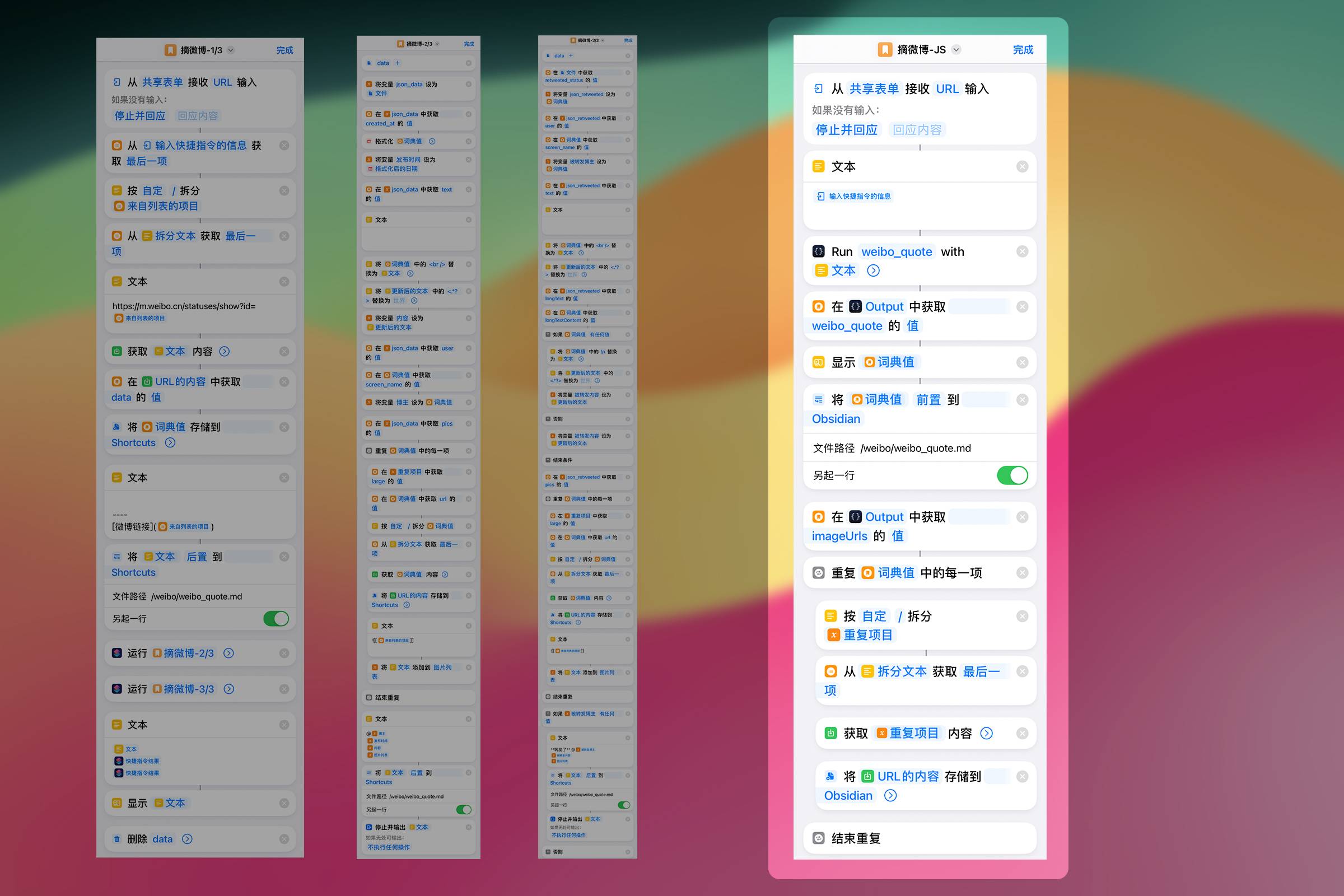
注:截图中的方案尚不完美,Scriptable 下载微博图片时有一定机率使图片体积过大,保险起见只能使用 Shortcuts 来下载图片,额外增加了一些动作。理想情况下仅需 3 个动作。
除了具备强大功能,Scriptable 还可以通过多种方式运行,进一步扩大的使用范围:
- 直接运行: 在 Scriptable 内,直接点击脚本名称来运行
- 通过 Shortcuts 运行: 在 Shortcuts 中调用和运行 Scriptable 脚本。与其他 iOS App 或系统功能结合,实现更复杂的自动化流程。
- 通过 URL Scheme 运行: 可以在支持 URL Scheme 的 App(如 Launch Center Pro)中被触发和运行。
- 定时运行。
但是,Scriptable 仅仅是一个桥梁, 背后的英雄是 JavaScript。上述所有的自动化任务都通过编写 JavaScript 代码来实现。
JavaScript 是一种具有广泛应用和强大功能的编程语言。起初设计为在浏览器环境中运行的脚本语言,随着技术的发展,JavaScript 的使用场景已经远远超出了浏览器。 从服务端(Node.js)到前端(Vue.js,React.js),再到移动应用(React Native)和桌面应用(Electron),都有 JavaScript 的身影。而在非浏览器环境中,JavaScript 也展现出了强大的能力,例如在 iOS 设备上,通过 Scriptable 应用,JavaScript 可以访问和操作系统级别的功能,实现高度自动化的任务。
接下来就以保存微博图文为例,学习使用 JavaScript 来更便捷、灵活的实现 Shortcuts 中的扒网页操作。
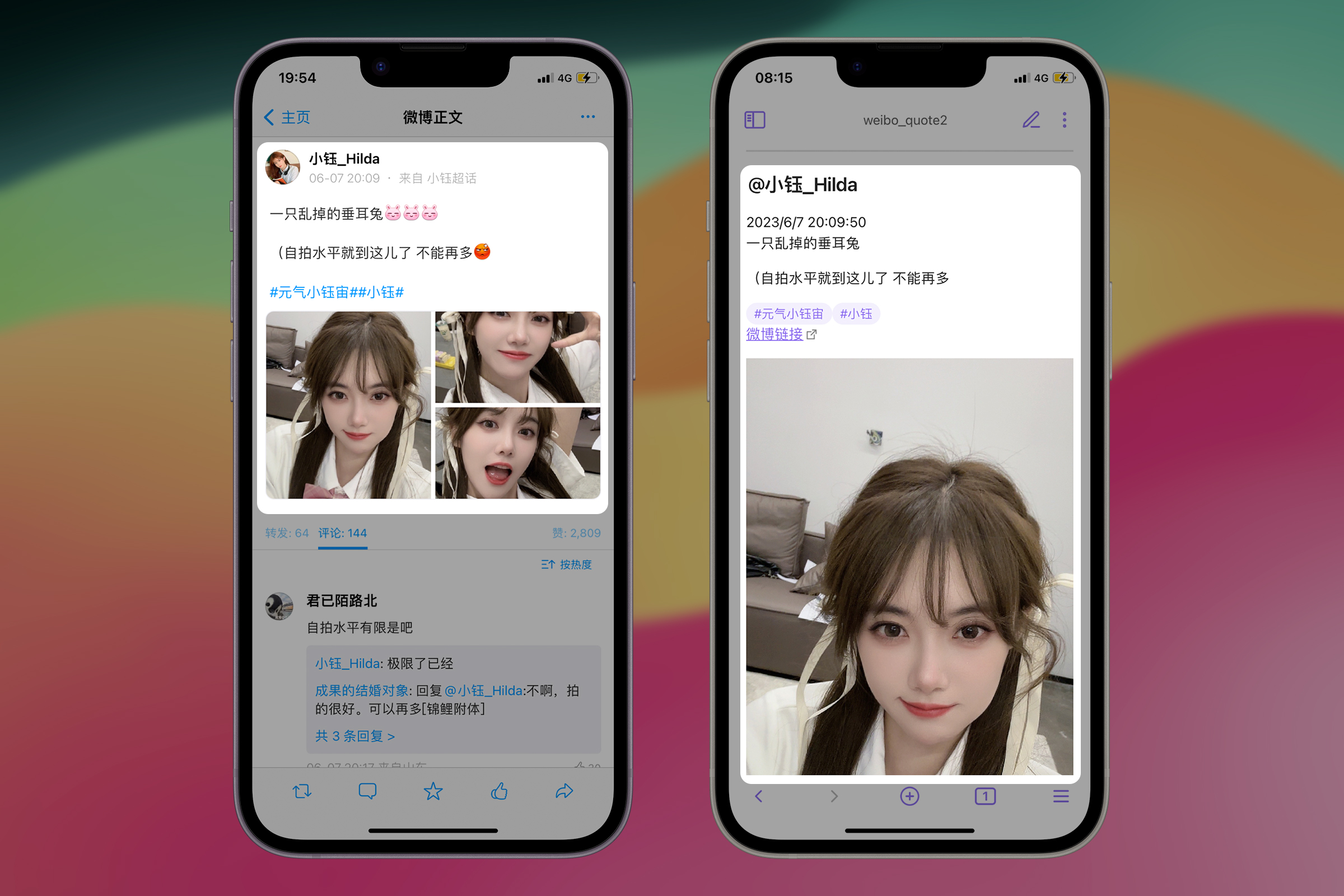
本文的主旨是借助已经熟悉的 Shortcuts 操作来理解 JavaScript 中的编程概念。给未尝试过 JavaScript 的自动化玩家提供一个认识和了解的机会。 在自动化领域 JavaScript 其实非常简单,掌握了一些核心概念后,几乎相当于书写英语语言。
根据知识难度,本文一共分为 2 个部分依次递进:
- 第一部分:保存带图文的微博
- 练习 1:去除 # 号标签
- 练习 2:修改代码中的 bug
- 第二部分:保存带转发图文的微博
- 附录:Scriptable 的功能与限制
不关心细节实现的话,按照下面步骤操作即可将微博图文保存到本地
- 下载对应的 Shortcuts 和 Scriptable 脚本
- 将 Scriptable 脚本放到 iCloud Drive 的 Scriptable 文件夹
- 修改 Shortcuts 中“追加到文本文件”和“存储文件”两个动作的保存位置
- 奇点微博客户端——分享——运行 Shortcuts
- 官方微博客户端——复制链接——运行 Shortcuts
- 使用桌面端浏览器微博:Scriptable 有 Mac 客户端,并且现在浏览器中的微博链接与奇点微博客户端分享的链接格式一致,只需调整一下流程便可通用。
- 安装 Mac 端的 Scriptable
- 点击要保存微博的右上角箭头——分享——点击复制地址
- 呼出 LaunchBar ——⌘ + V——Tab——运行保存奇点微博的 Shortcuts
提示:将保存的微博文本和图片文件夹放到 Obsidian 库中可以获得比较好的图文浏览体验
使用奇点微博客户端:Shortcuts、Scriptable 脚本 使用官方微博客户端:Shortcuts、Scriptable 脚本
第一部分:保存带图文的微博
将微博链接从客户端传递给 Scriptable
测试 Scriptable 和 Shortcuts 联动
先来了解一下 Scriptable 和 Shortcuts 是如何联动的。
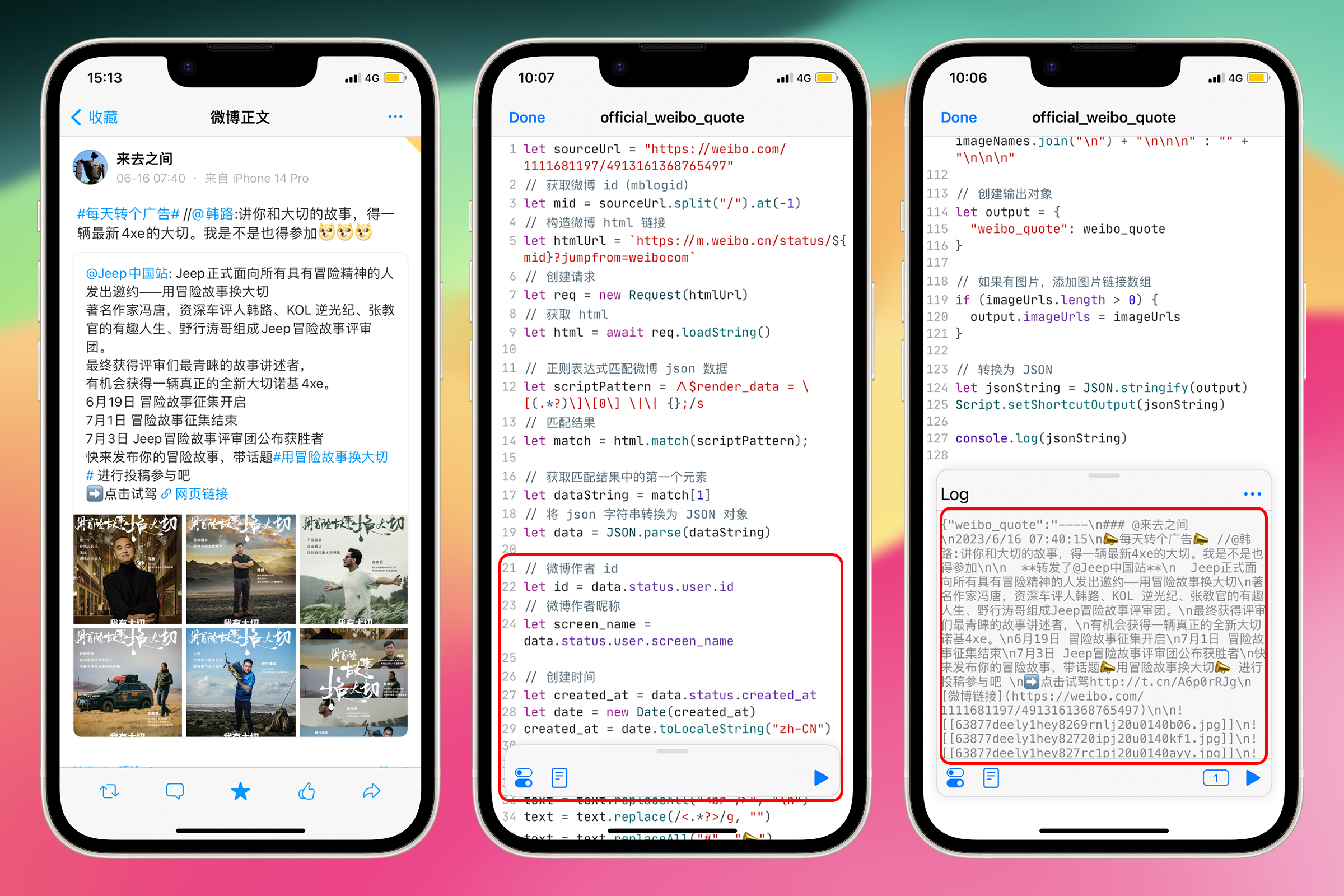
打开 Scriptable,点击右上角 + 号新建一个 JavaScript 脚本,点击上方的脚本名称重命名为“weibo_quote”,在脚本中输入 return args.shortcutParameter,点击 Done 保存。
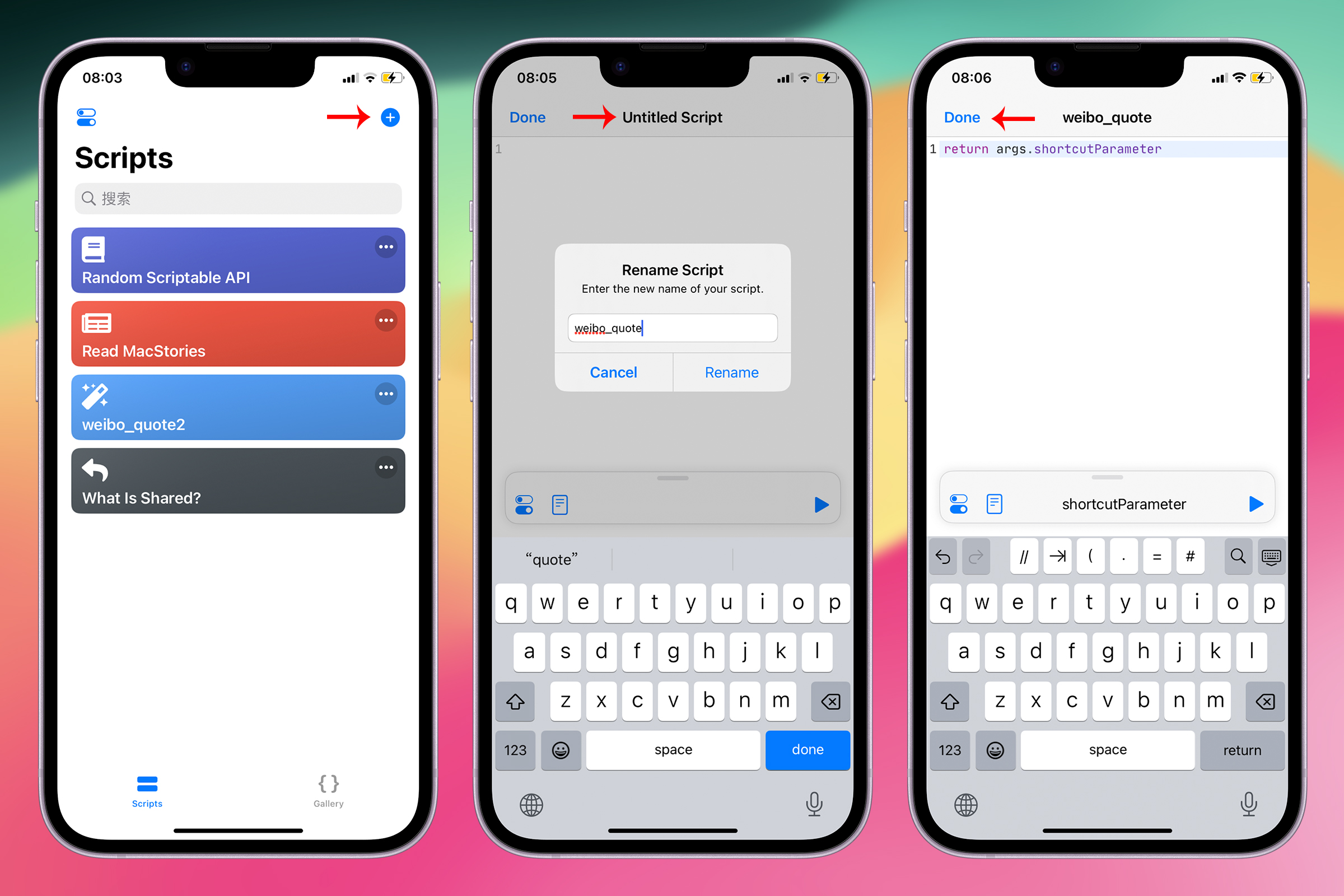
return args.shortcutParament 这行代码的含义是:
- return:表示返回。在 Scriptable 中,当一个脚本被 Shortcuts 调用时,使用
return关键字向 Shortcuts 输出一个值。 - args:表示从外部传递给 Scriptable 的对象。包含了从外部传递进来的内容(例如文字、文件、图像等)
- shortcutParameter: 这是
args对象的一个属性。表示从 Shortcuts 传递给脚本的内容。这个内容可以是文字、列表、字典或者文件。shortcutParameter只用来获取从 Shortcuts 中传递的内容。 - args 的其他属性:
args.plainText、args.images、args.urls、args.fileURLs,这些属性用来获取从 Share Sheet 或 Shortcuts 传递进来的内容。
背景知识——什么是对象?
在 JavaScript(以及许多其他编程语言)中,对象(Object)是一种复合的数据类型,它由一组键值对(key-value)组成。这些键值对在 JavaScript 中被称为属性(Property)。每个属性都有一个键(key)和一个对应的值(value)。通过对象的键去取值。
在刚才的例子中,args 是一个对象,包含了从外部传递给脚本的内容。shortcutParameter 是一个键,值为 Shortcuts 传递的内容。还有其他的键,例如从 Share Sheet 传递进来的内容。
一个直白的比喻是: args 是一个塑料袋,里面装了一些东西。
有了对象以后,可以使用 . 运算符来访问对象的属性。. 运算符后面应该是要访问的属性的名称。例如,args 对象有一个名为 shortcutParameter 的属性,那么可以使用 args. shortcutParameter 来访问这个属性。
一个直白的比喻是:使用 . 运算符从塑料袋里面取东西,想取什么就写什么名字。
**对应的 Shortcuts 操作:**接受 Share Sheet、从输入中获取词典、获取词典值、停止并输出
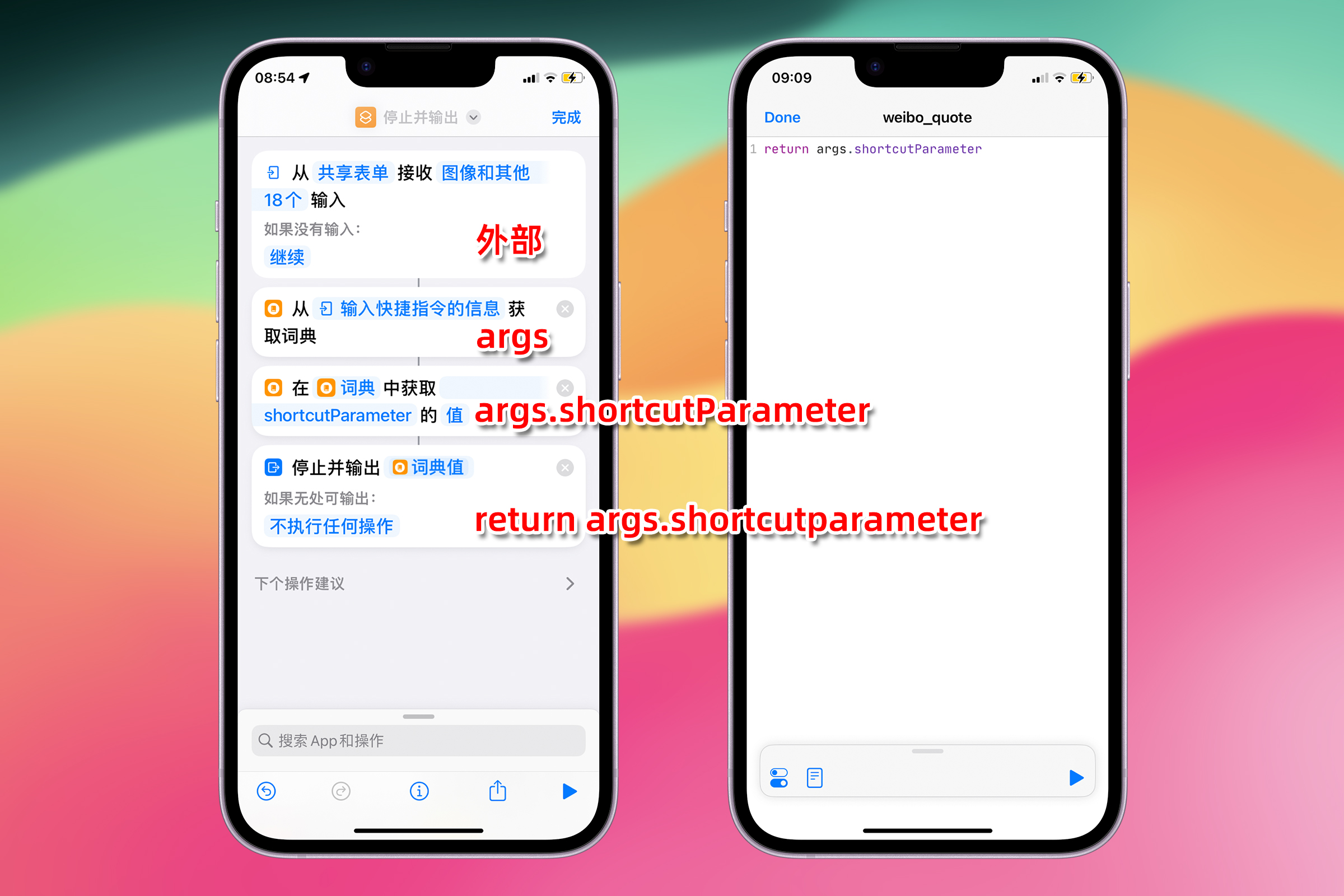
注意:截图左边的 Shortcuts 是一个对比示例,用来展示 JavaScript 代码对应的 Shortcuts 动作。
创建一个 Shortcuts,添加一个“文本”动作,输入 “Hello”,加上 Scriptable 的 Run Script 动作,Shortcuts 会自动为我们选择上一步的文本作为参数(Parameter),点击 Script,选择刚才创建的“weibo_quote”脚本,关闭 Run Script 选项中的“运行时显示”,运行一下看看。
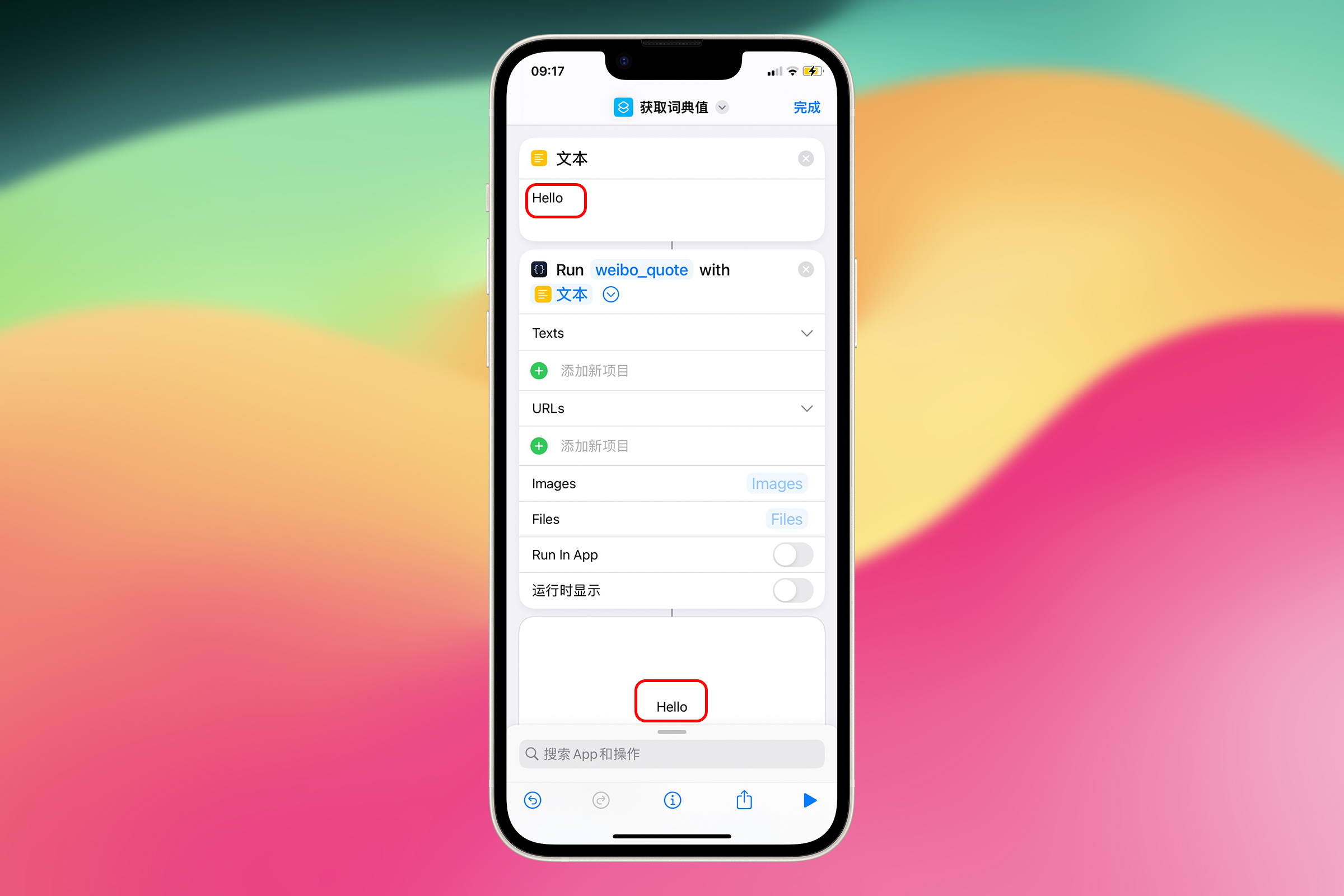
成功将 Hello 输入到 Scriptable,然后输出到 Shortcuts,高速公路已经通车。
这里补充一些关于 Run Script 动作的细节知识,可略过:
- Run Script 动作中 Texts、URLs、Images、Files 也可以用来传递内容到 Scriptable 中,但获取这些内容需要使用对应的
args.plainText、args.urls、args.images、args.fileURLs,不能使用args.shortcutParameter。args.shortcutParameter只能用来获取 Run Script 动作中 Parameter 中放置的内容。 args.plainText、args.urls可以用来传递多个值,这些值将作为数组发送给 Scriptable,可以直接在 Scriptable 中当作数组来使用。- 传递较大的图像时,脚本可能会因为内存限制而失败。在这种情况下应该启用“Run in App”
- 使用 JavaScript 的
return关键字或Script.setShortcutOutput()来输出一个值。如果你没有输出值,可以添加Script.complete()来表示脚本已经运行完毕。也就是说,必须通过输出值或表示脚本运行完毕来通知 Shortcuts 继续运行流程,否则会报错。
Shortcuts 和 Scriptable 联动测试告一段落,接下来进行实际应用,将微博链接从客户端发送到 Scriptable 中。
从客户端获取微博链接——JavaScript 数组
我日常在用的是奇点微博客户端(不知道什么原因目前只能从国区以外的地区下载),文末有使用官方客户端的方案)。
先创建一个名为“摘微博-JS” 的 Shortcuts,将类似 https://weibo.com/1779654914/N4erNsxv2 这样的微博链接通过 Share Sheet 分享到 Shortcuts 中。
可能是因为奇点 App 的原因,分享出来的链接含有其他内容,必须通过”文本“动作将其转为文本,才可以填写到 Run Script 的 Parameter,否则会报错。
在 Run Scriptable 动作下方接上一个“显示结果”动作,方便观察输出。
在 “weibo_quote” 脚本中写上如下 JavaScript 代码
let sourceUrl = args.shortcutParameter;
Script.setShortcutOutput(sourceUrl);
第 1 行代码:从 args 对象中获取 shortcutParameter 属性,即通过 Shortcuts 发送给 Scriptable 的 url。
第 2 行代码:将获取到的 url,输出到 Shortcuts 中
获得内容后要保存,只需在前面加上 let 变量名 = ,例如let id = let sourceUrl = args. shortcutParameter 意思是创建一个新的变量 sourceUrl 保存等号右边的值,即从 Shortcuts 传递来的 url。
在英语中,let 是让步、允许或声明的意思,这种含义在编程语境下可以很自然地引申为声明或创建变量。这使得 JavaScript 的语法更直观、易懂。在之后在脚本中,可以通过 souceUrl 这个变量来访问微博链接。
分享一条微博试一下,成功将链接发送到 Scriptable 中,并输出到 Shortcuts 中显示。
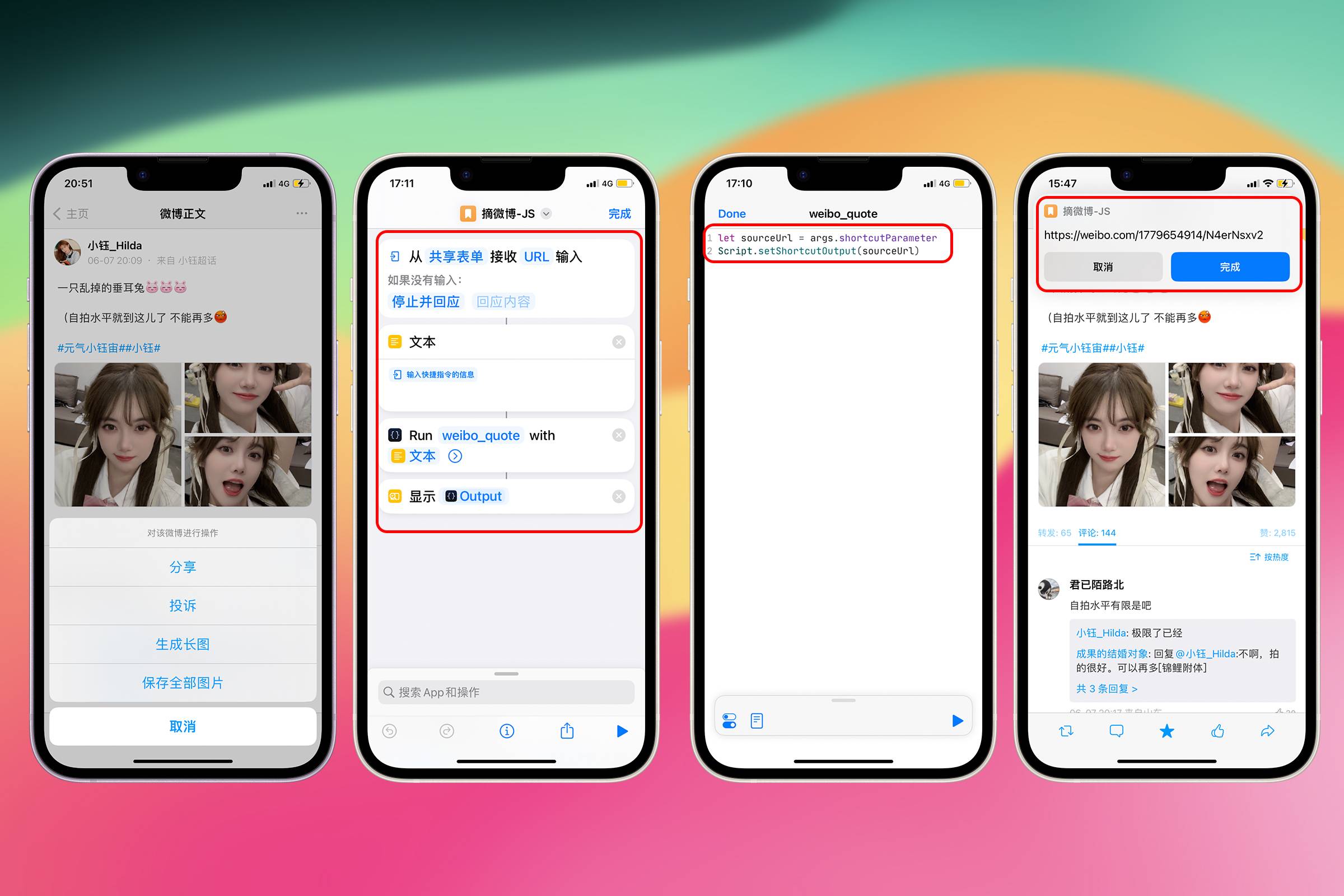
这个链接的含义是 https://weibo.com/微博作者 id/微博内容 id。
获取包含微博内容的 JSON
有了链接,就可以根据链接去找 JSON 了。 这里有一个小技巧,一般扒网页时选择从手机端网页入手。手机端的网页通常会更简单,更容易解析和提取需要的信息。 打开 Chrome 浏览器,随便打开一个网页,右键——检查,点击箭头位置,修改为手机端浏览模式。
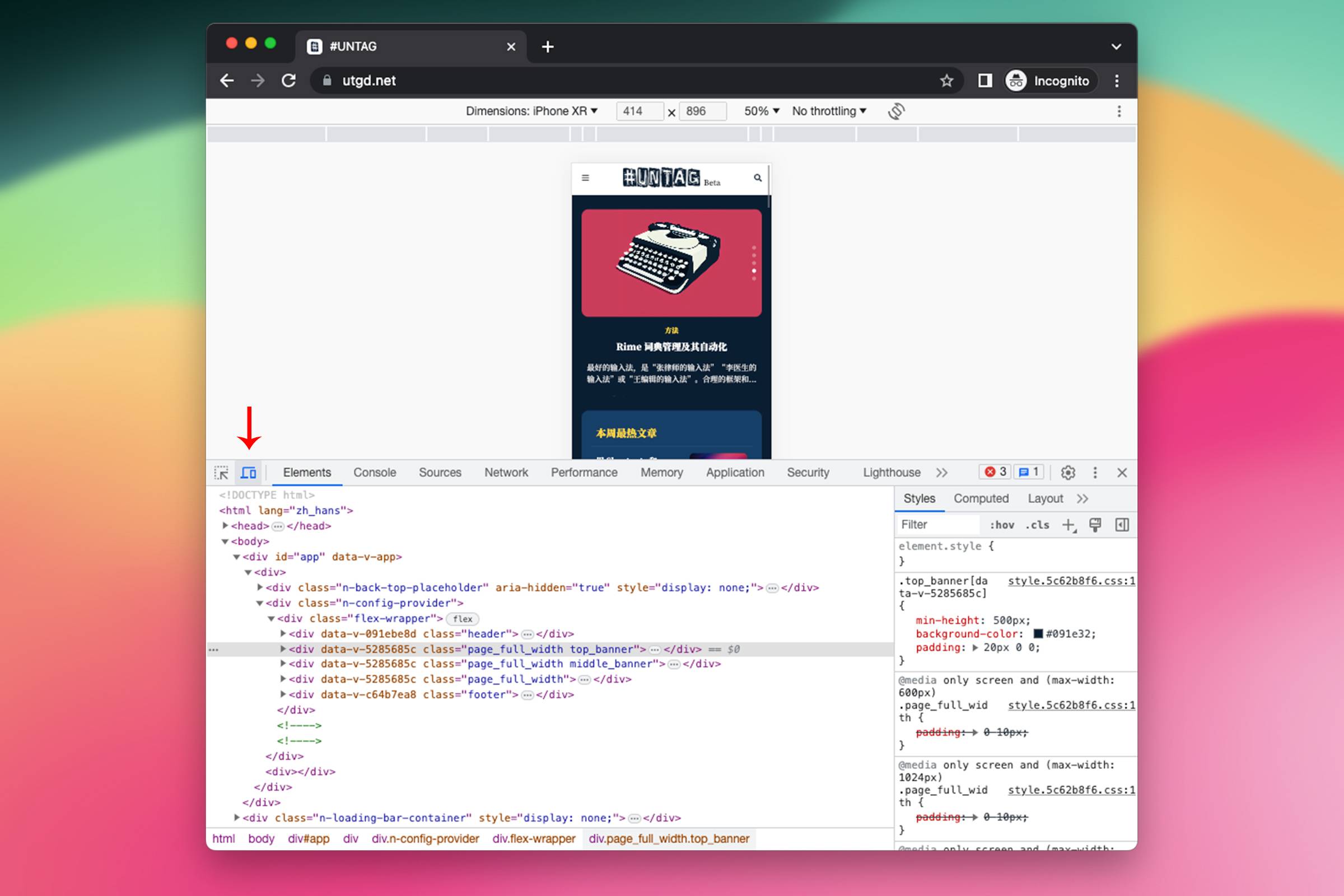
在这个标签页内,访问刚才获取的到的微博地址 https://weibo.com/1779654914/N4erNsxv2,
在浏览器开发者工具中,点击 Network 面板。在这个面板下,可以监控和查看页面加载和运行过程中的所有网络请求。
选中 Fetch/XHR 过滤器,这样可以只看到通过 Fetch API 或 XMLHttpRequest 发出的请求,这些请求通常用于在后台获取数据,很可能会包含需要的 JSON 数据。
逐一检查 Name 列中的请求条目。选择一个请求后,在右侧的 Response 选项卡下,可以看到该请求的响应数据。
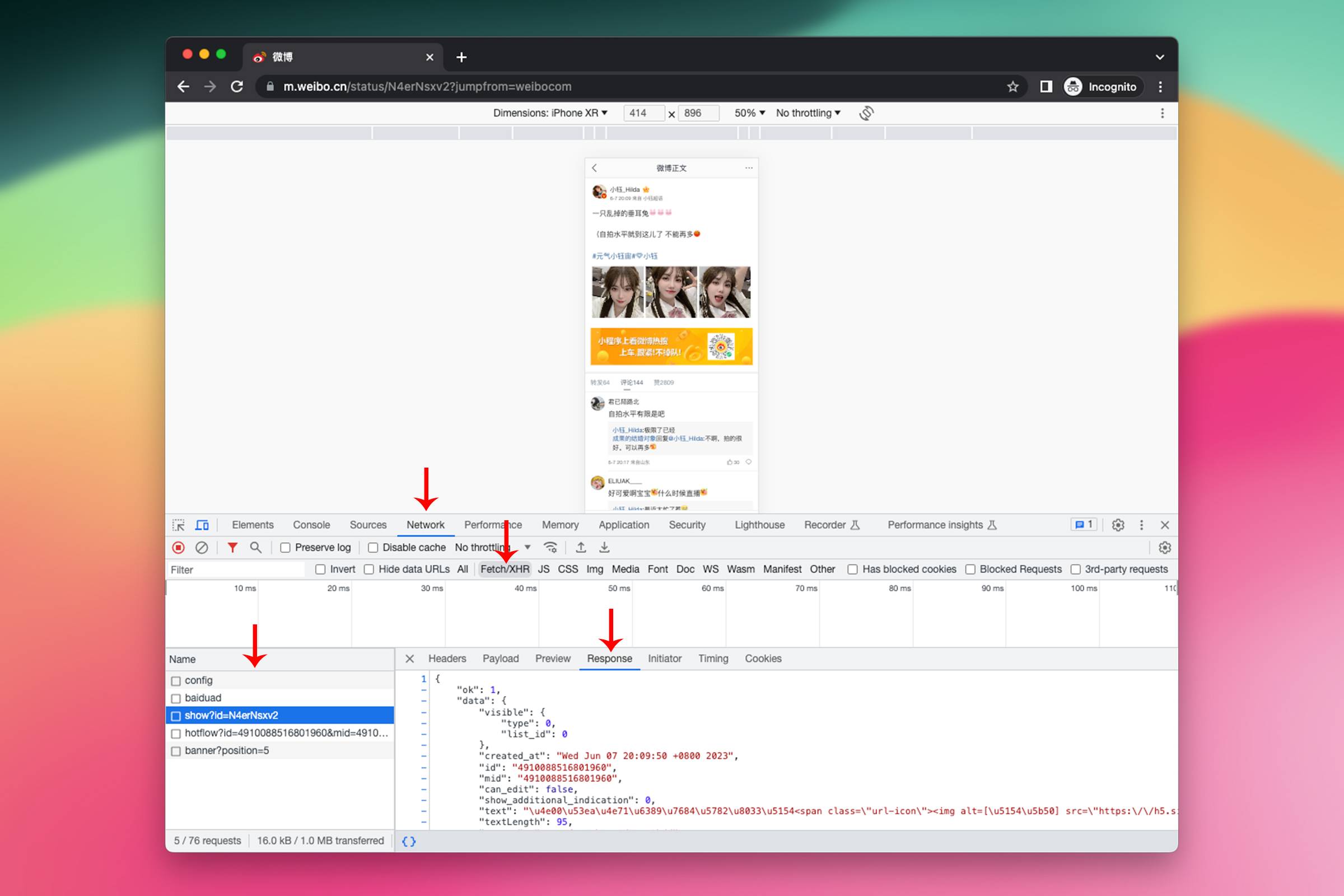
这一步是为了查看所有的网络请求,找到能够返回 JSON 的那个请求地址。现在先暂停一下寻找 JSON 请求的过程,补充一些背景知识能清楚明白做这些操作的意义。
背景知识——浏览网页时发生了什么?
早期的网页设计中,点击一个链接时,浏览器会发送一个请求到服务器,服务器返回一个新的 HTML 页面,这个页面包含了请求的所有信息。这就意味着每次用户交互都需要加载一个新的页面,这可能会导致网站响应缓慢。 为了改善这种情况,网站开发开始使用 AJAX 技术。AJAX 是 Asynchronous JavaScript and XML(异步 JavaScript 和 XML)的缩写,一种用于创建快速动态网页的技术:
- 用户在浏览器进行某项操作(如点击链接)。
- 这项操作会触发网页内的 JavaScript 脚本,通过 JavaScript 创建一个请求对象(XMLHttpRequest)(这也是前文点击 Fetch/XHR 过滤器的原因)并向服务器发送 HTTP 请求。
- 服务器处理这个请求,然后将数据(通常是 XML(用于储存和传输数据的标记语言) 或 JSON 格式)发送回浏览器。
- 当浏览器接收到服务器的响应时,网页内的 JavaScript 可以读取这些数据并更新部分网页,而无需重新加载整个页面。 通过使用 AJAZ 技术可以使网页看起来更快、更流畅,因为只有必要的部分被更新。这也意味着如果能获得服务器发回的 JSON,就获得了需要的数据,而不需要去分析一整个 HTML 页面。
找到发起 JSON 请求的链接——JavaScript 字符串处理
顺着左侧的列表一个个点开查看,直到找到符合我们要求的 JSON 内容后,点击 Headers——HTTP 协议中请求或响应的一部分,它们提供了关于请求或响应的元信息,诸如请求的 URL、请求方法(如 GET、POST)、响应状态码、内容类型(Content-Type)、缓存控制(Cache-Control)。
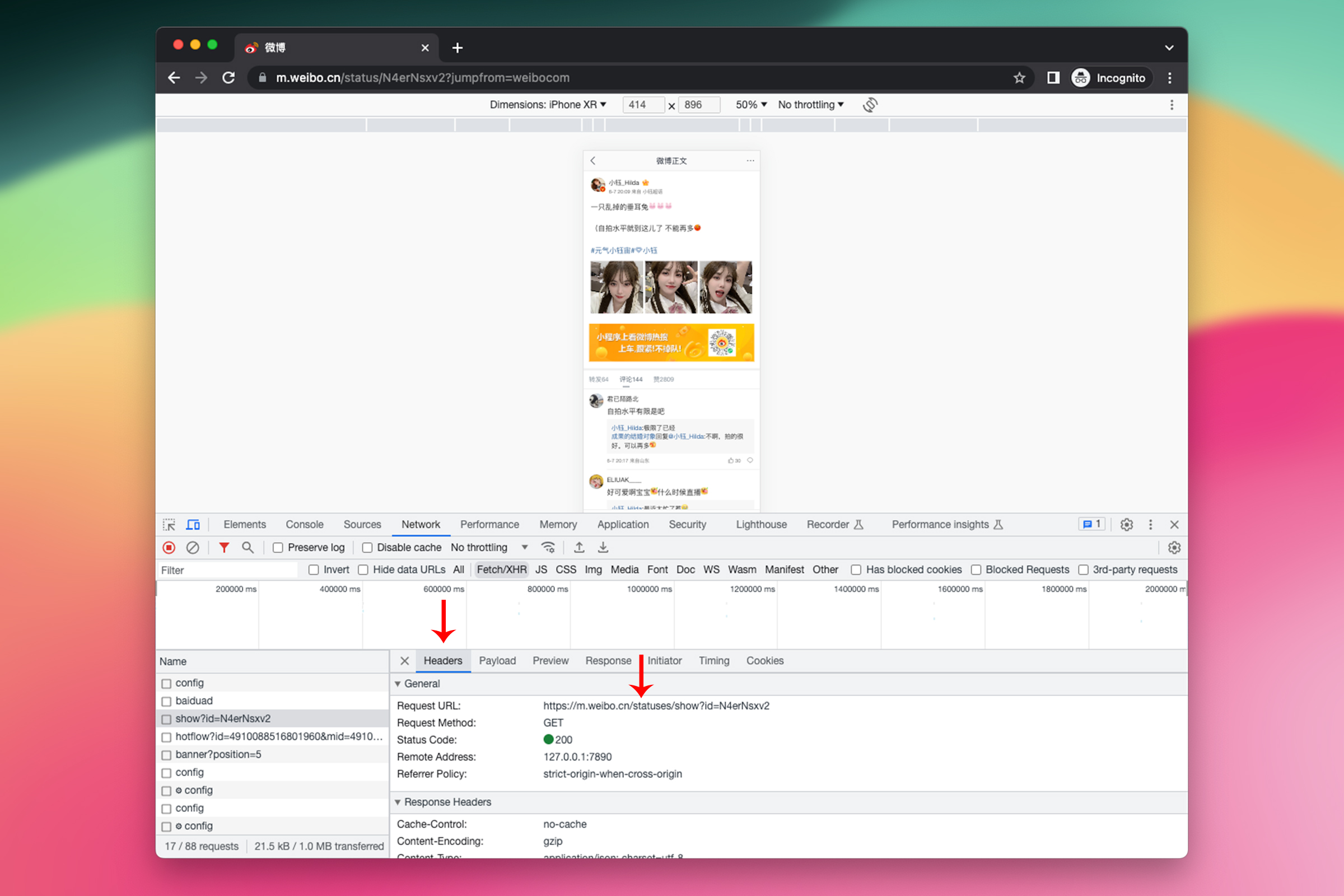
可以看到 Request URL(请求链接)是
https://m.weibo.cn/statuses/show?id=N4erNsxv2
与我们最初的链接
https://weibo.com/1779654914/N4erNsxv2
进行对比,发现可以自己拼出这个链接
let bid = sourceUrl.split("/").at(-1);
let jsonUrl = `https://m.weibo.cn/statuses/show?id=${bid}`;
第 1 行代码:使用 \ 分割 sourceUrl,然后获取最后 1 个项目 bid(blogid),即 N4erNsxv2
第 2 行代码:使用 JavaScript 中的模板字符串语法,${bid} 是动态的部分,会根据实际情况替换为具体的值。使用反引号``来包围要插入内容的字符串,使用 ${}来插入内容。
对应的 Shortcuts 操作:“拆分文本”、“从列表中获取项目”、“文本”拼接字符串
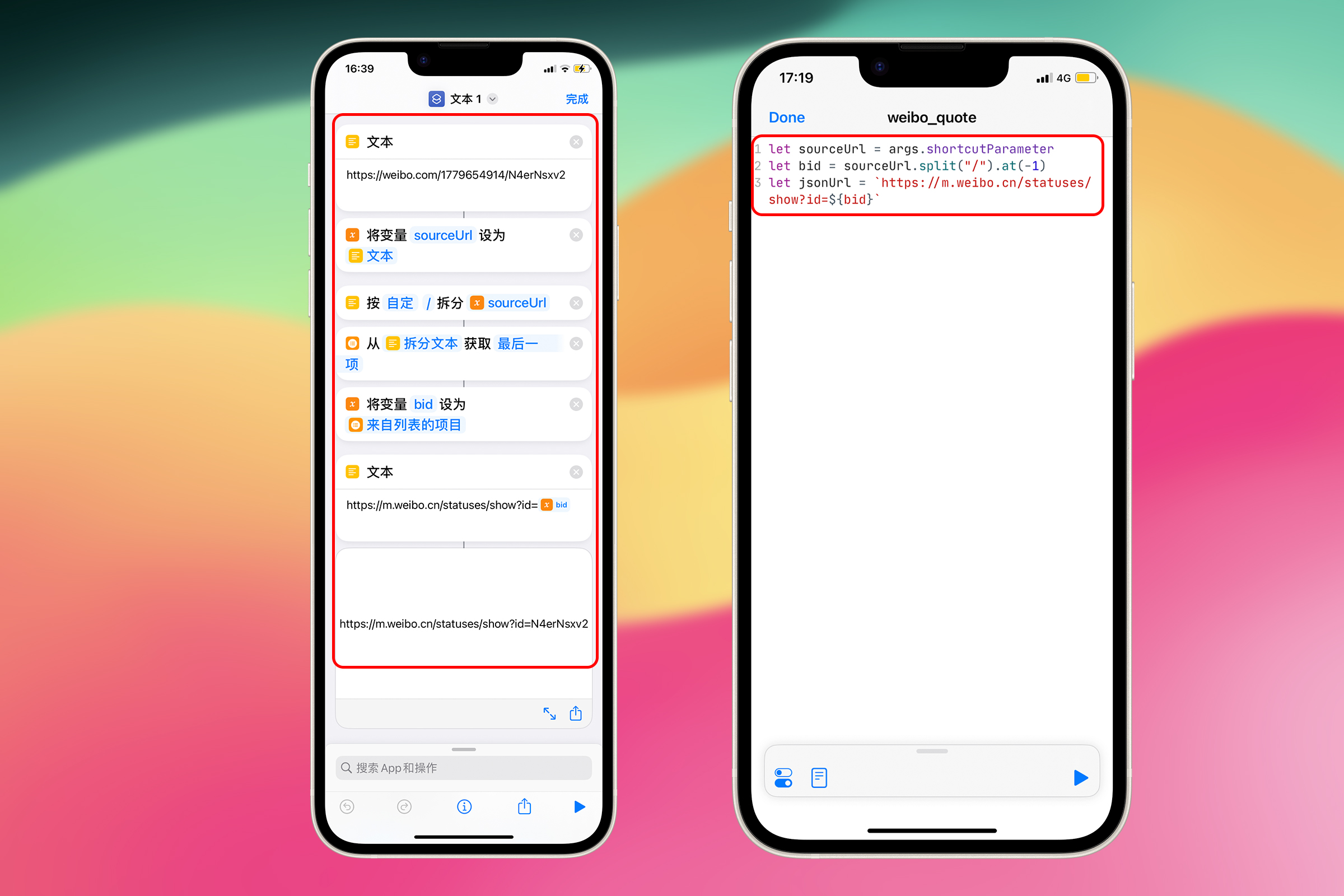
有了链接之后就可以访问这个链接来获得服务器响应的 JSON
let req = new Request(jsonUrl);
let json = await req.loadJSON();
第 1 行代码:使用 Request 对象创建了一个网络请求,jsonUrl 是想要请求的 URL
第 2 行代码:发送了之前创建的网络请求,并等待响应。loadJSON 表示我们期望从服务器收到的响应是 JSON 格式的数据。
对应的 Shortcuts 操作:“获取 URL 内容”
分享一条微博试一下,成功获取到 JSON
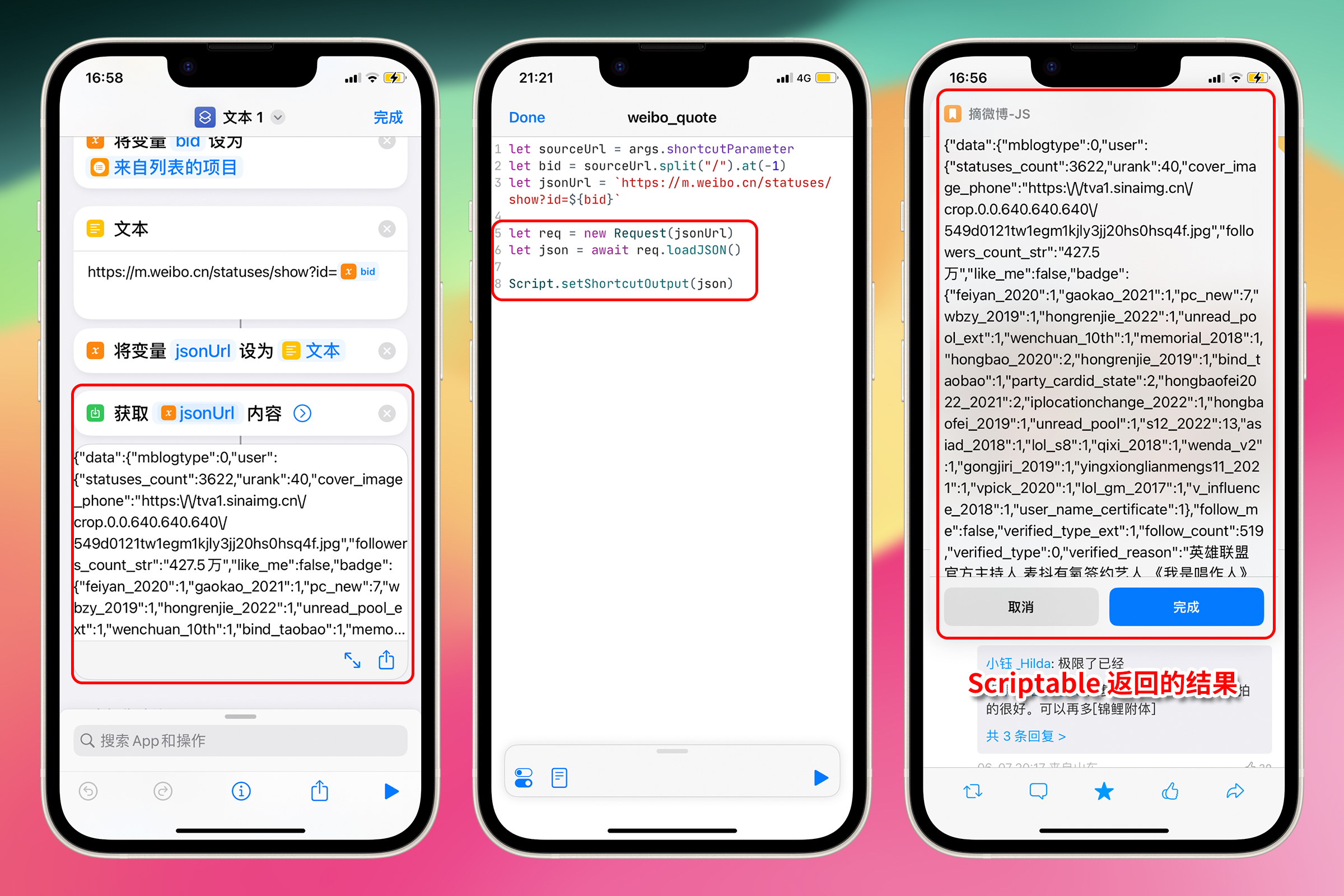
这里 JSON 内容的显示顺序可能与浏览器开发者工具中看到的不一致。这是因为 JSON 其本质是一个键值对的集合。键值对的顺序本身是不固定的。同一个 JSON 对象,其键值对的顺序在不同的环境或者不同的解析工具中可能会有所不同。
背景知识——浏览器何时产生 JSON 请求?
网页的内容是由服务器返回的 HTML、CSS 和 JavaScript 代码构成的,这也是构成大部分网页的三大核心技术。
- HTML 用于描述网页内容的标记语言,如段落、标题、链接等。
- CSS 用于描述 HTML 内容的表现形式,例如字体、颜色、间距、布局等。
- JavaScript 用于读取和修改 HTML 内容,例如改变 CSS 样式,处理用户事件(如点击、滑动等),发送网络请求(如前文 AJAX)。 可以这样理解它们的作用与关系:HTML 是网页的骨架,定义了页面上的内容;CSS 是网页的皮肤,定义了这些内容的样式和排列;JavaScript 则是网页的神经系统,它让页面动起来,响应用户的操作。
当访问 https://weibo.com/1779654914/N4erNsxv2 这个网页时,会发生以下步骤:
- DNS 解析:浏览器将 "weibo.com" 这个域名解析成对应的 IP 地址。
- 发起 HTTP 请求:浏览器向该 IP 地址发起 HTTP GET 请求,请求路径是
/1779654914/N4erNsxv2。- 在 URL
https://weibo.com/1779654914/N4erNsxv2中:https://是协议,表示这是一个使用 HTTPS(HTTP Secure)协议的 URL。- "weibo.com" 是域名,表示这个 URL 的服务器地址。
/1779654914/N4erNsxv2是路径,表示在服务器上的资源位置。- 路径用于标识服务器上的特定资源。
/1779654914/N4erNsxv2表示在微博服务器上的一个特定微博。
- 路径用于标识服务器上的特定资源。
- 在 URL
- 服务器处理请求:服务器接收到请求后,会解析请求路径,找到对应的资源或执行对应的逻辑,然后返回一个 HTTP 响应。这个响应通常包括一个状态码(Status)(如 200 表示成功),响应头(Header)(包括一些元数据),以及响应体(Response)(对于
https://weibo.com/1779654914/N4erNsxv2这个 URL,响应体通常是一个 HTML 文档)。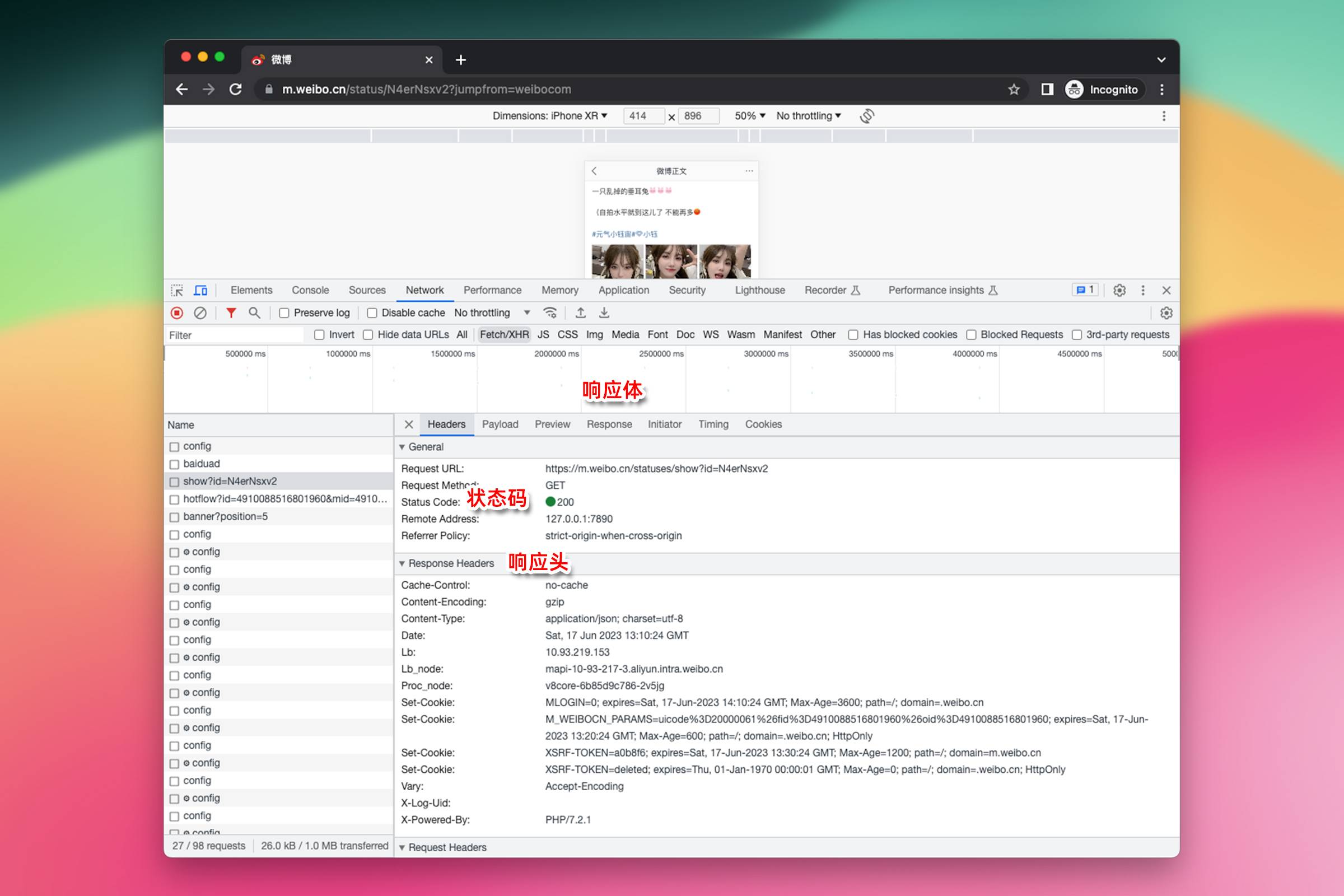
服务器响应 URL 请求 - 浏览器接收并处理响应:浏览器接收到响应后,会根据响应头的信息解析响应体,将 HTML 文档渲染成可视化的网页。
- 一个 HTTP 响应由两部分组成:响应头(Headers)和响应体(Body)。
- 响应头:包含了关于响应的元信息,比如状态码(表示请求是成功还是失败),内容类型(表示响应体的格式,如 HTML、JSON、图像等),编码方式、设置的 cookie、缓存策略等等。
- 响应体:则是实际返回的数据内容。这个内容的格式和解析方式通常由响应头中的“Content-Type”字段指定。比如,如果“Content-Type”是“text/html”,那么响应体就应该是 HTML 文档,浏览器会作为 HTML 解析和渲染。如果“Content-Type”是“application/json”,那么响应体应该是 JSON 格式的文本,浏览器会将其作为 JSON 数据来处理。

服务器响应 URL 请求 2
- 一个 HTTP 响应由两部分组成:响应头(Headers)和响应体(Body)。
- 执行 JavaScript:在返回的 HTML 文档中可能包含了一些 JavaScript 脚本。(如截图所示,
<script>标签中的内容就是 JavaScript 脚本)当浏览器解析到这些脚本时,会执行它们。这些脚本可能会做一些改变 HTML 内容、处理用户交互、或者发送更多的网络请求等操作。在我们当前的例子中,有一些 JavaScript 脚本会发送一个到https://m.weibo.cn/statuses/show?id=N4erNsxv2的 AJAX 请求来获取 JSON 数据。
HTML 中的 JavaScript 代码 - 更多的 HTTP 请求:一般情况下,一个网页不只包含 HTML,还会包含 CSS、JavaScript、图片等资源,这些资源需要通过更多的 HTTP 请求来获取。所以在网页被完全渲染出来之前,浏览器可能会发送很多的 HTTP 请求来获取其他资源。
简而言之,访问 https://weibo.com/1779654914/N4erNsxv2 后,浏览器先从服务器获得了一些内容,解析并渲染 HTML 页面,执行 HTML 页面上的 JavaScript 代码;这部分代码中包含发送 https://m.weibo.cn/statuses/show?id=N4erNsxv2 请求。
服务器响应这个请求;返回状态码 200、内容类型 application/json、响应体 Response 包含微博的内容的 JSON 格式的文本。浏览器接受到这个响应,根据 JSON 内容将微博信息展示到网页上。
因此,根据 JSON 扒网页就是找到能够获取 JSON 的请求,用 Shortcuts 去访问,然后从返回的 JSON 文本中获得需要的数据。
获取微博作者、微博创建时间、微博内容
浏览器中的 Unicode 编码
从浏览器开发者工具中复制服务器返回的 JSON,打开 json.cn,对 JSON 进行格式化,更方便我们阅读。
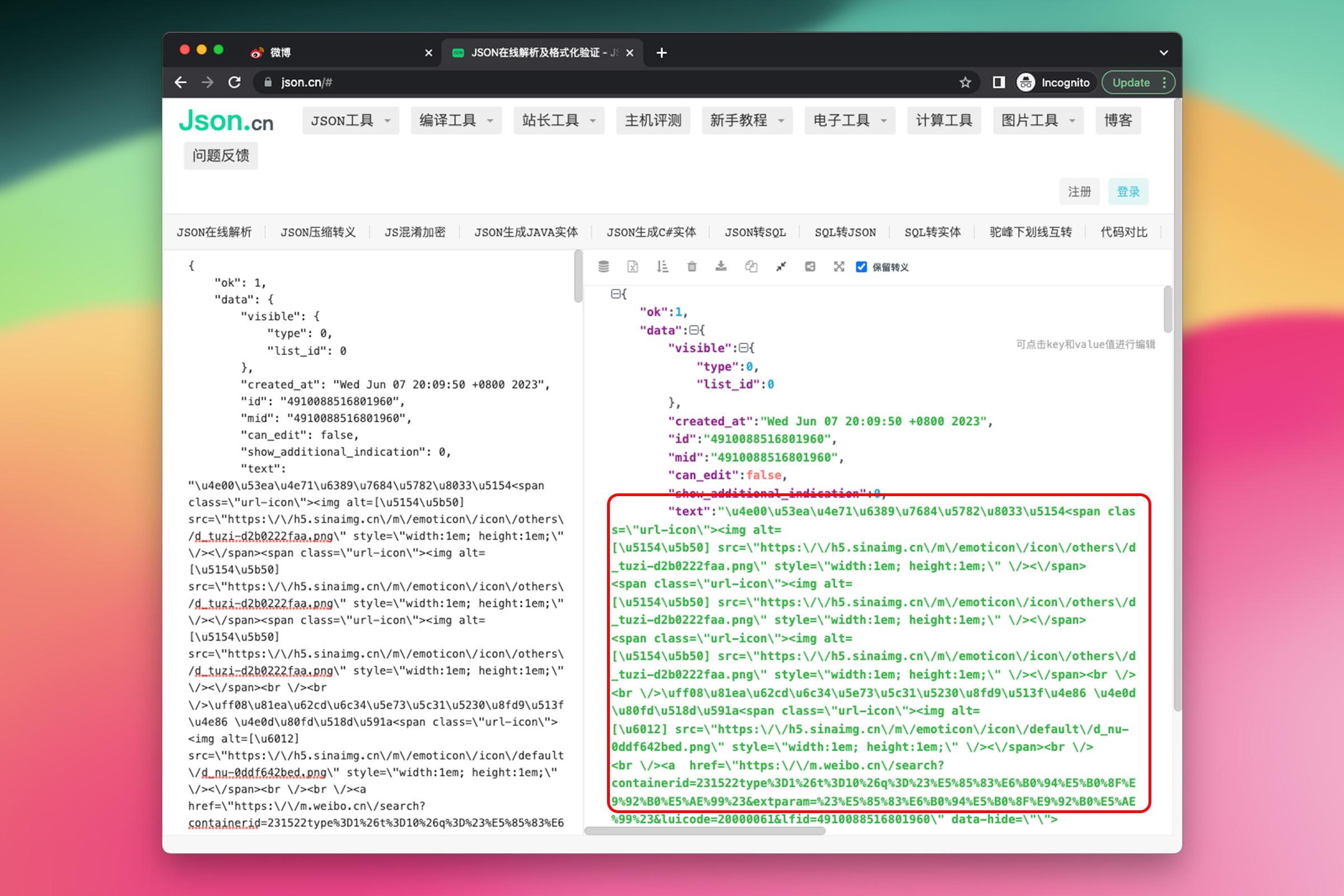
观察格式化后的 JSON,感觉这个 text 可能是我们的需要的内容,但是都是 \u6389 之类的乱码。这是因为数据被编码成了 Unicode Escape 形式。
背景知识——Unicode 编码
Unicode 是一种编码标准,定义了所有的字符和符号,无论是西方的字母,还是中国的文字,包括各种符号、表情符号,它们都在 Unicode 中有唯一对应的一个码点(code point)。可以用来在不同的系统和平台上表示各种语言的字符。
当字符被转换为 Unicode Escape 形式时,这个字符会被替换为它的 Unicode 码点表示,通常是一个以 \u 开头,后面跟着四个十六进制数字的形式。比如,中文字符 "我" 的 Unicode 码点是 6211,所以在 Unicode Escape 形式中,它会被表示为 \u6211。
这样可以确保无论字符是在何种环境下(例如不同的操作系统或不同的语言环境)都可以被正确地理解和显示。
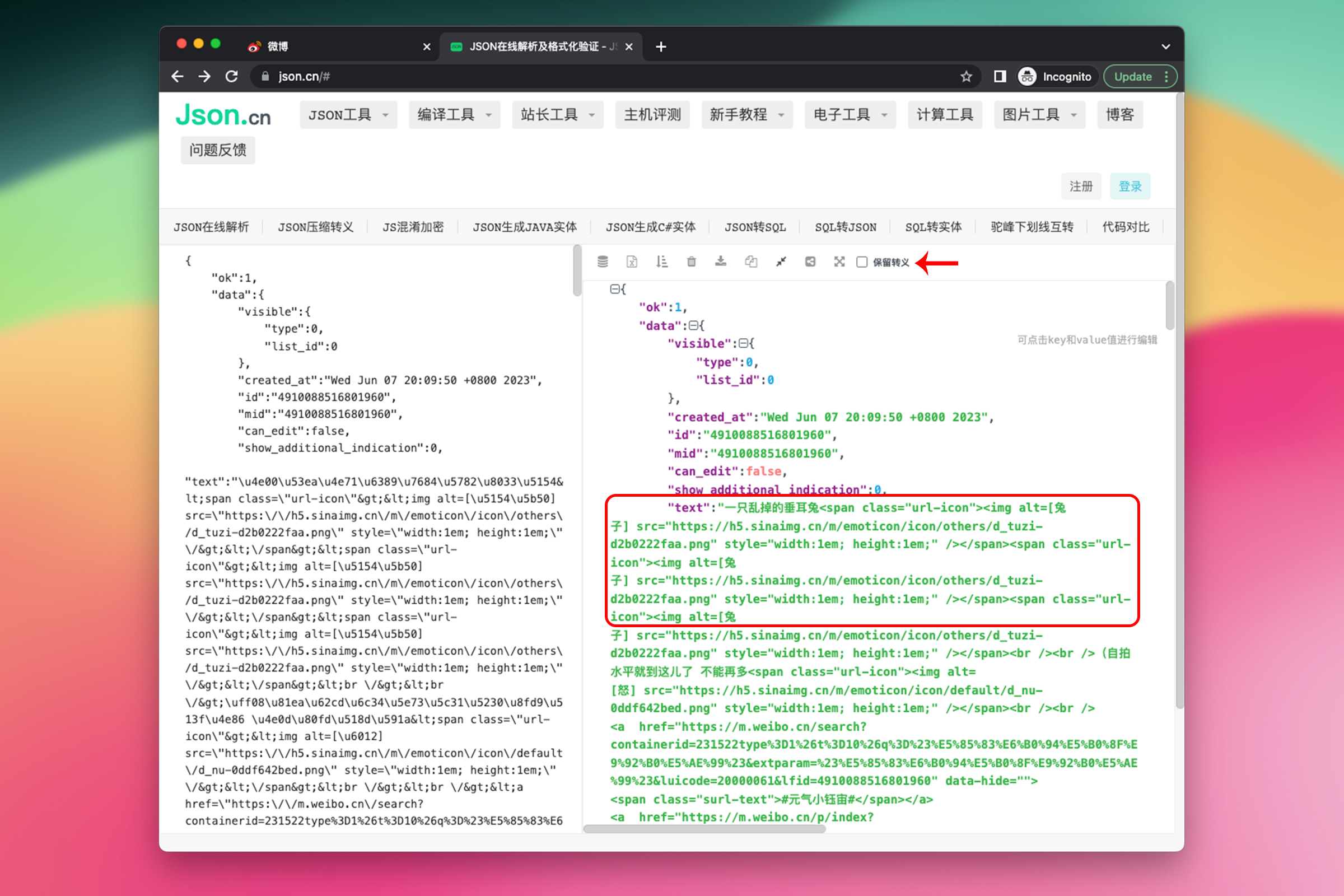
因此,字符串 \u4e00\u53ea\u4e71\u6389\u7684\u5782\u8033\u5154 从码点转换为中文字符就是 一只乱掉的垂耳兔。通常我们并不需要做额外的转换,浏览器或者 JavaScript 会自动将其转换为对应的字符显示。
json.cn 为我们提供了转换工具,取消勾选“保留转义”即可看到原本的中文字符。
背景知识——什么是 JSON?
JSON,即 JavaScript Object Notation(JavaScript 对象表示法),是一种轻量级数据交换格式,以文本为基础,用来存储和交换简单结构的数据。
在 JSON 中,数据结构以对象和数组的形式表示。对象由键值对组成,键是字符串,值可以是字符串、数字、对象、数组、布尔值。对象使用大括号{} 表示,而数组用中括号 [] 表示。
JSON 作为一种数据格式,易于读写、支持嵌套的数据结构、兼容性好、轻量级使得它成为了数据交换的首选格式。
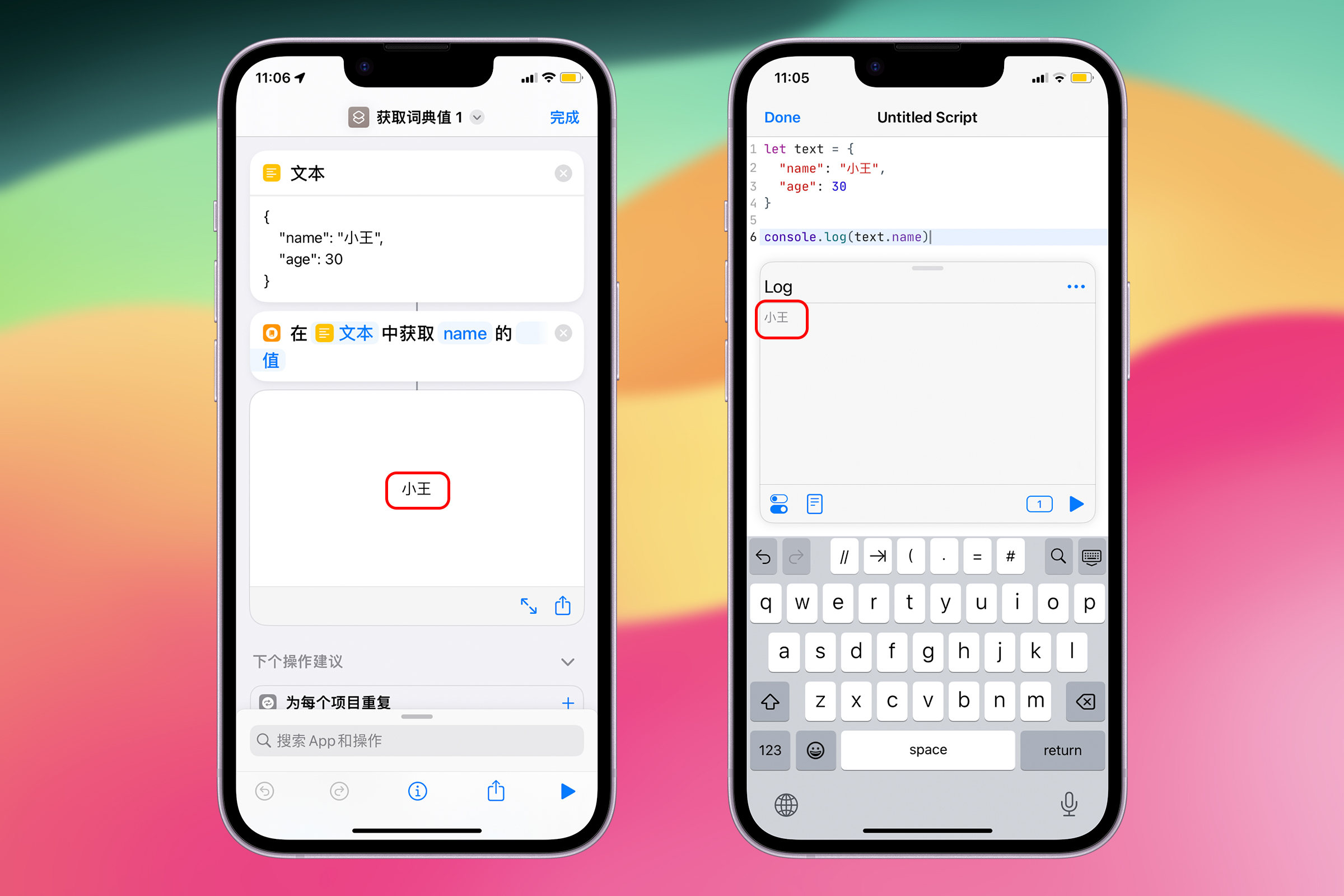
例如,一个简单的 JSON 对象可以如下所示:
{
"name": "小王",
"age": 30
}
在 JavaScript 中只需要 text.name 即可获取学生的名字:小王。
在 Shortcuts 中则通过“获取字典值”动作来处理 JSON 数据,在 文本 中获取 name 键的值。
获取微博作者 id——JavaScript JSON 取值
明白了 JSON 的构造和使用之后,首先来获取微博作者 id。
观察格式化后的 JSON,可以看到在 {data: {user: {id: 1779654914}}}这个位置,层级大概是 JSON 对象 —> data —> user —> id。联系前文所述的 JSON 使用方法,我们只要使用 data.user.id 就能获取到微博作者 id。
接着往下找,data.user.screen_name 就能获得微博显示昵称。
在脚本中写下如下 JavaScript 代码
let id = json.data.user.id;
let screen_name = json.data.user.screen_name;
**对应的 Shortcuts 操作:**获取词典值
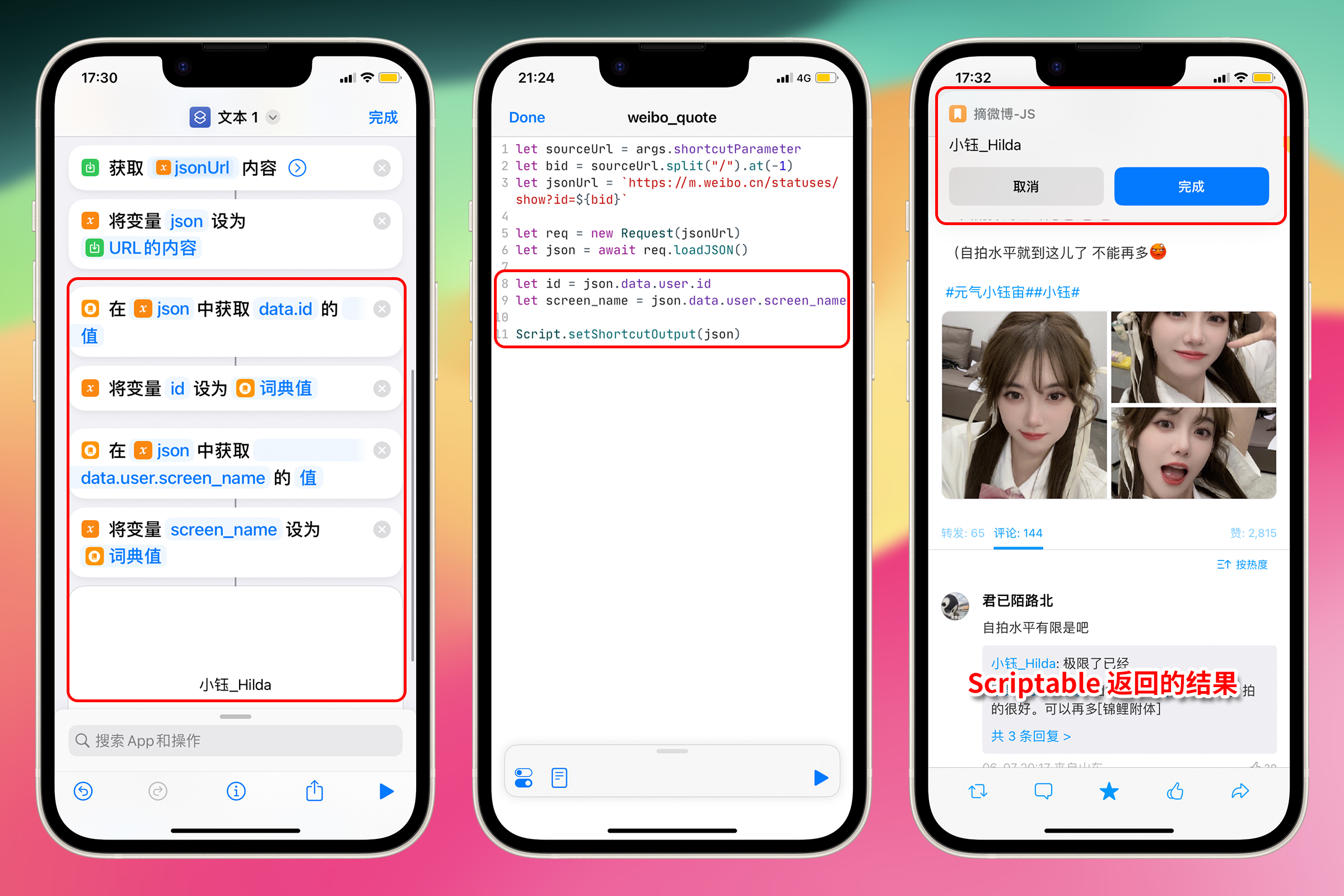
注:左边的截图仅用来展示 JavaScript 代码对应的 Shortcuts 动作,不能实际运行。除非特殊说明,左边截图均为对比示例,不再赘述。
你还可以加上注释:
// 微博作者id
let id = args.shortcutParameter.data.user.id;
// 微博作者昵称
let screen_name = args.shortcutParameter.data.user.screen_name;
**对应的 Shortcuts 操作:**注释
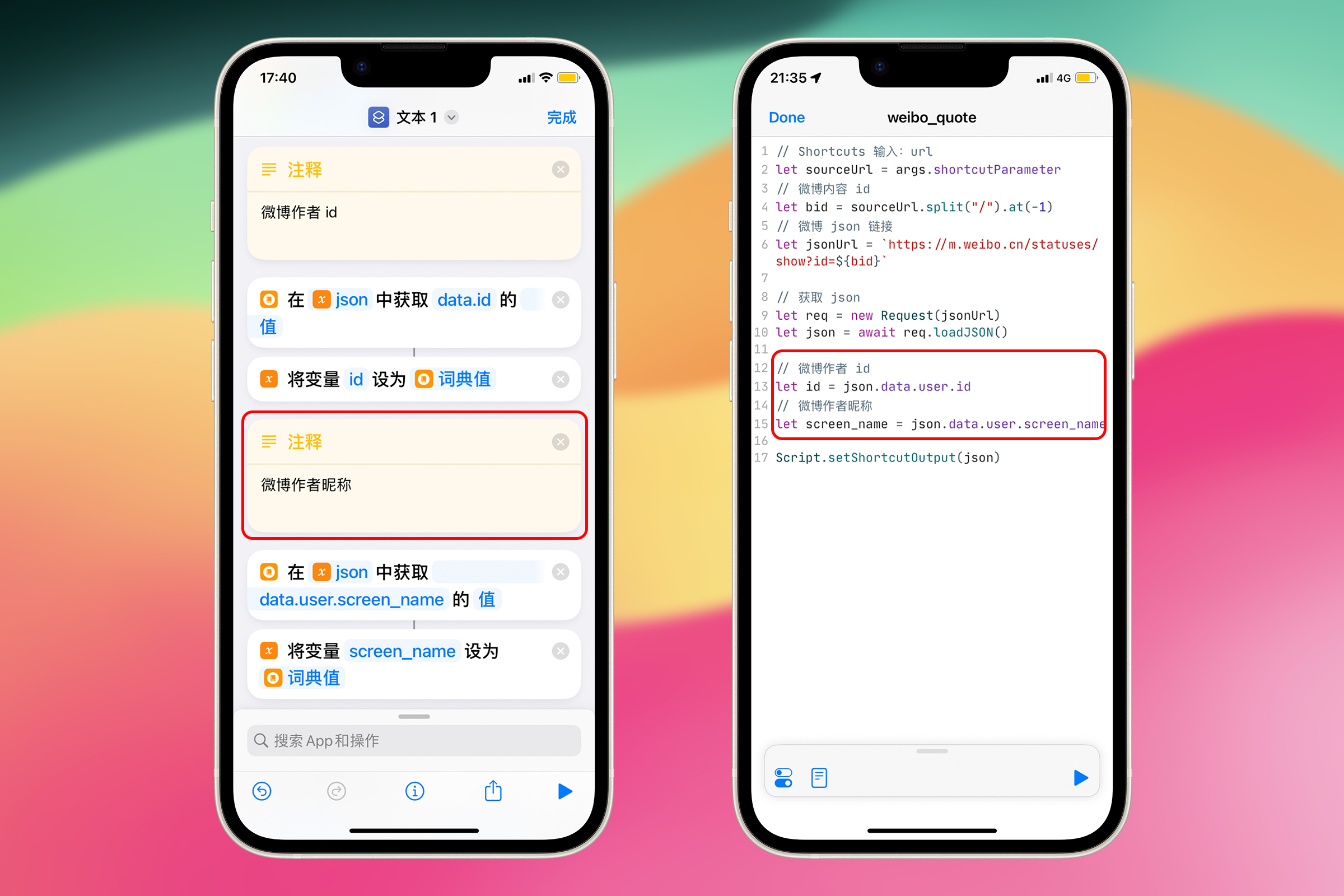
获取微博创建时间——JavaScript 调用对象的方法
接下来上一点难度,获取微博创建时间
// 创建时间
let created_at = json.data.created_at;
let date = new Date(created_at);
created_at = date.toLocaleString("zh-CN");
第 1 行代码:从 JSON 中获取发布时间字符串——“Wed Jun 07 20:09:50 +0800 2023”,这个对阅读不太友好,需要将它转换为更易读的格式。
第 2 行代码:使用 new 关键字创建了一个新的 JavaScript 日期对象 date,并提供日期参数 created_at,该 date 对象代表 created_at 时间字符串表示的特定日期和时间。
根据一个字符串创建一个对象后,可以使用编程语言自身为此类对象提供的各种功能,例如实现日期格式化功能。一个光秃秃的字符串是无法进行日期格式化的,字符串只有转为大写字母功能。
第 3 行代码:将 date 对象转换为中国的本地时间格式,例如 "2023/6/07 20:09:50”。
**对应的 Shortcuts 操作:**格式化日期
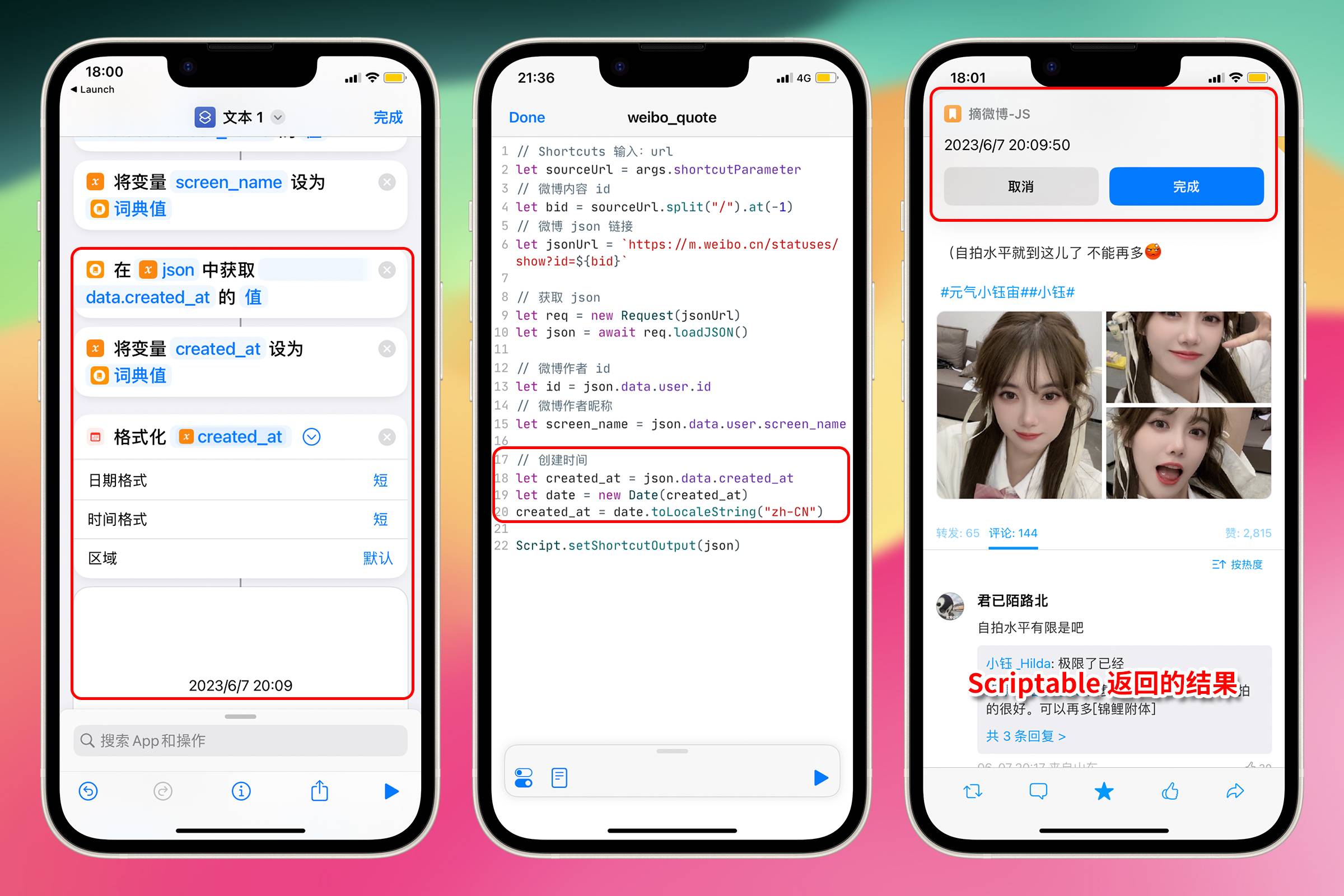
背景知识——JavaScript 面向对象编程介绍:
深入来说,在 JavaScript 中当创建一个字符串时,即 Wed Jun 07 20:09:50 +0800 2023,但实际上 JavaScript 在背后创建了一个 String (字符串)对象。这一切都是自动进行的,并不需要显式地声明一个新的 String 对象,毕竟字符串实在是太常用了。你可以在这个字符串上调用 String 对象的所有方法(编程语言自身为此类对象提供的功能)。例如:
let myString = "Hello, world!";
console.log(myString.toUpperCase()); // 输出 "HELLO, WORLD!"
如果尝试直接在一个普通的字符串(比如表示日期的字符串)上调用日期格式化方法,JavaScript 会抛出一个错误,因为这个方法并不存在于编程语言预置的 String 对象中。
因此,需要首先使用 new Date() 创建一个新的 Date 对象,这个对象中包含一些编程语言为此类对象预置的功能。这样就可以在这个对象上调用预置的 toLocaleString 方法了,实现日期格式化。
这是一种常见的面向对象编程(Object-Oriented Programming)模式,特定类型的对象(在这种情况下是 Date 对象)有特定的方法和属性。要使用这些方法和属性,首先需要创建或获取一个该类型的对象。
获取微博内容——JavaScript 正则表达式
接下来是获取微博内容,在 JSON 中已经包含我们需要的文本。仔细观察可以发现里面包含了一些 HTML 标签表示表情或者链接、HTML 换行符(<br />)表示文本中的换行,我们要逐一清理。
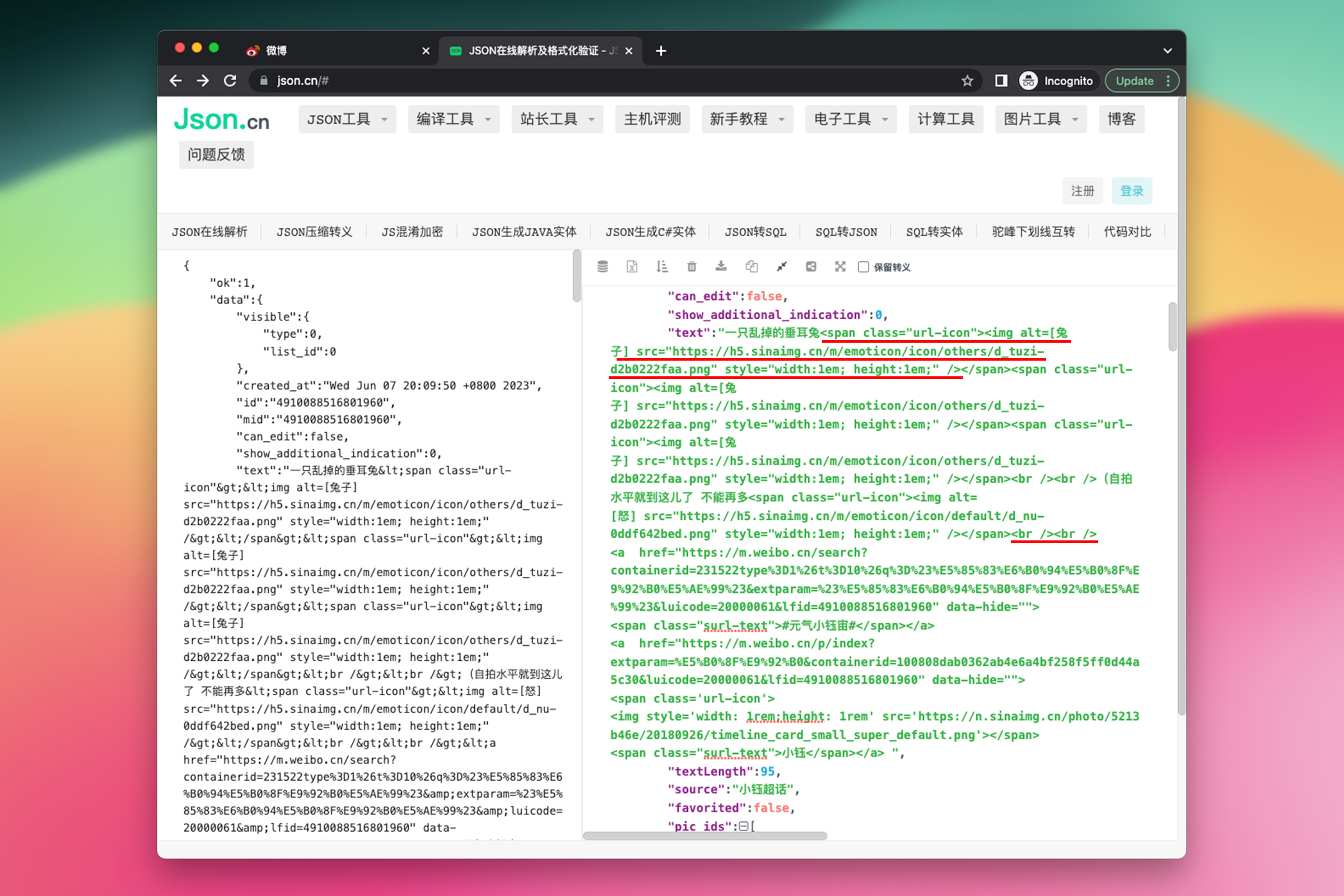
这是我们要用到的代码
// 清理文本
let text = json.data.text;
text = text.replaceAll("<br />", "\n");
text = text.replace(/<.*?>/g, "");
第 1 行代码:从 JSON 中获取内容
第 2 行代码:使用 String 字符串对象的 replaceAll 方法,将微博文本中的所有 <br /> 标签替换为 \n 换行符。
第 3 行代码:使用了正则表达式 /<.*?>/g 来找到文本中所有的 HTML 标签,并将它们替换为无内容(即删除这些标签)。
/.../是 JavaScript 中使用正则表达式的语法,g 代表 "global",意味着匹配字符串中的所有实例<.*?>是正则表达式的一部分,<和>是 HTML 标签的起始和结束标志,.代表任意字符,*代表前面的字符可以出现任意次数(包括 0 次),?使得*代表的重复非贪婪(也就是尽可能少地匹配字符,避免过度匹配)。 注意这里有一个顺序,要先处理 HTML 换行符,然后再处理 HTML 标签。否则的话,HTML 换行符会被匹配为 HTML 标签一起被删除导致文本没有换行。
对应的 Shortcuts 操作:“替换文本”
这里用到一个小技巧:Shortcuts 中没办法输入换行符,但是可以在“文本”动作中输入一个换行,然后在“替换为”那里使用包含换行符的文本进行替换。
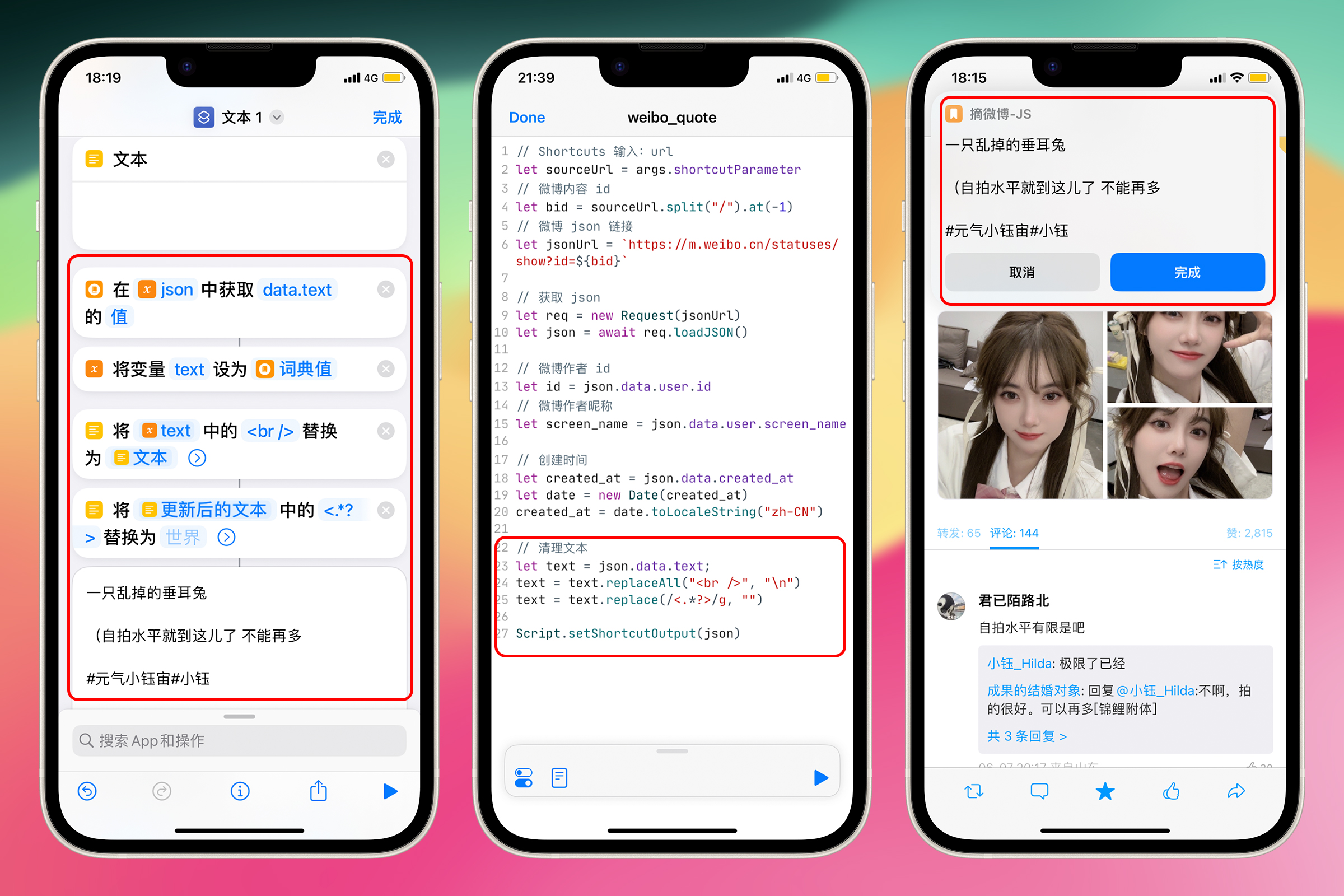
代码写多了之后,已经不适合在手机上编辑了,可以到电脑上打开 iCloud Drive——Scriptable,找到“weibo_quote”,使用任意文本编辑器来继续写 JavaScript 代码。
获取和展示微博图片
获取微博图片——JavaScript 循环与数组
接下来看如何获取微博图片。
观察 JSON 可以发现所有的图片都被放在一个名为 pic (picture)的数组中([]表示数组),其中的每个元素都代表了一张图片的信息。因此只需要通过循环遍历这个数组,就能拿到每一张图片。
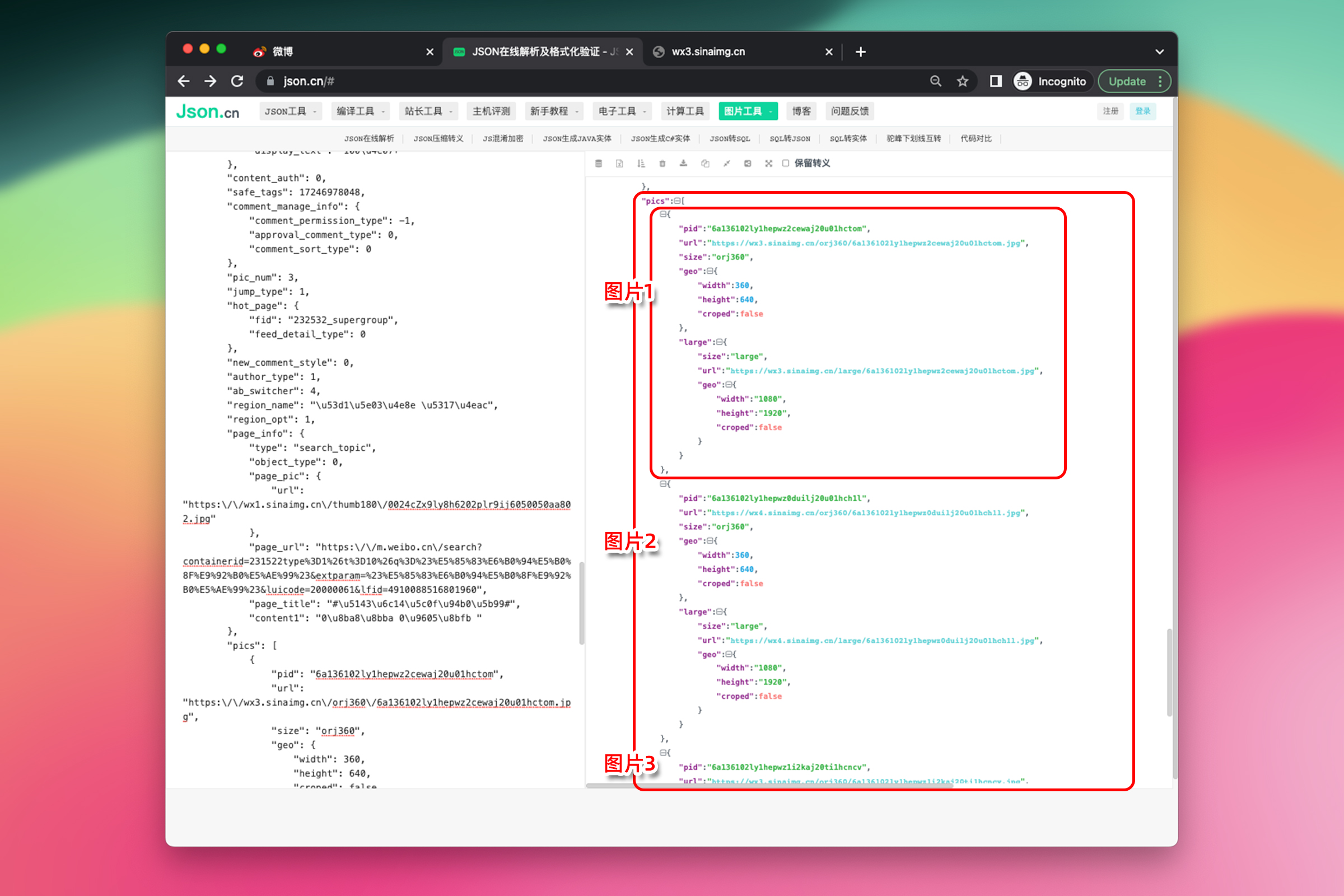
根据我们的想法就有了以下代码
// 获取图片数组
let pics = json.data.pics;
// 遍历每一张图片
for (value of pics) {
}
第 1 行代码:获取 pics 数组,包含了一组图片的信息。
第 2 行代码:遍历 pics 数组中的每一个元素。在每次循环中,value 变量会被设置为数组中的下一个元素。在大括号 {} 之间的代码会对每个 value 进行处理。这些 value 代表了 pics 数组中的每一张图片的信息。
继续深入观察数组中的每个元素,每个元素包含了图片的多种属性,包括 pid(picture,图片的唯一标识符)、url(默认的图片地址)、size(默认的图片大小,orj360 是 "Original 360" 的缩写,表示这张图片的原始尺寸被缩放至宽度为 360px)、geo(geometry,默认的图片尺寸信息)、large(高清大图的尺寸信息)。
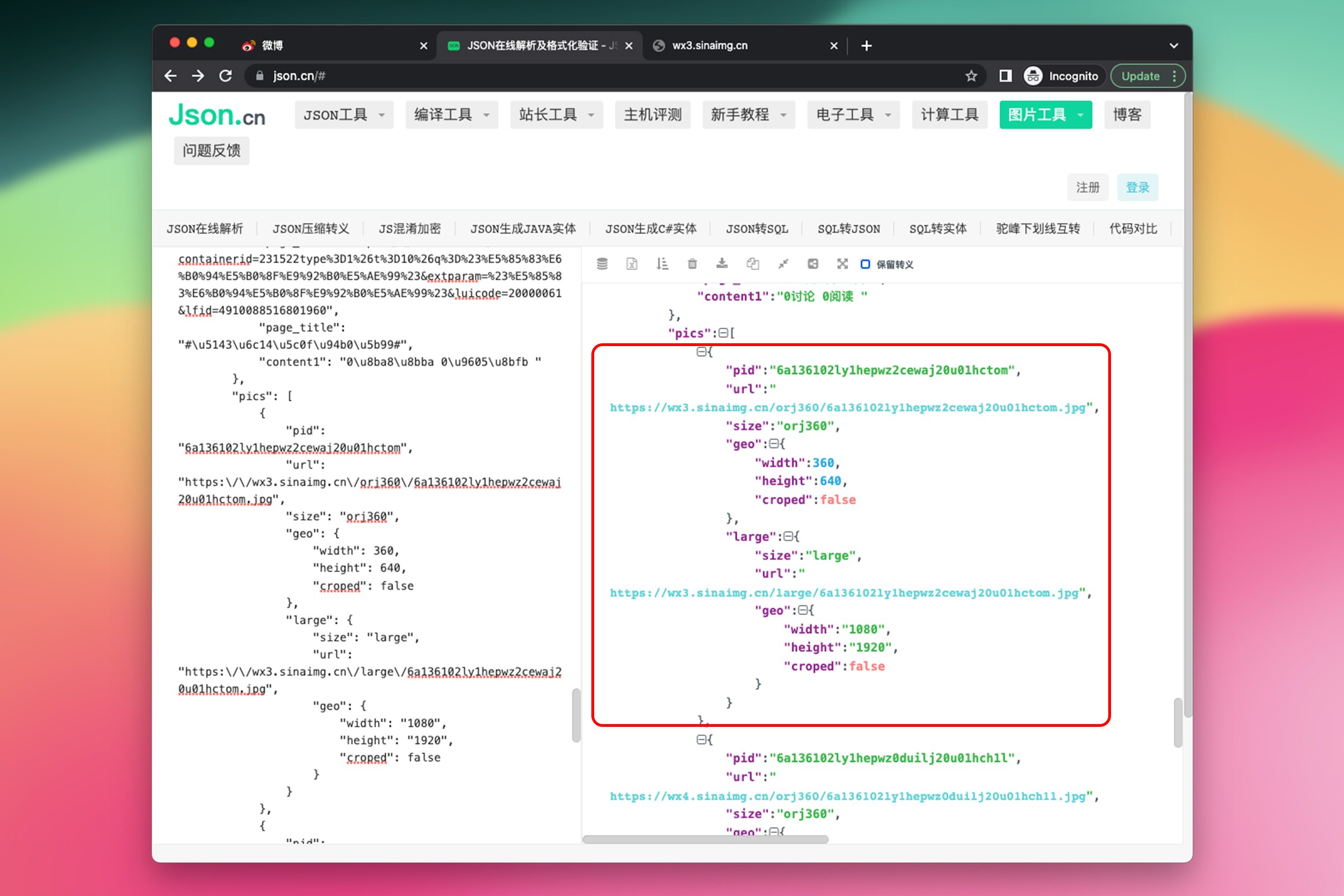
因此,如果想找到每一张高清大图的地址,应该先获取数组中每个元素的 large 属性,然后获取 large 对象的 url 属性。
这里可能有的朋友会问,怎么前半句说 large 属性,后半句说 large 对象。这是因为两句话的主体不同。
在前半句中,谈论的主体是每个元素,large 是 pics 数组中每一个元素的一个属性,所以称为 large 属性。
在后半句中,谈论的主体是 url 属性,url 作为一个属性存储在 large 对象中,所以称为 large 对象。
// 获取图片数组
let pics = json.data.pics;
// 遍历每一张图片
for (value of pics) {
// 获取图片链接
let imageUrl = value.large.url;
}
这样就获取到了每一张图片的地址。
在我的测试中 Scriptable 下载微博图片有时会产生巨大的图片体积,所以暂时只能把图片交给 Shortcuts 来下载。也就是把每张图片地址发送给 Shortcuts。 关于使用 Scriptable 下载图片的方法我会补充到附录中。 那现在需要做的就是把图片地址整理到一个数组中,等将来发送给 Shortcuts 下载。
首先在 for 循环外部声明一个空数组,用来存储每次循环中的图片地址。如果将其放在 for 循环内部,那么每次循环都会创建一个新的 imageUrls 数组,旧的 imageUrls 数组以及其中的数据都会被丢弃,这显然不是我们想要的结果。
然后写一行将图片地址添加到数组中的代码:
let pics = json.data.pics;
// 创建一个数组
let imageUrls = [];
for (value of pics) {
let imageUrl = value.large.url;
// 每次循环添加一个图片地址
imageUrls.push(imageUrl);
}
这里使用了 push 方法在数组的末尾添加元素。每次循环都在数组中添加一个元素,当循环结束后,就汇总了所有图片地址。
这里先不放 Shortcuts 动作对比示例,等下一小节结束后再来看对比示例。
创建 Markdown 图片预览
现在要加一个小功能,就是在笔记工具 Obsidian 中同时浏览保存的微博内容和图片。
得益于 Obsidian 自动索引图片的特性,只要用 ![[]] 包裹住文件名,就可以在笔记中显示这张图片。
在 Obsidian 中,![[]]是链接到本地文件的语法,是一种”嵌入式链接"。可以链接到 Markdown 文件、图像文件、音视频文件、PDF 文件。使用这种语法引用图片文件时,Obsidian 将在预览模式下显示这张图片。
详细介绍可以参考:Obsidian 嵌入文件
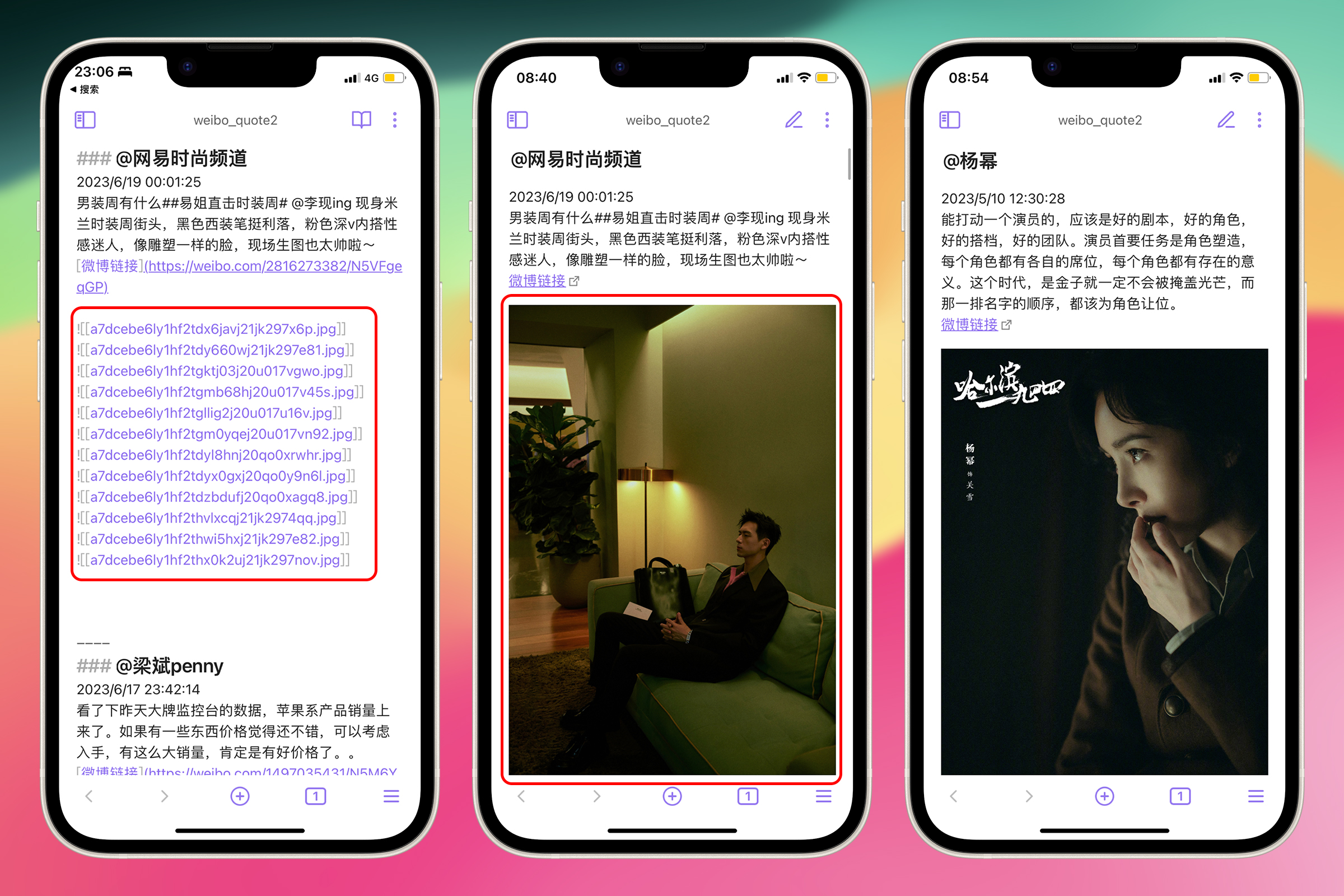
在笔记中出现 ![[图片文件名.jpg]] 这样的语法时,Obsidian 将查找名为 图片文件名.jpg 的文件(在仓库文件夹或其子文件夹中)。如果找到了该文件,Obsidian 将在文档中的相应位置显示这张图片。
而且,最棒的是,完全不需要写出图片的完整路径。这样保存的微博图片可以不需要层级目录全都丢到 images 文件夹中,只要在笔记中写出图片名称,Obsidian 会自动帮我们寻找对应的图片。
再次在循环外声明一个数组 iamgeNames 用来存储图片名称。然后,在循环体中添加下面这行代码
let imageName = imageUrl.split("/").at(-1);
imageNames.push(`![[${imageName}]]`);
第 1 行代码:将类似 https://wx3.sinaimg.cn/large/6a136102ly1hepwz2cewaj20u01hctom.jpg 这样的图片地址按照 / 分割,选取最后一个元素,即图片名称。
第 2 行代码:将图名称添加到 imageNames 的数组中。当循环结束后,可以显示所有图片的 Obsidian 嵌入式链接就生成了。这里使用到了前面讲过的模板字符串语法 ${},将图片名字 imageName 插入到 ![[]] 中。
最终的代码应该是这样
// 之前的代码
let pics = json.data.pics;
let imageUrls = [];
// 创建图片名称数组
let imageNames = [];
for (value of pics) {
let imageUrl = value.large.url;
// 每次循环添加一个图片地址
imageUrls.push(imageUrl);
let imageName = imageUrl.split("/").at(-1);
// 每次循环添加一个图片名称
imageNames.push(`![[${imageName}]]`);
}
对**应的 Shortcuts 操作:**获取词典值、为每个项目重复、添加到变量、拆分文本、从列表中获取项目、文本字符串拼接 可以看到在 Shortcuts 可以直接使用类似数组的功能,而不需要在循环外部提前声明数组,比较方便。
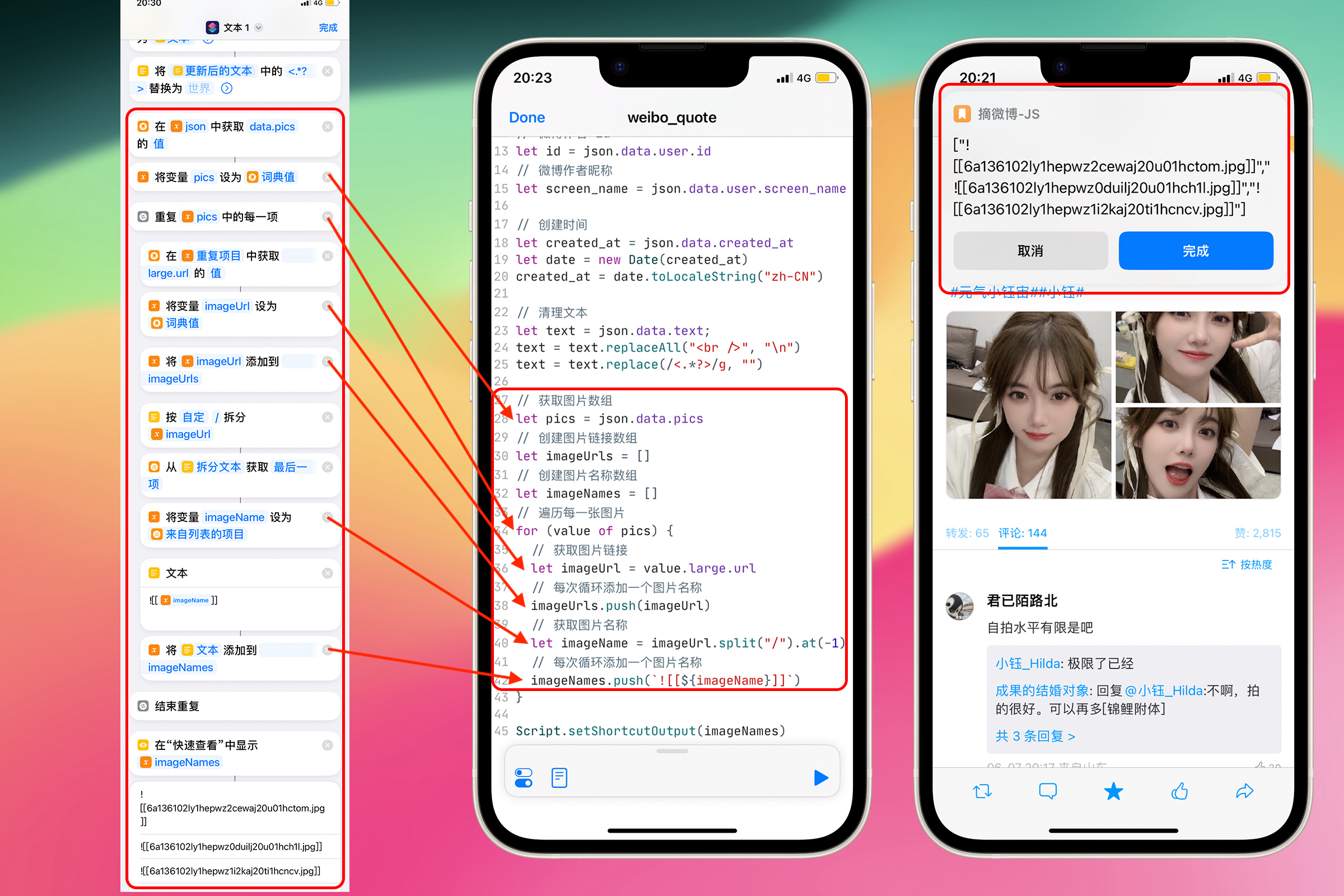
处理没有图片的微博——JavaScript 条件判断
到这里我们要考虑到一个情况——不是所有的微博都有图片。
找一条只有文字内容的微博观察它的 JSON,发现其中没有 pics 属性。如果直接对一个不存在的属性进行操作(比如在 for 循环中遍历它),JavaScript 会抛出一个错误,并终止执行代码。为了避免这个问题,我们需要在访问 pics 属性之前,先检查它是否存在。
在之前的代码添加加一个 if 判断,当有值的时候在进行获取图片的操作,没有值的话不进行获取图片的操作。
if ("pics" in json.data){
...
}
如果 pics 这个属性在 json.data 中,即在 JSON 中存在,那么 if 语句中的代码块就会执行。in 运算符在 JavaScript 中常用来检查一个对象是否包含某个特定的属性。
这里还有一个问题要注意,在 JavaScript 中,变量的作用域(有效范围)被限定在它被声明的代码块 {}内,这就是"块级作用域"。在一个 if 代码块内部声明一个变量,那么这个变量只在这个代码块内部可见,一旦代码执行出了这个代码块,这个变量就会被销毁,无法再被访问。因此,我们需要将数组imageUrls 和 imageNames 的声明移动到 if 判断外面。
经过完善后的代码如下所示
let imageUrls = [];
let imageNames = [];
if ("pics" in json.data) {
// 之前的代码
let pics = json.data.pics;
for (value of pics) {
let imageUrl = value.large.url;
imageUrls.push(imageUrl);
let imageName = imageUrl.split("/").at(-1);
imageNames.push(`![[${imageName}]]`);
}
}
在 Shortcuts 可能并不需要这个操作,Shortcuts 会直接为我们处理值不存在的问题。如果 pics 不存在,会直接跳过循环中的流程。这是 Shortcuts 比较易用的特性。
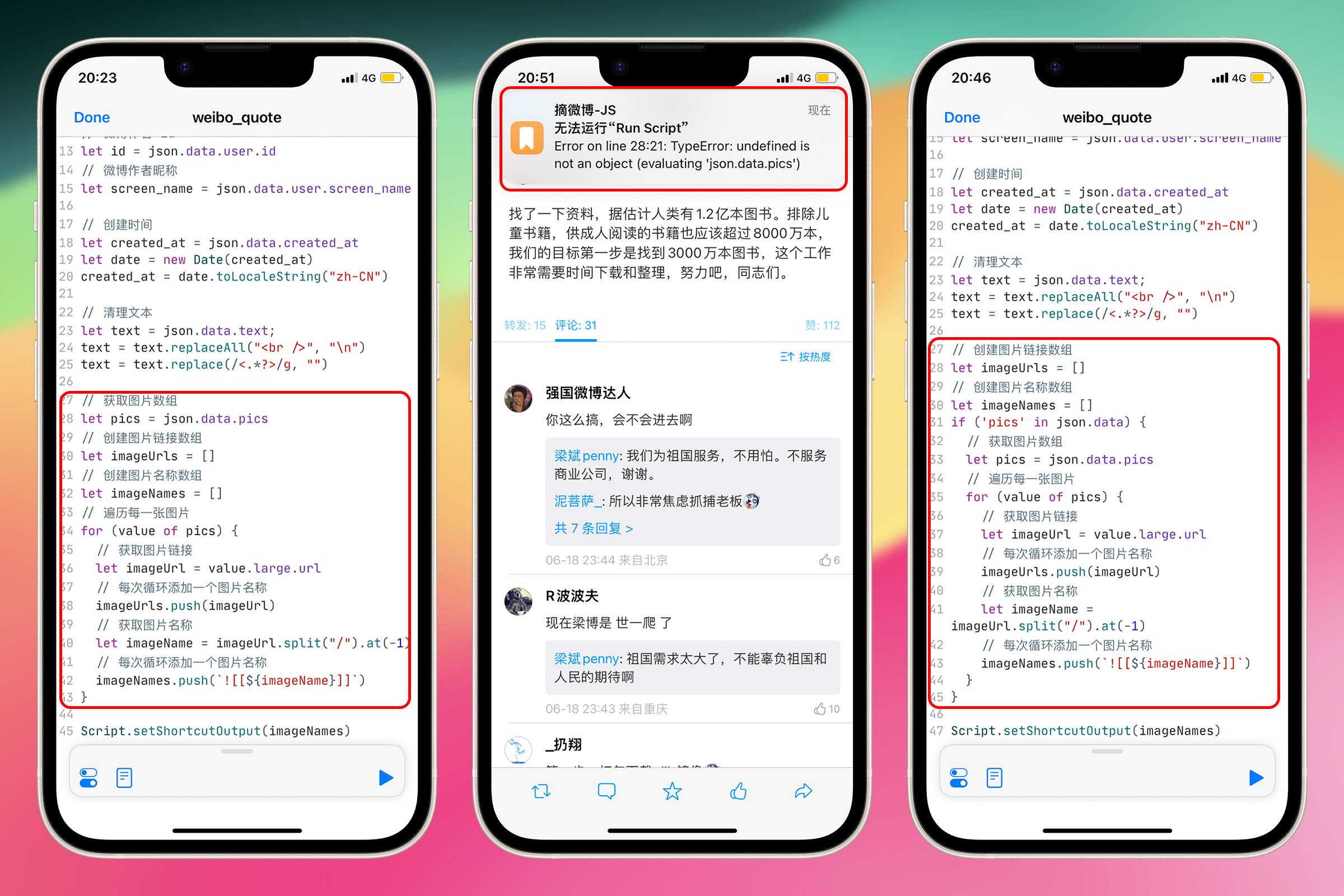
保存微博
制作保存微博的样式
现在作者名字、创建时间、内容、链接、图片地址和名称全都有了,只需要将他们拼接成一则微博即可。
// Markdown 格式的分割线
// 微博作者名字
// 微博创建时间
// 微博内容
// Markdown 格式的微博链接
let weibo_quote = `----
### @${screen_name}
${created_at}
${text}
[微博链接](${sourceUrl})
`;
// Markdown 格式的图片链接
weibo_quote +=
imageNames.length > 0 ? imageNames.join("\n") + "\n\n\n" : "" + "\n\n\n";
第 1 行代码:创建一个新的字符串 weibo_quote,使用模板字符串将变量插入到字符串中。里面包含 Markdown 格式的分割线和一个换行符。(注意 —-- 在 Obsidian 文档有特殊含义,所以这里使用了 4 个短 -)
第 2 行代码:将 Markdown H3 标题标记、微博作者昵称、换行符添加到了 weibo_quote 字符串中。
第 3 行代码:向 weibo_quote 字符串中添加了微博创建时间。
第 4 行代码:添加了一个 Markdown 形式的微博链接。
第 5 行代码:看起来有些复杂,实际上并不难理解。其实是一个 if 条件判断的便捷写法,称为条件运算符,用于在一行代码中进行条件判断。
它的语法格式是 条件表达式 ? 表达式1 : 表达式2。意思是,如果条件表达式结果为 true ,则执行表达式 1,否则执行表达式 2。
如果 imageNames 这个数组的长度大于 0 ,即数组中元素的个数大于 0,那么执行表达式 1——imageNames.join("\n") + "\n\n\n" 将 imageNames 这个数组的每一个元素用换行符 \n 连接起来,然后添加 3 个换行符。
如果 imageNames 小于等于 0(数组中没有元素),那么就执行表达式 2:"" + "\n\n\n" 一个空字符串和 3 个换行符。
所以这一整行代码的意思是:如果 imageNames 有值,就将 weibo_quote 加上 imageNames 各元素以换行符 \n 连接后的字符串,然后加上 3 个换行符。否则直接将 weibo_quote 加上 3 个换行符。
对应的 Shortcuts 操作:“文本”拼接字符串
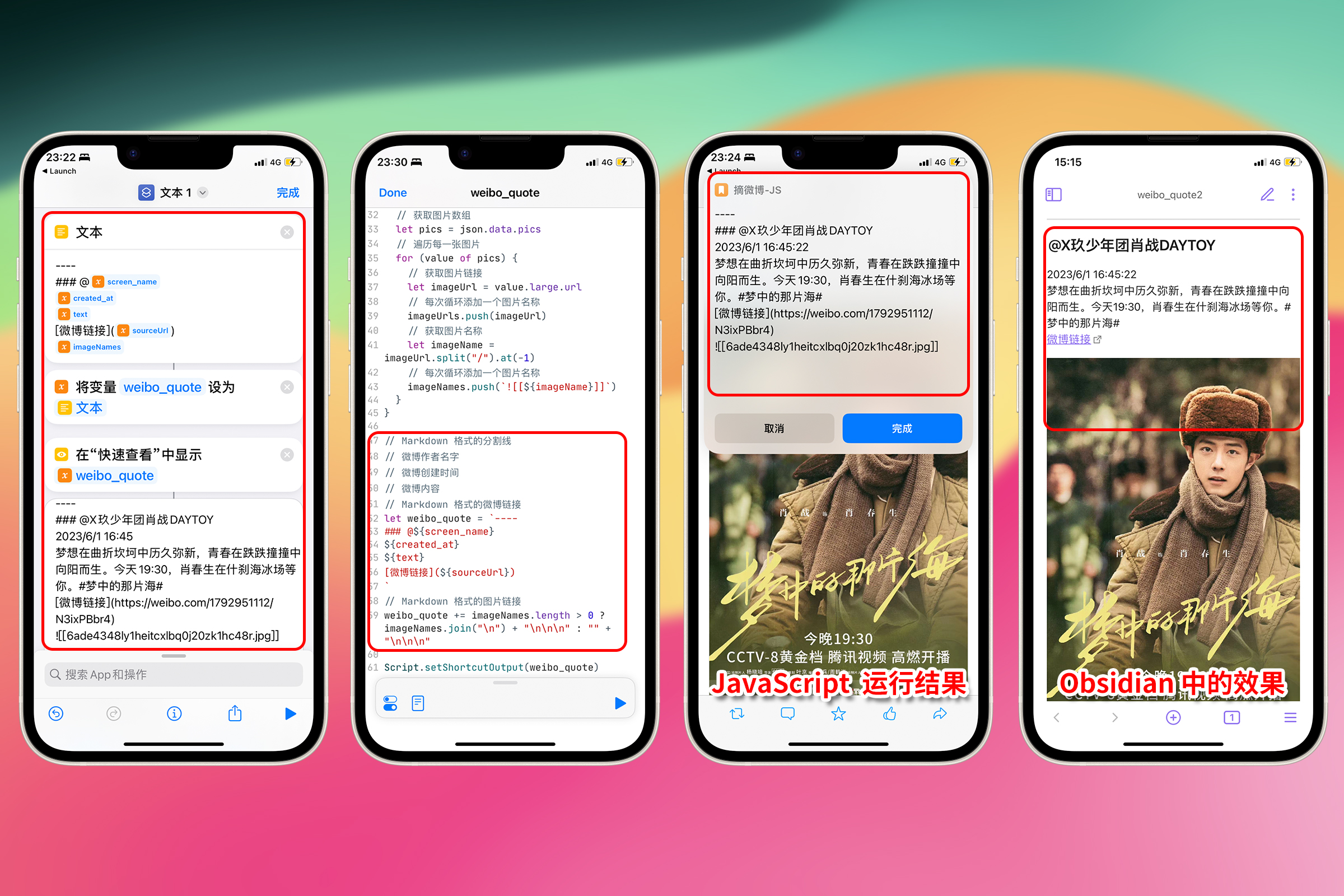
将微博保存到文件——JavaScript 输出
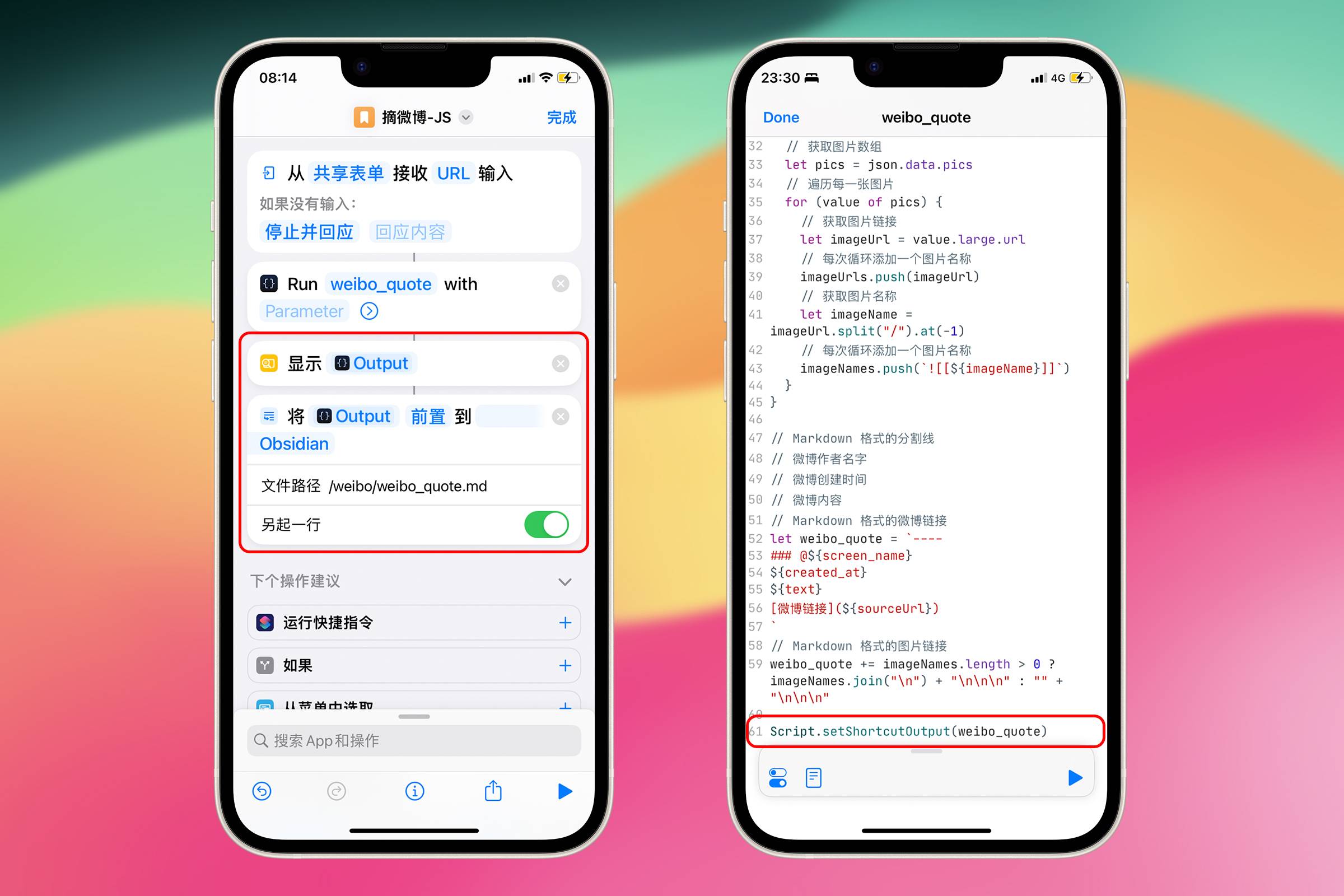
现在所有的流程执行完毕,只需要将文本内容保存到手机上。 这里为了方便和节省资源(通过 Shortcuts 运行 JavaScript 脚本时可使用的内存有限)可以使用 Shortcuts 中的“追加到文本文件”动作保存到手机上。这就需要 Shortcuts 能够接受到我们生成的微博内容。
在 Scriptable 中,可以使用 Script.setShortcutOutput() 将一个值传递给 Shortcuts。只需要添加 1 行代码,就可以在 Shortcuts 中继续处理由 JavaScript 生成的 weibo_quote。
文章开头做 Shortcuts 和 Scriptable 联动测试时,使用的 return 是一种简便写法,这里应使用正式写法 Script.setShortcutOutput()。
Script.setShortcutOutput(weibo_quote);
然后在 Shortcuts 中使用“追加到文本文件”动作,将 weibo_quote 保存到手机上。
追加文本选择“前置”,以便将最新保存的微博内容放在最前面。文件路径选择 Obsidian,这个发现来自 UNTAG Premium 第十九期iOS Shortcuts 产生的文件可以保存到任意文件夹
文件路径那里写上/weibo/weibo_quote.md 这样微博内容和图片都保存在 Obsidian 的 weibo 目录下。
注意:这里左边的 Shortcuts 截图是我们的“摘微博-JS”,不是对比示例。
可以看到 Shortcuts 只需要一个动作就可以将微博内容保存为 markdown,同样的操作要写很多行 JavaScript 代码,还会有一些性能问题。这部分的相关介绍放在附录中。
下载微博图片
将内容保存下来后,接下来是保存图片。 因为目前 Scriptable App 在下载微博图片时有一些 bug,只能使用曲线救国的方式,将图片地址发给 Shortcuts,让 Shortcuts 来下载。 这就需要对前面的 JavaScript 代码输出进行修改,要同时输出微博内容和图片链接。考虑到保存的微博可能没有图片,那就需要在 Shortcuts 中增加一个判断,当有图片时再运行下载流程。但是这会使 Shortcuts 中的动作增多。
不过,有一个取巧的办法。 前文说过,在 Shortcuts 中使用“获取字典值”时,Shortcuts 会自动帮我们进行判断。如果没取到值,就跳过后续相关流程。这个贴心设定使我们的 Shortcuts 流程看起来更加简洁。 要实现这种效果,只需要将所有内容输出为 JSON 格式的字符串到 Shortcuts 中,这样就可以使用“获取词典值”来自动进行判断是否有某个值。
let output = {
weibo_quote: weibo_quote,
};
if (imageUrls.length > 0) {
output.imageUrls = imageUrls;
}
let jsonString = JSON.stringify(output);
Script.setShortcutOutput(jsonString);
第 1 行代码:创建了一个名为 output 的对象。这个对象中有一个属性:weibo_quote。它的值是字符串 weibo_quote 的内容。
第 2 行代码:如果 imageUrls 长度大于 0,那么就会向 output 对象中添加一个新的属性 imageUrls,它的值是 imageUrls 数组的内容。
第 3 行代码:将 output 对象转换成 JSON 格式的字符串。
第 4 行代码:将 jsonString 的内容作为输出,传递给 Shortcuts。
这样就会创建一个类似下面这样的 JSON 字符串
output: {
"weibo_quote": "微博内容",
"imageUrls": ["url1.jpg", "url2.jpg", "url3.jpg"]
}
在 Shortcuts 中我们可以很方便的对其进行取值。
首先使用“获取词典值”通过 weibo_quote 键取到“微博内容”,直接将其保存到文本文件 weibo_quote.md 中。
然后继续使用“获取词典值”,通过 imageUrls 键取到“图片地址”。如果摘抄的微博没有配图,那 output 中就没有 imageUrls 键,自然取不到值,也不会执行后续的流程。
如果有 imageUrls 键,会取到一个数组 [],在 Shortcuts 中可以直接将其视为列表而对其进行遍历。
按照下面的截图在 “摘微博-JS” Shortcuts 中依次添加:
保存微博内容:获取词典值(weibo_quote)、显示结果、追加文本。
下载微博图片:获取词典值(imageUrls)、为每个项目重复、拆分文本、从列表中获取项目(根据链接生成文件名)、获取 URL 内容、存储文件
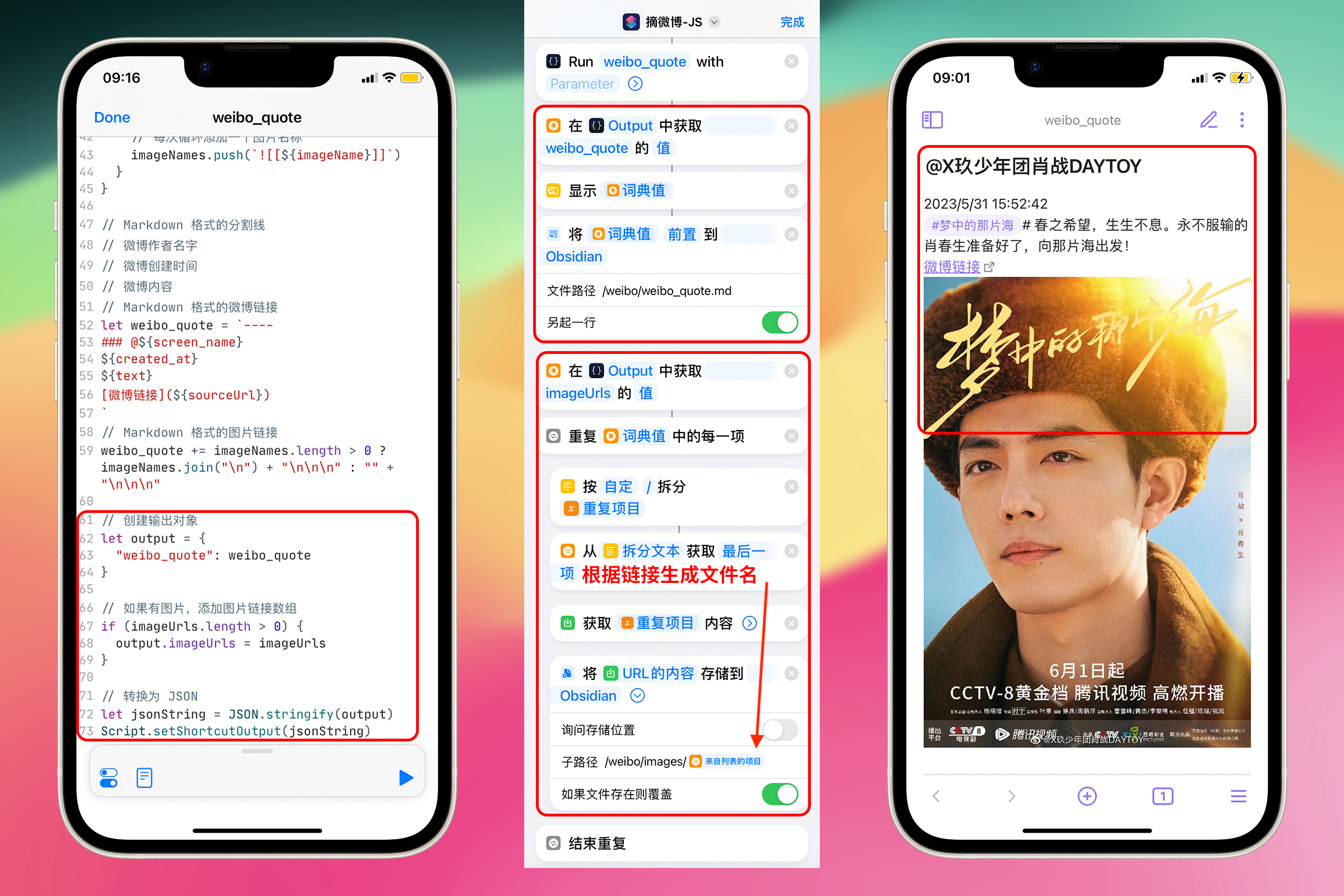
可以发现由于从 Scriptable 中输出的数据是结构化的,因此可以根据需要访问任意级别的数据,无论是单个值,还是复杂的嵌套结构。利用 JSON 格式数据在 Shortcuts 和 Scriptable 之间传递数据,使得自动化流程的构建变得更加简单和高效。
至此,已经成功创建了一个保存微博图文的自动化流程。综合来看,JavaScript 代码的强大之处在于其在数据处理方面的能力,而 Shortcuts 则展现了其在与设备交互上的优越性。
练习
练习 1:去除 # 号标签
微博中用 # 号表示话题,Obsidian 中用 # 号表示标签。为了避免 Obsidian 中的标签被影响,需要在之前的流程中处理一下 # 号。

如果在 Shortcuts 中想再次修改做好的流程,要费一番功夫——跨越重洋拖动作不说,还要小心不要搞乱动作次序,也不要搞乱变量位置。在 JavaScript 中,只需增加 1 行代码,就可以将 # 号替换掉。
text = text.replaceAll("#", "📣");

练习 2:生成正确的微博链接
写完文章后发现,如果微博内容中包含其他链接时,奇点 App 会将微博内容中的链接一起分享出来,这并不影响保存微博,但是会使笔记中 Markdown 形式微博链接包含了多个链接,导致无法跳转回原微博。
可以看到 http://t.cn/A6p0rRJg 和 https://weibo.com/1111681197/N5wo0AMiZ 两个链接中间用 %0A 链接起来了。这是用 URL 编码表示的换行符。
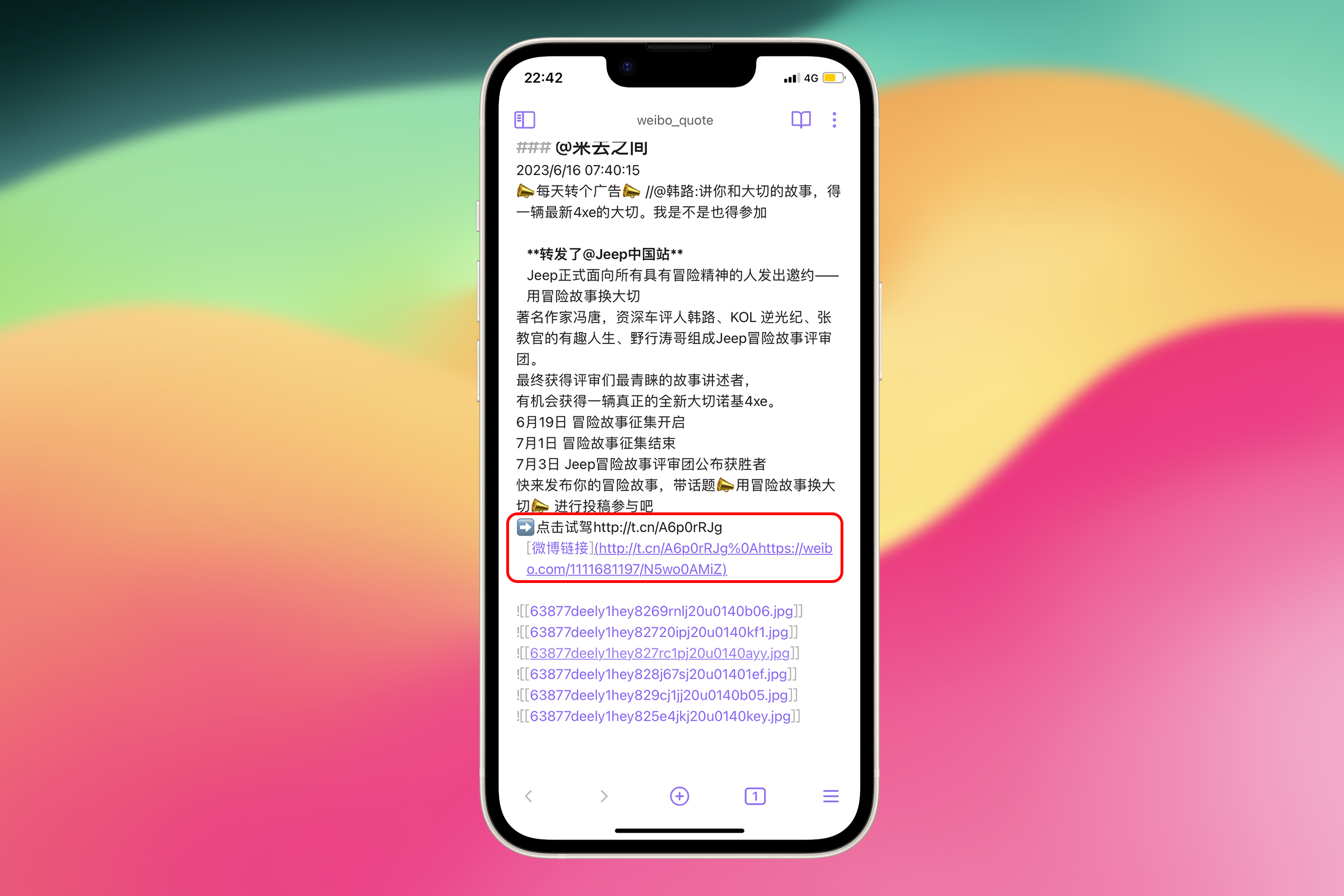
现在来修正这个问题。
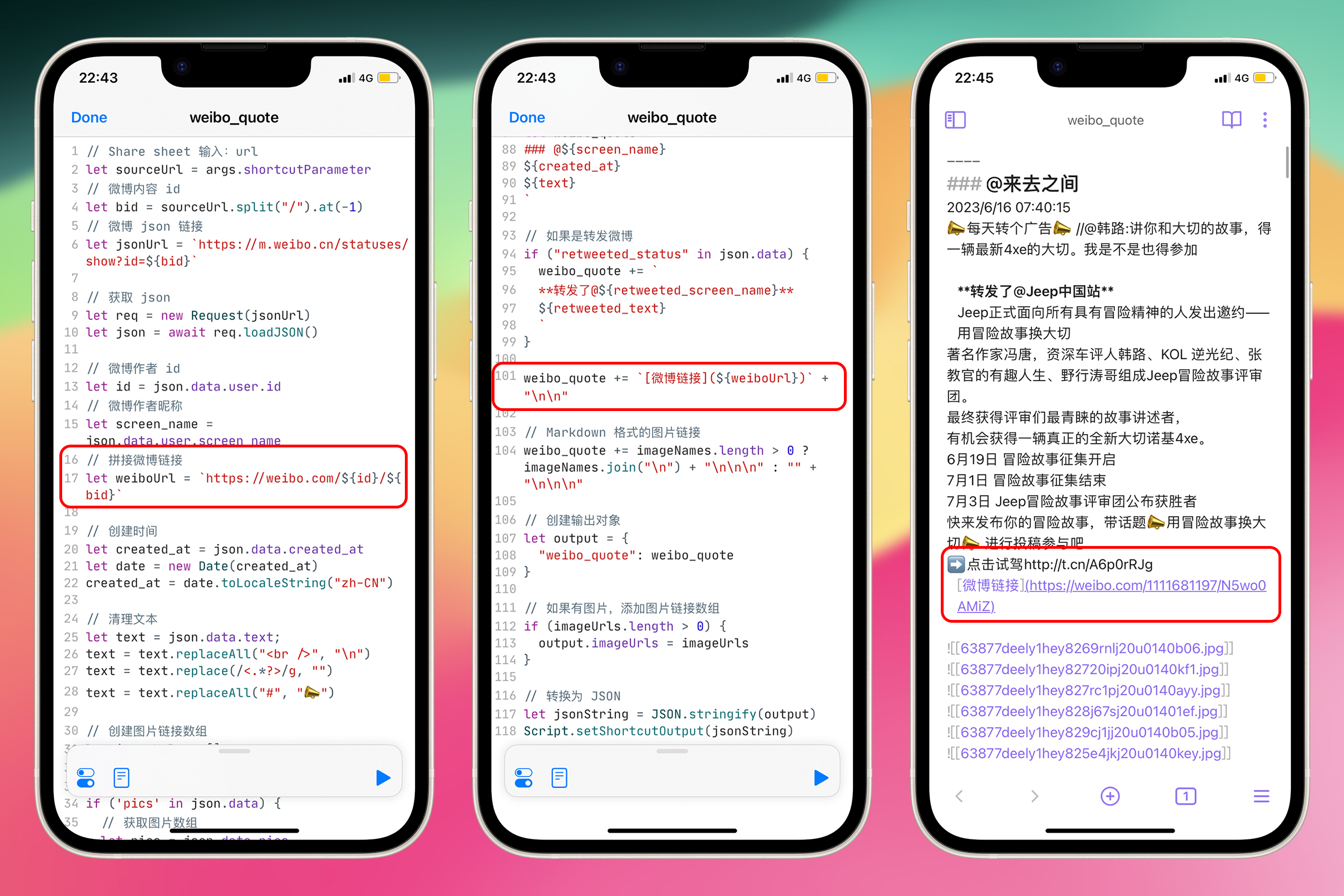
在目前的 JavaScript 代码中,已经有了微博作者 id 和微博内容 id,只要将这两者按照 https://weibo.com/微博作者 id/微博内容 id 的格式拼接起来即可。
在代码中获取微博作者 id 的位置加上一行代码,拼接出正确的微博链接
let weiboUrl = `https://weibo.com/${id}/${bid}`;
在代码尾部将
weibo_quote += `[微博链接](${sourceUrl})` + "\n\n";
修改为
weibo_quote += `[微博链接](${weiboUrl})` + "\n\n";
使用拼接的链接来生成跳转链接。
第二部分——保存转发图文的微博
观察转发微博的 JSON 结构
通过前面的讲解熟悉 JSON 和 JavaScript 之后,接下来处理转发微博。
找一条微博,这条微博要包含最复杂的内容:是转发并评论微博、被转发微博是长微博、被转发微博包含多张图片。
以这条微博为例 https://weibo.com/1111681197/N5wo0AMiZ 观察服务器返回的 JSON。(在奇点微博客户端,分享微博后,点击“拷贝链接”即可获得微博链接)
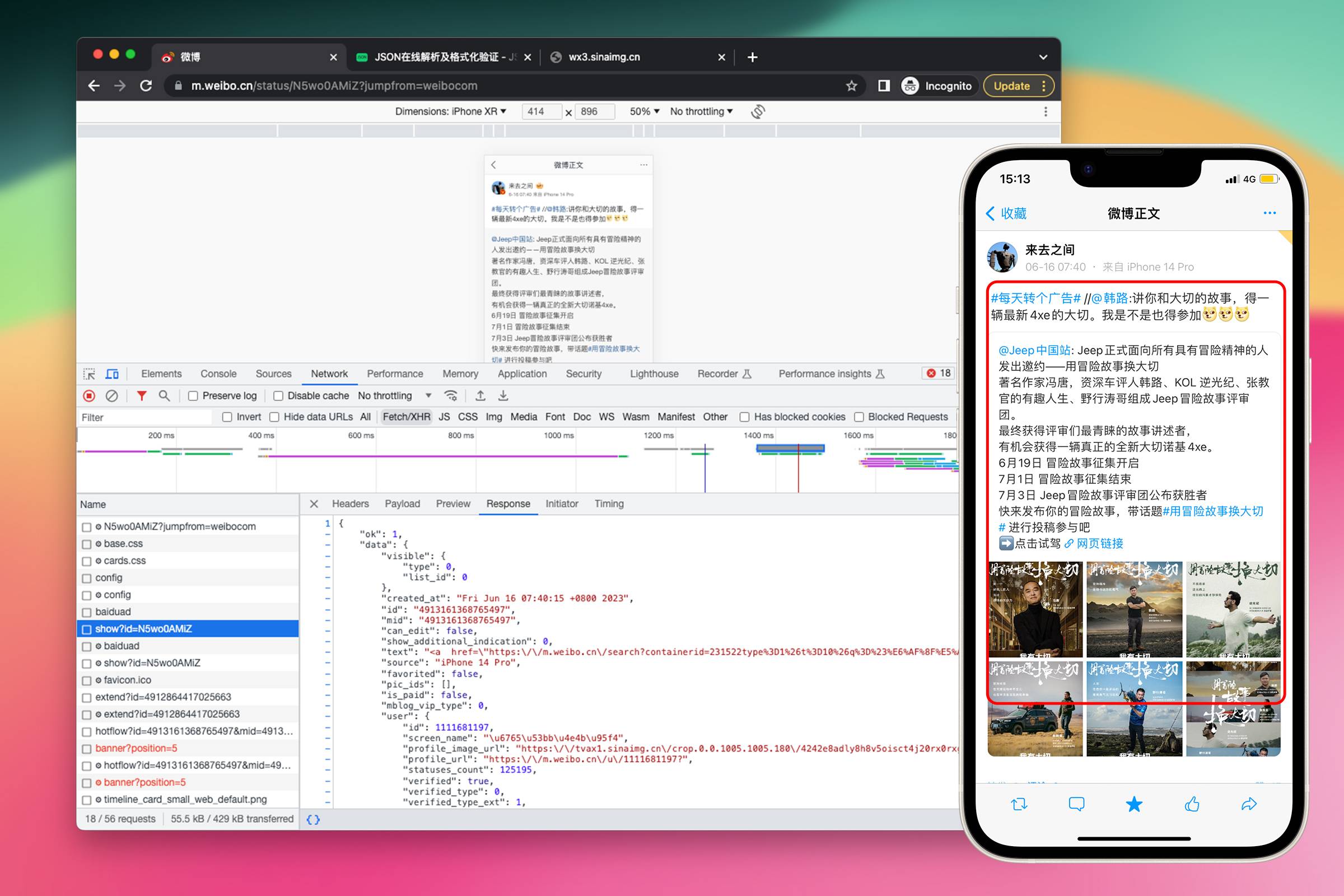
将 JSON 复制到 json.cn 观察,与之前的单条微博 JSON 进行对比,发现多了 retweeted_status 属性,在 retweeted_status 这个层级下浏览一番可以看到与之前的单条微博 JSON 结构很相似。也有 screen_name(被转发微博的作者昵称)、text(被转发微博的内容)、pics(被转发微博的图片数组)。
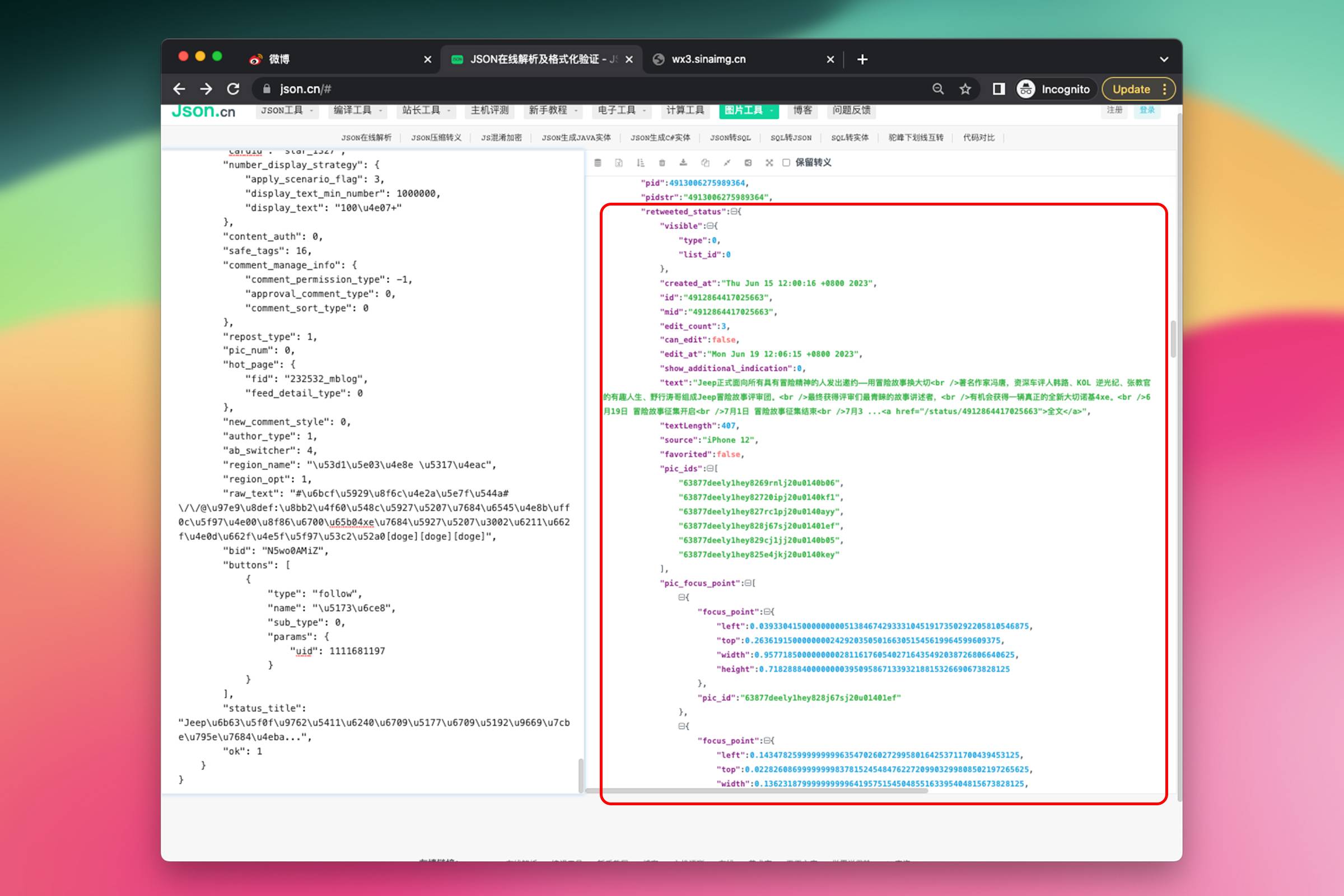
整个 JSON 中对我们有用的内容大概可以用如下结构来表示:
// 单条微博
——ok
——data
————created_at 微博创建时间
————text 微博内容
————user
——————screen_name 昵称
————pics
——————large
————————url 微博图片地址
// 转发微博
————retweeted_status 被转发微博
——————user
————————screen_name 被转发微博的作者昵称
——————text 被转发微博的内容
——————isLongText 是否为长微博
——————longText
————————longTextContent 被转发微博的全文
——————pics
————————large
——————————url 被转发微博的图片地址
获取被转发微博的作者昵称和内容
利用前文讲述的 . 号运算符,来从 JSON 中提取需要的内容
// 被转发微博的作者昵称
let retweeted_screen_name = json.data.retweeted_status.user.screen_name;
接下来是获取微博内容,这里有一点弯儿。
当微博内容是长微博时,微博内容保存在 retweeted_status.longTextContent,同时 retweeted_status.isLongText 是 true
当微博内容不是长微博时,微博内容保存在retweeted_status.text。根据这个情况就产生了以下代码
if (json.data.retweeted_status.isLongText) {
let retweeted_text = json.data.retweeted_status.longText.longTextContent;
} else {
let retweeted_text = json.data.retweeted_status.text;
}
然后在末尾加上与之前一样的文本清理代码,清理 HTML 标签
if (json.data.retweeted_status.isLongText) {
let retweeted_text = json.data.retweeted_status.longText.longTextContent;
} else {
let retweeted_text = json.data.retweeted_status.text;
}
retweeted_text = retweeted_text.replaceAll("<br />", "\n");
retweeted_text = retweeted_text.replace(/<.*?>/g, "");
retweeted_text = retweeted_text.replaceAll("#", "📣");
这里要注意之前提到的变量作用域问题。retweeted_text 是在 if 判断里面声明并赋值的,在外部无法使用。因此需要修改一下代码,在 if 判断外面先声明 retweeted_text
修改后的代码如下:
let retweeted_text;
if (json.data.retweeted_status.isLongText) {
retweeted_text = json.data.retweeted_status.longText.longTextContent;
} else {
retweeted_text = json.retweeted_status.text;
}
retweeted_text = retweeted_text.replaceAll("<br />", "\n");
retweeted_text = retweeted_text.replace(/<.*?>/g, "");
retweeted_text = retweeted_text.replaceAll("#", "📣");
获取被转发微博的图片
通过观察 JSON,可以发现 pics 从 data 移动到了 retweeted_status,但是 pics 数组的结构与之前的一模一样,可以把之前的代码修改一下属性位置直接拿过来用。
// 注意这里 pics 是 retweeted_status 的属性
if ("pics" in json.data.retweeted_status) {
// 注意这里 pics 是 retweeted_status 的属性
let pics = json.data.retweeted_status.pics;
for (value of pics) {
let imageUrl = value.large.url;
imageUrls.push(imageUrl);
let imageName = imageUrl.split("/").at(-1);
imageNames.push(`![[${imageName}]]`);
}
}
imageUrls 和 imageNames 数组在之前的代码中已经声明过了,这里不需要在 if 判断外面再次声明。
现在还需要加一个判断,当要保存的微博包含转发微博时,再运行上面的代码。也就是说,当 data 对象中有 retweeted_status 属性时,再运行上面的代码。
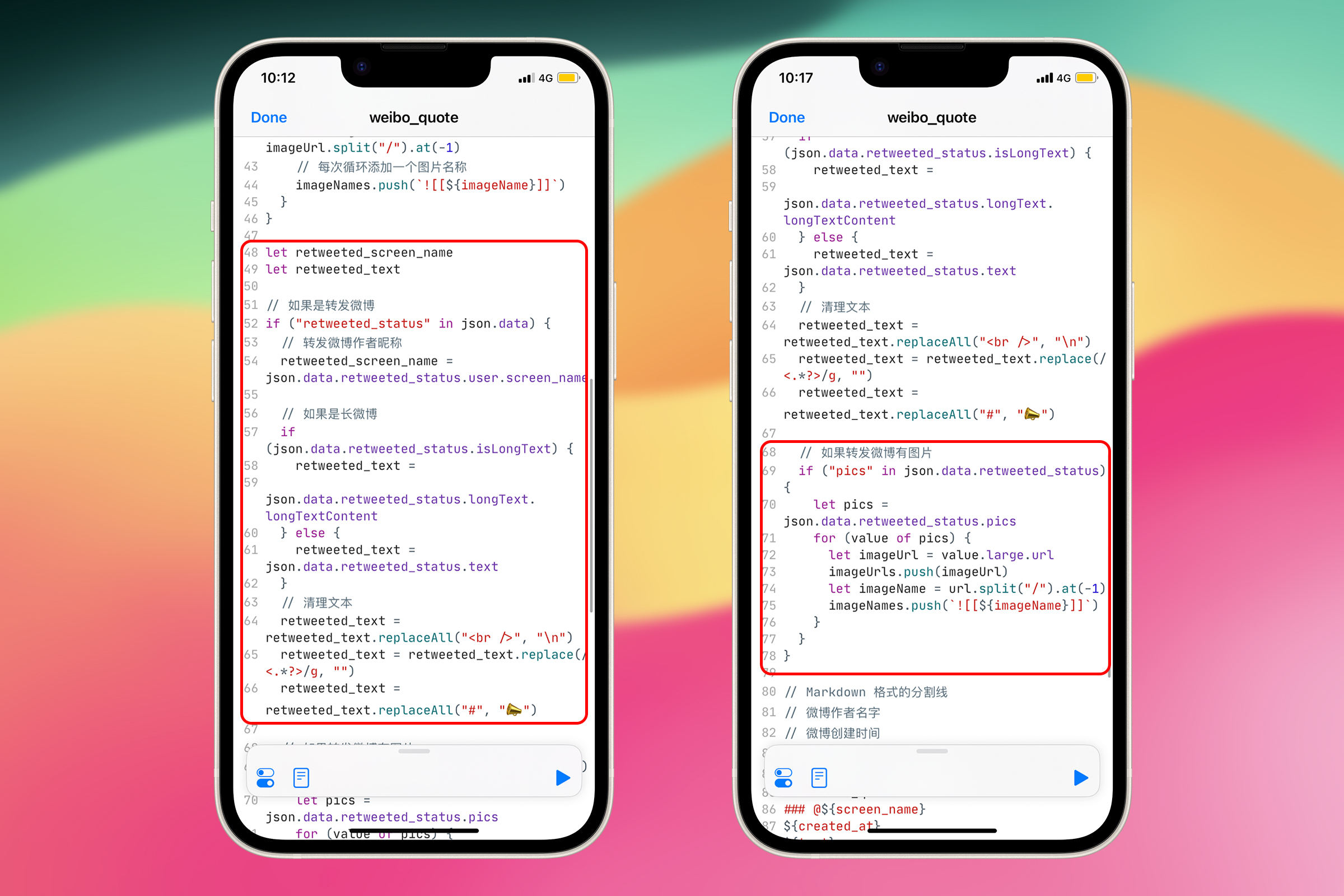
将刚才写的代码,都包裹在一个 if 判断里面。在后面的代码中,需要使用 retweeted_screen_name 和 retweeted_text 变量来制作保存微博的样式,所以需要将它们放到 if 判断的外面
let retweeted_screen_name;
let retweeted_text;
if ("retweeted_status" in json.data) {
retweeted_screen_name = json.data.retweeted_status.user.screen_name;
if (json.data.retweeted_status.isLongText) {
retweeted_text = json.data.retweeted_status.longText.longTextContent;
} else {
retweeted_text = json.data.retweeted_status.text;
}
retweeted_text = retweeted_text.replaceAll("<br />", "\n");
retweeted_text = retweeted_text.replace(/<.*?>/g, "");
retweeted_text = retweeted_text.replaceAll("#", "📣");
if ("pics" in json.data.retweeted_status) {
let pics = json.data.retweeted_status.pics;
for (value of pics) {
let imageUrl = value.large.url;
imageUrls.push(imageUrl);
let imageName = imageUrl.split("/").at(-1);
imageNames.push(`![[${imageName}]]`);
}
}
}
这部分代码在 Scriptable 中的情况截图如所示
制作保存转发微博的样式
这部分没有什么难度,只需要将之前的保存微博样式的代码加上转发微博内容即可。如果包含转发微博,那么加上转发微博的内容。顺手加了换行和一点 Markdown 粗体样式,来稍微突出是一条转发微博。 然后,将微博链接移动到了可能存在的转发微博内容的下方。
// Markdown 格式的分割线
// 微博作者名字
// 微博创建时间
// 微博内容
// Markdown 格式的微博链接
let weibo_quote = `----
### @${screen_name}
${created_at}
${text}
`;
// 如果是转发微博
if ("retweeted_status" in json.data) {
weibo_quote += `
**转发了@${retweeted_screen_name}**
${retweeted_text}
`;
}
weibo_quote += `[微博链接](${sourceUrl})` + "\n\n";
// Markdown 格式的图片链接
weibo_quote +=
imageNames.length > 0 ? imageNames.join("\n") + "\n\n\n" : "" + "\n\n\n";
这部分代码在 Scriptable 中的情况如截图所示
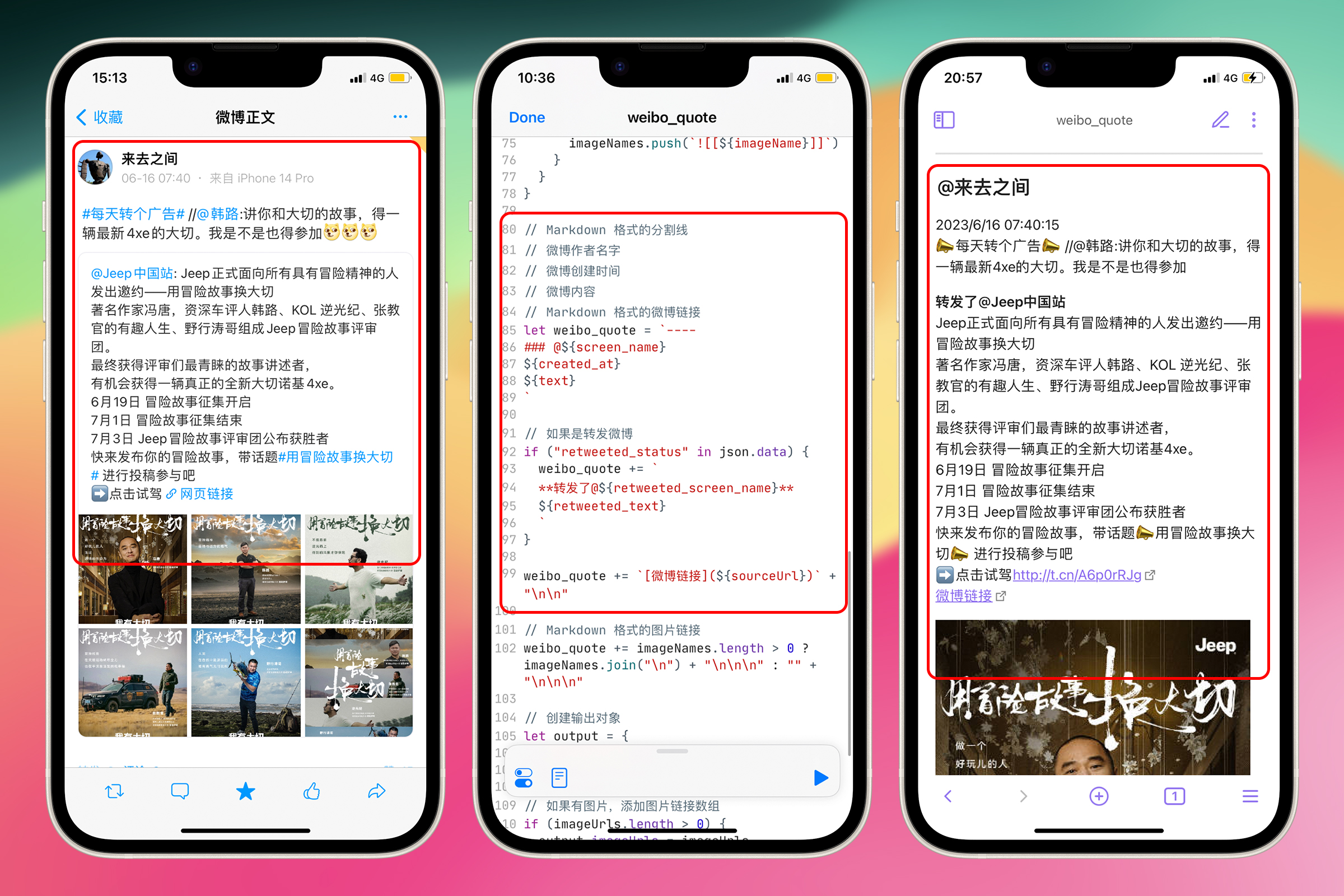
至此,保存各种微博的自动化流程就制作好了。即使是保存长文 + 16 张配图的微博也不在话下。
回顾
文章中顺着保存微博为主线,零零碎碎介绍了多个关键的编程概念,在此总结回顾一下:
- JSON 对象取值:JSON 是一种轻量级的数据交换格式,易于人们阅读和编写。可以通过属性名称来访问 JSON 对象的值。
- 数组:用于存储多个值的特殊变量。可以通过索引访问和修改数组中的元素。
- 字符串处理:如
split、replace等,用于进行字符串操作。 - 模板字符串:允许嵌入变量的字符串。来更方便地构造字符串。
- 日期对象类型:用来获取和设置日期与时间。
- 正则表达式:使用它们进行字符串搜索和替换操作。
- 循环:用于重复执行代码块,直到循环结束为止。
- 条件判断:用于执行基于不同条件的不同操作。
- 创建 JSON:创建 JavaScript 对象,并通过
JSON.stringify方法将其转换为 JSON 字符串。
小结
自动化在现代设备中扮演着越来越重要的角色,不仅在于提升效率,而且在于创造出更丰富、更具个性化的用户体验。对于 iOS 和 macOS 用户来说,Shortcuts 和 JavaScript 都是实现自动化的重要工具。借助 Scriptable 可以在 iOS 上运行 JavaScript 代码,使得熟悉编程语言的玩家可以以更熟悉和快捷的方式来创建自动化任务。
作为一种底层的技术,JavaScript 已经深入地渗透到了各种应用中。从复杂的互动网站,到功能丰富的移动应用,再到强大的服务器后台,都离不开 JavaScript 的支持。随着技术的发展和社区的繁荣,JavaScript 的未来将更加广阔,应用场景将更加多元。

附录
使用官方客户端生成的链接
分析请求地址
建议先阅读完前文奇点客户端的方案,了解一些必要的概念后再继续阅读。
官方客户端不支持 Share Sheet,只能复制链接然后运行 Shortcuts。
复制出来的地址是https://weibo.com/1111681197/4913161368765497 这样的。这个链接的含义同样是:https://weibo.com/作者 id/微博 id
复制到浏览器中,打开浏览器开发者工具,刷新。然后搜索这条微博的中的关键词,找到了所需的内容。但是 Response 中的文本格式看起来不像 JSON。
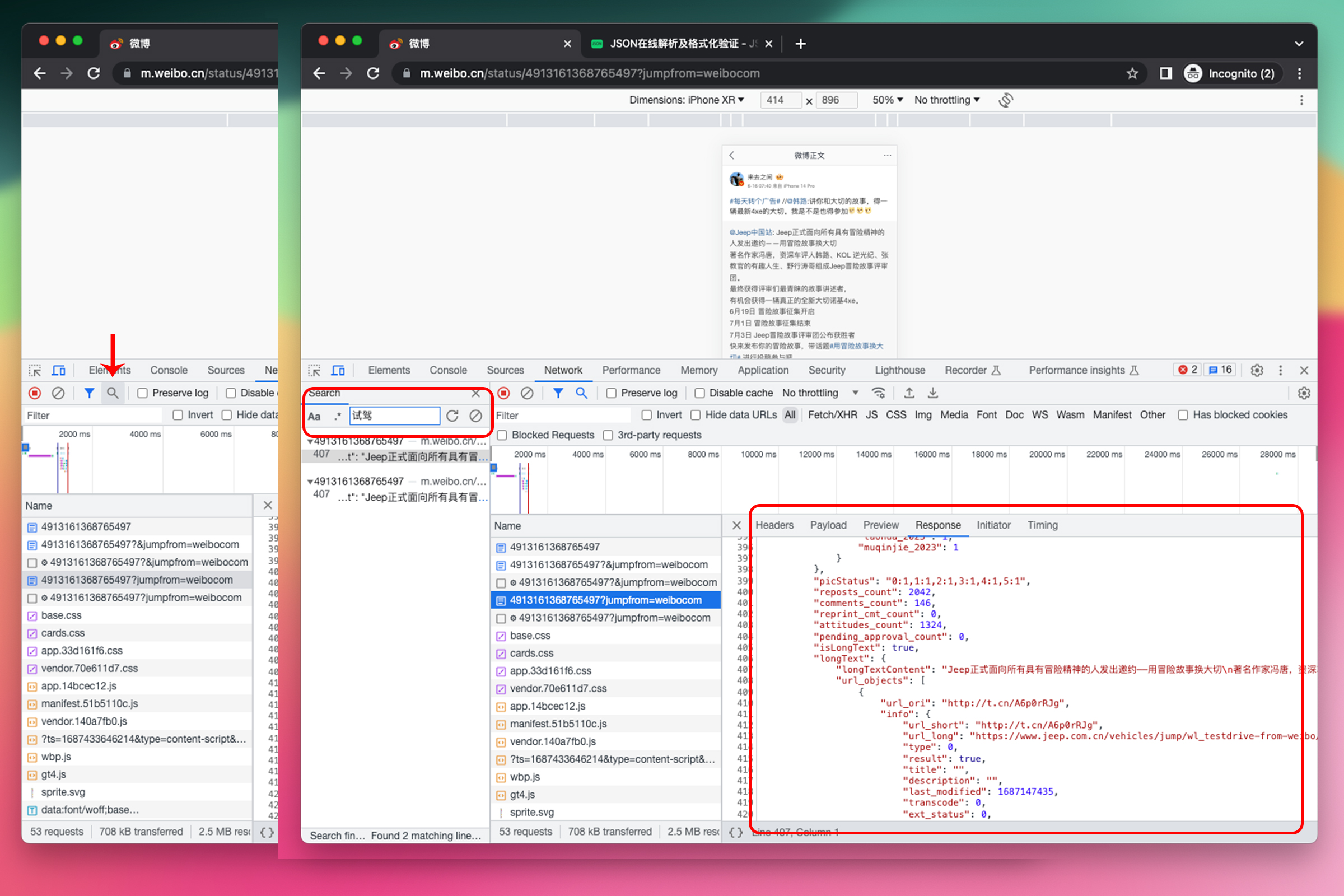
点击 Headers 查看请求头
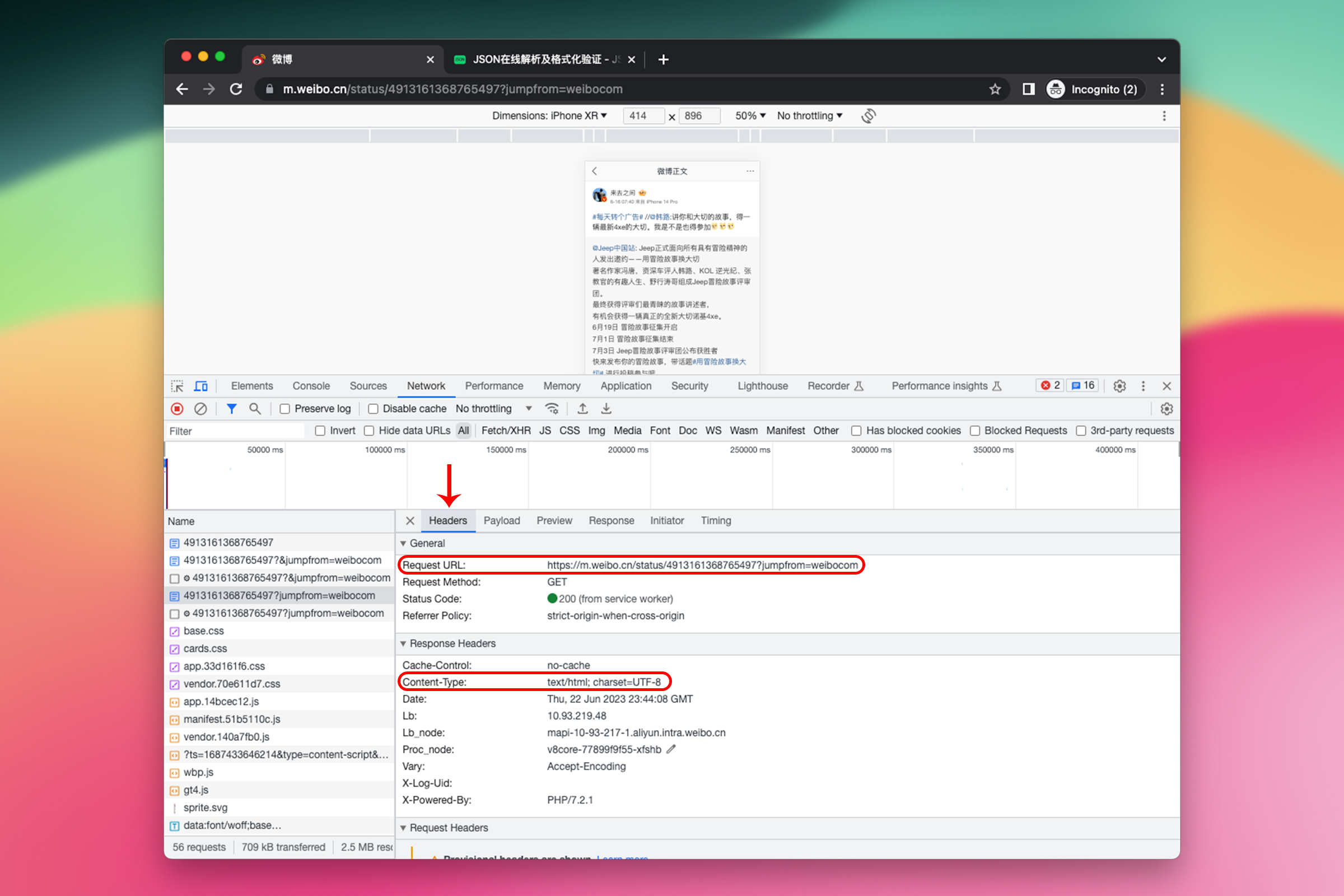
可以看到请求的地址是 https://m.weibo.cn/status/4913161368765497?jumpfrom=weibocom,Content-Type(内容类型)是 text/html,这个请求地址返回的果然不是 JSON,而是 HTML。
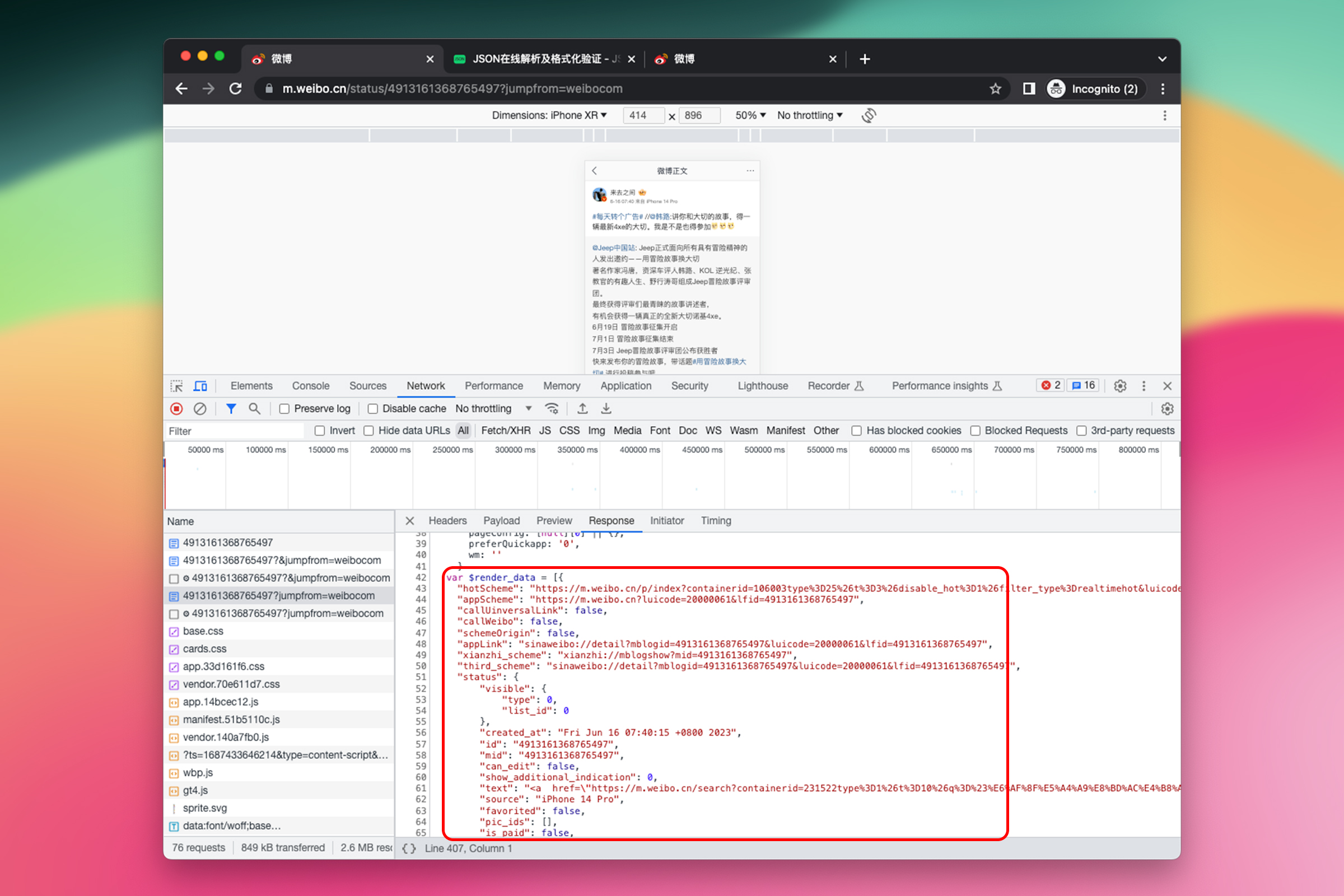
回到 Response 继续观察,发现虽然返回的是 HTML 文本,但是在 HTML 文本中有完整的 JSON 文本,结构几乎与直接返回的 JSON 文本差不多。
那现在就好办了,直接用正则表达式从 HTML 文本中提取 JSON 文本,然后再从 JSON 文本中直接取内容。要匹配的范围是 $render_data = [...] || {};。
使用 JavaScript 获取微博内容
在 Scriptable 中新建一个脚本,命名为 official_weibo_quote,先来进行测试,用 JavaScript 代码将整个流程跑通,然后再与快捷指令结合。
let sourceUrl = "https://weibo.com/1111681197/4913161368765497";
let mid = sourceUrl.split("/").at(-1);
let htmlUrl = `https://m.weibo.cn/status/${mid}?jumpfrom=weibocom`;
let req = new Request(htmlUrl);
let html = await req.loadString();
let scriptPattern = /\$render_data = \[(.*?)\]\[0\]/s;
let match = html.match(scriptPattern);
let dataString = match[1];
let data = JSON.parse(dataString);
console.log(data.appScheme);
第 1 行代码:创建一个 url 地址
第 2 行代码:调用 split("/") 方法将 sourceUrl 分割成多个部分,然后使用 at(-1) 方法取出最后一部分(即微博的 id)
第 3 行代码:使用模板字符串构造了 HTML 请求链接。
第 4 行代码:创建了一个 HTTP 请求,目标链接是htmlUrl。
第 5 行代码:将返回的 HTML 响应作为字符串保存在 html 变量中。
第 6 行代码:创建一个正则表达式
\$render_data = \[:匹配文本中的$render_data = [部分。这里$和[都需要进行转义,因为它们在正则表达式中有特殊的意义。(.*?):这是一个“捕获组”。. 匹配任意字符,*表示匹配前一个元素零次或多次,?使得*变为非贪婪模式,也就是只匹配最小的满足条件的文本。\]\[0\] \|\| {};:匹配文本中的][0] || {};部分。这里]、[、|都需要进行转义。{}符号不需要进行转义,因为它没有紧接在一个字符或者一个括号之后,只是普通的字符{和}第 7 行代码:在 html 中寻找与scriptPattern匹配的部分 第 8 行代码:从匹配结果match中取出捕获组,即正则表达式中(.*?)这部分匹配到的字符串。match[0]是匹配正则表达式的整个字符串。match[1]是捕获组。 第 9 行代码:将 dataString 从 JSON 格式字符串转化为 JavaScript 对象 第 10 行代码:在控制台中打印出data对象的appScheme属性。
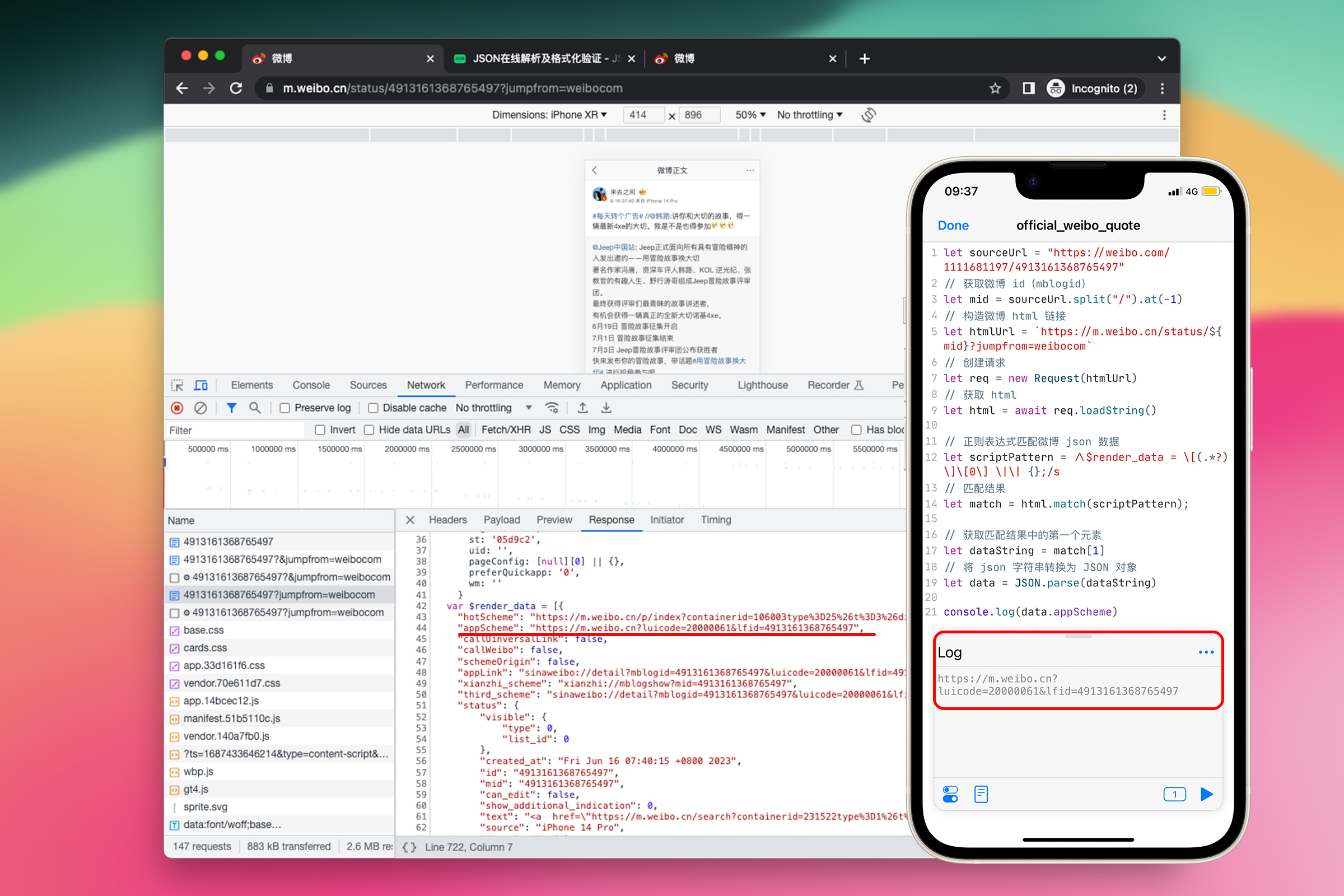
运行一下试试,成功获取到 JSON 后,剩下的事情就好办了。从浏览器复制 HTML 中的 JSON 文本,到 json.cn 格式化看一下。注意复制时保持 JSON 文本的完整性,不要漏掉 {}。
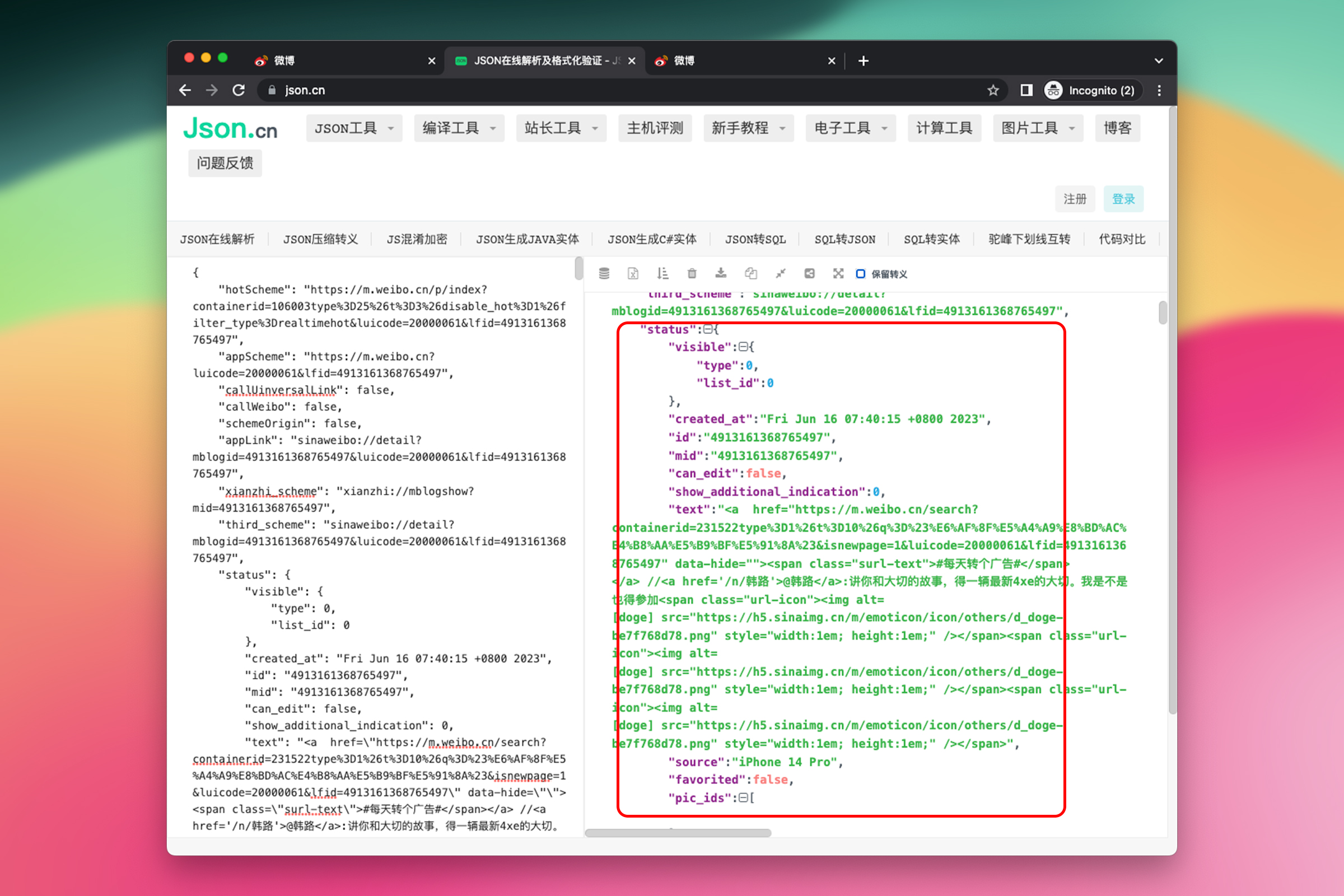
与之前 JSON 唯一差别是所有内容都在 status 层级下,把之前的代码从let id = json.data.user.id 开始一直到末尾全都拿过来,修改一下属性的层级即可复用。在电脑端的文本编辑器中将所有的 json.data 替换为 data.status。
在代码末尾加上一行 console.log(output) 来观察一下输出
用 Shortcuts 保存微博
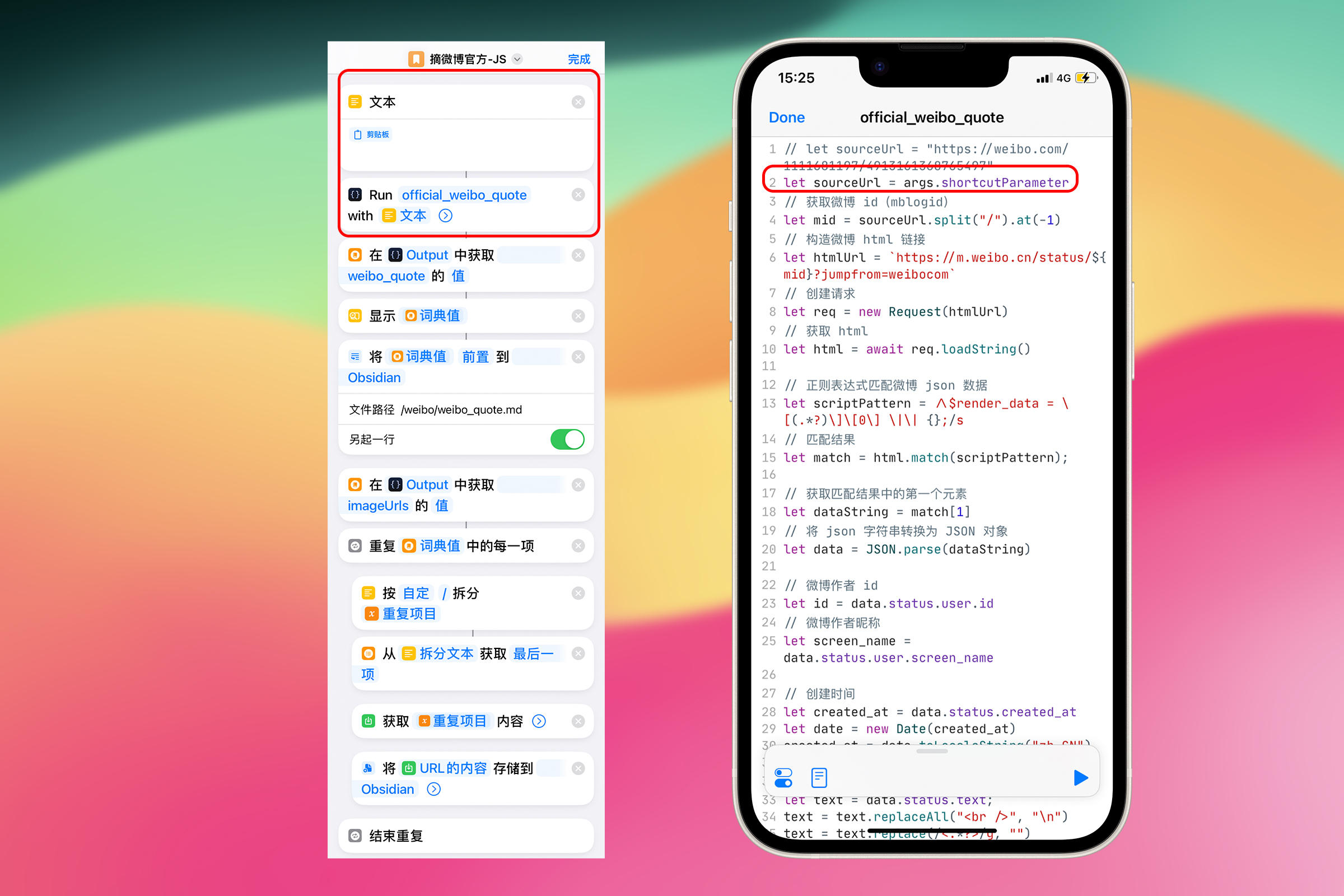
获取到微博内容后,就可以使用 Shortcuts 来保存了。Run Script 动作之后的流程与前文一致。只有开头做一点改动,因为我们是通过剪贴板运行,而不是 Share Sheet。
由于 Run Scriptable 动作的限制,似乎不能直接将 剪贴板 变量放置于 Parameter 处,所以用“文本”动作中转一下。
脚本中的代码也要做一点修改,从固定的测试 url 改为从 Shortcuts 中获取 url,将第一行代码改为 let sourceUrl = args.shortcutParameter
至此,从官方微博客户端保存微博内容的流程就制作好了。
使用 Scriptable 下载图片
下载图片——Scriptable 网络请求
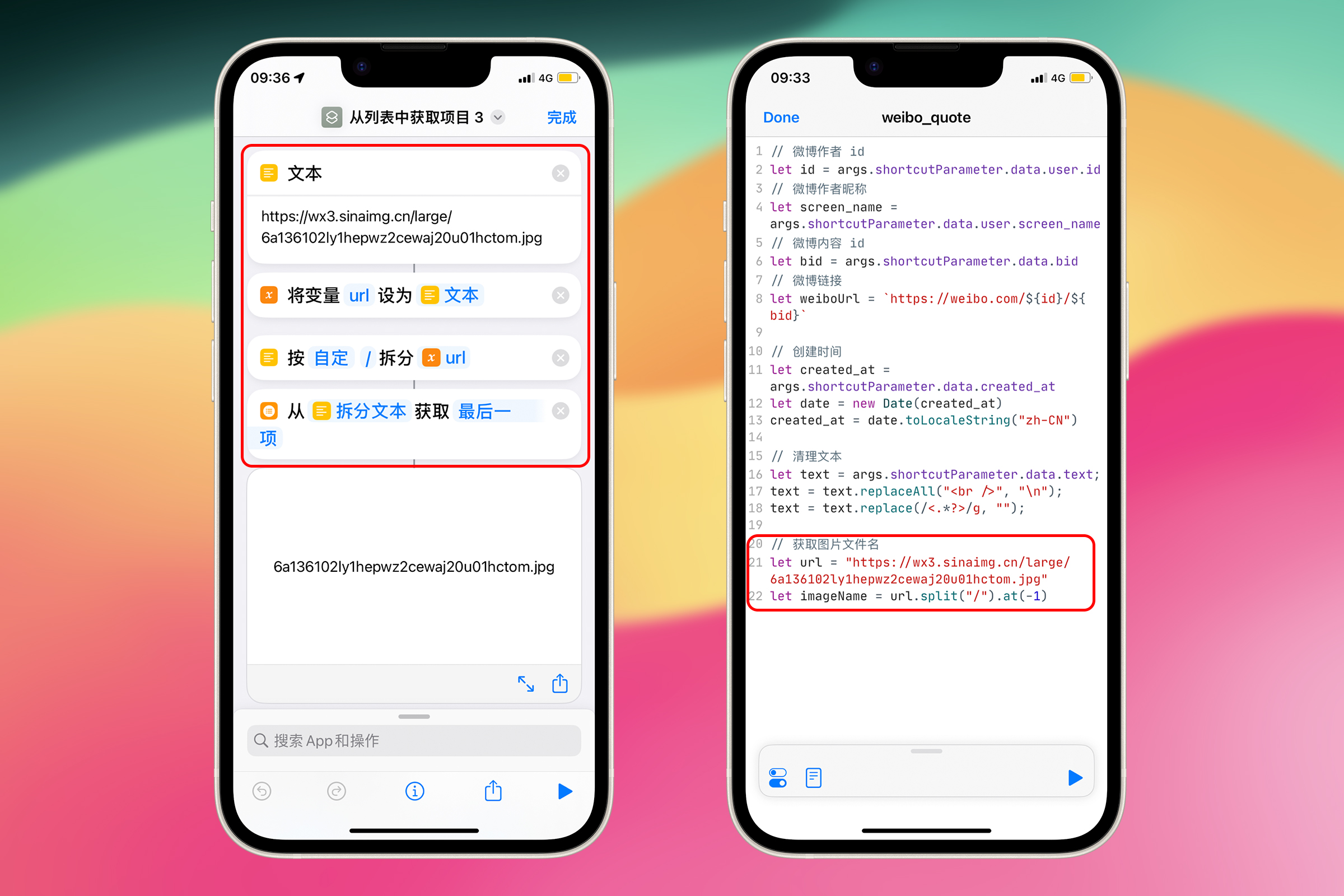
假设我们已经有了图片地址 https://wx3.sinaimg.cn/large/6a136102ly1hepwz2cewaj20u01hctom.jpg
首先根据图片下载地址获得文件名
// 获取图片文件名
let url = "https://wx3.sinaimg.cn/large/6a136102ly1hepwz2cewaj20u01hctom.jpg";
let imageName = url.split("/").at(-1);
第 1 行代码:获取图片下载地址。
第 2 行代码:使用 / 分割文本,然后获取结果中的最后一个元素。
**对应的 Shortcuts 操作:**分割文本、从列表中获取项目
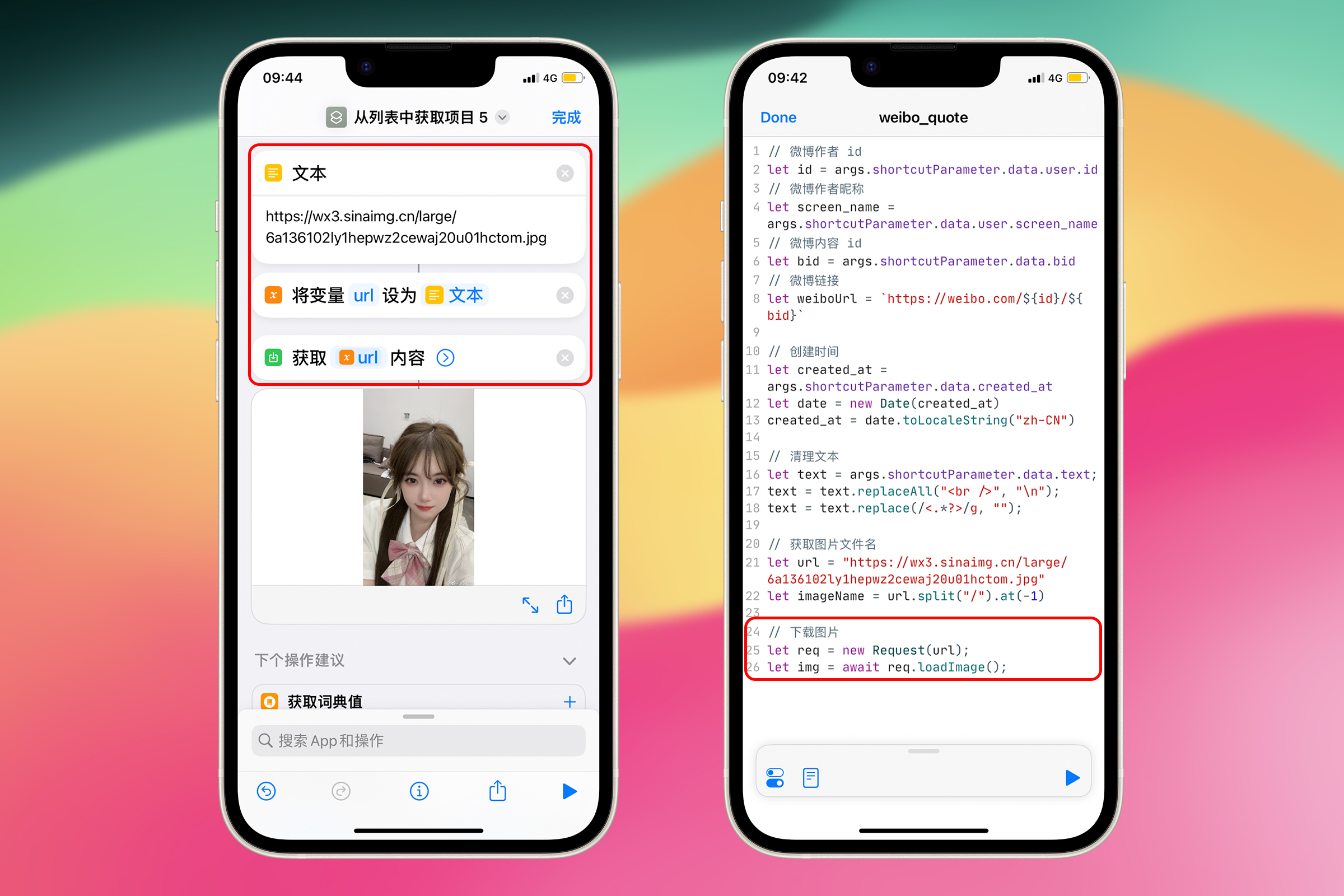
接着下载图片
// 下载图片
let req = new Request(url);
let img = await req.loadImage();
第 1 行代码:使用 new 关键字创建了一个的 Request 对象,其中 url 是想要下载图片的网址。在 Scriptable 中,Request 对象用于处理 HTTP 请求。
第 2 行代码:发送了 HTTP 请求并等待服务器的响应。loadImage() 是 Request 对象的一个方法,其功能是发送 HTTP 请求来下载指定 url 的图片,并将其以Image 对象的形式返回。这里使用了 await 关键字,让 JavaScript 异步执行,等待 req.loadImage() 这个操作完成(即图片下载完成)后,再继续执行后面的代码。操作完成后,图片数据将被赋值给 img 变量。
**对应的 Shortcuts 操作:**获取 URL 内容
保存图片——Scriptable 文件管理
接下来是保存下载的图片。 因为 iOS 的沙盒机制, Scriptable 要读写其他文件夹必须通过一些特殊的手段。 打开设置——File Bookmarks——添加——Pick Folder(选择文件夹)——选择想要通过脚本访问的目录——设定名称(保持默认即可) 创建一个 File Bookmarks(书签)之后,实际上是在给一个特定的文件或目录创建一个持久的引用。这样就可以在脚本使用书签名称来获取这个目录或文件的路径。 我保存在 Obsidian 目录中,这样可以直接在手机上浏览保存的微博图文。
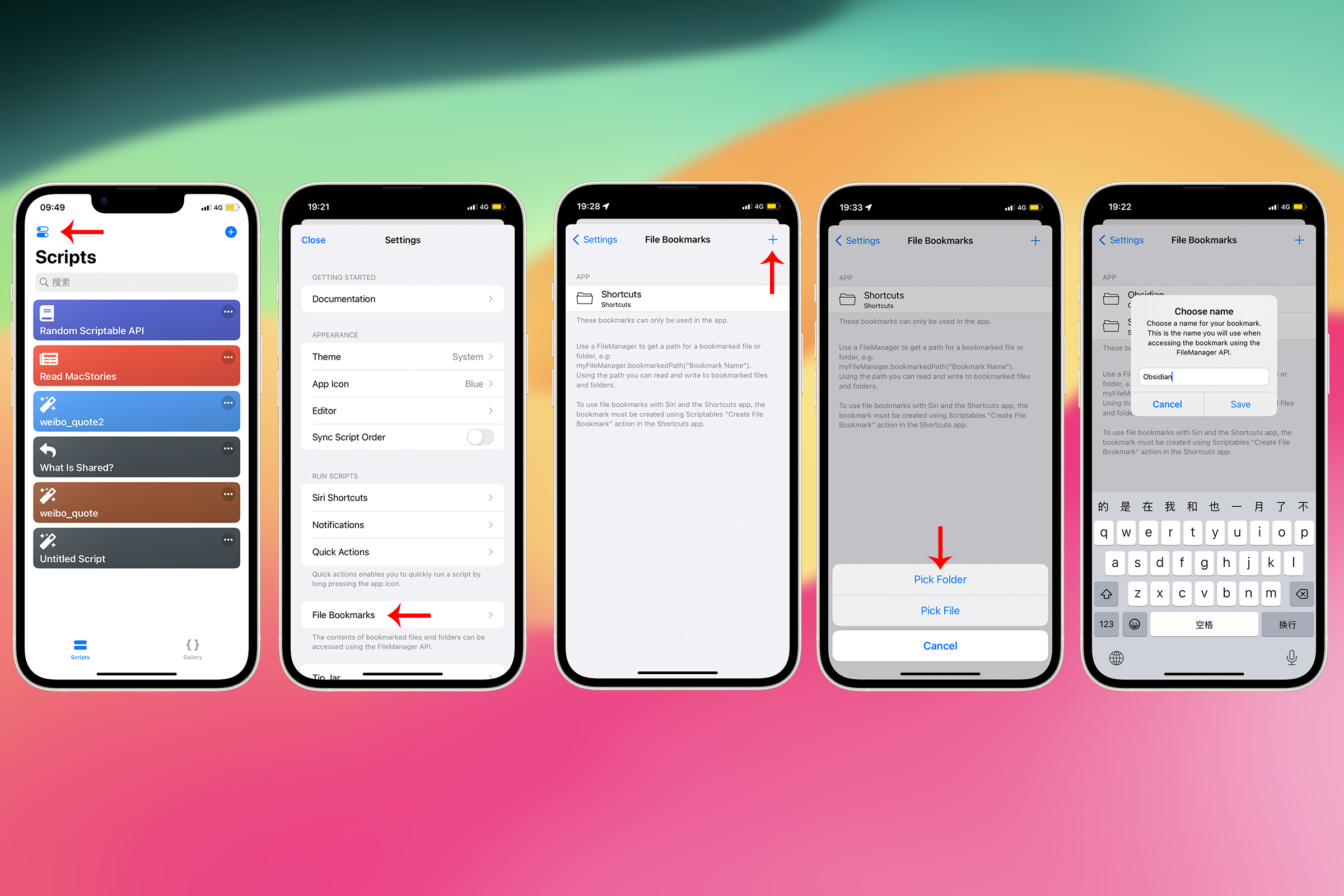
设置好书签之后,就可以编写 JavaScript 代码了。
// 保存图片
let fm = FileManager.iCloud();
let path = fm.bookmarkedPath("Obsidian") + "/weibo/images/" + imageName;
fm.writeImage(path, img);
第 1 行代码:创建了一个 FileManager 对象,用于访问和操作存储在用户的 iCloud Drive 中的文件。
第 2 行代码:创建了一个字符串,表示图片将要存储的路径。首先获取在 Scriptable 的 "File Bookmarks" 设置中被标记为 “Obsidian” 的文件夹的路径,然后将 /weibo/images/ 和图片的文件名 (imageName) 拼接在这个路径的后面,结果就是完整的文件路径。
注意:Scriptable 不能根据路径自动创建不存在的目录(但是 Shortcuts 可以)。所以,要先在 Obsidian 目录中创建好 weibo 文件夹,然后在 weibo 文件夹中创建 images 文件夹。
第 3 行代码:使用 FileManager 对象的 writeImage 方法将图片写入指定的路径。path 是刚刚定义的文件路径,img 刚才从网络上下载的图片。
**对应的 Shortcuts 操作:**存储文件。 这里 Shortcuts 操作比较简单,只需要一个动作,为我们省了不少事。
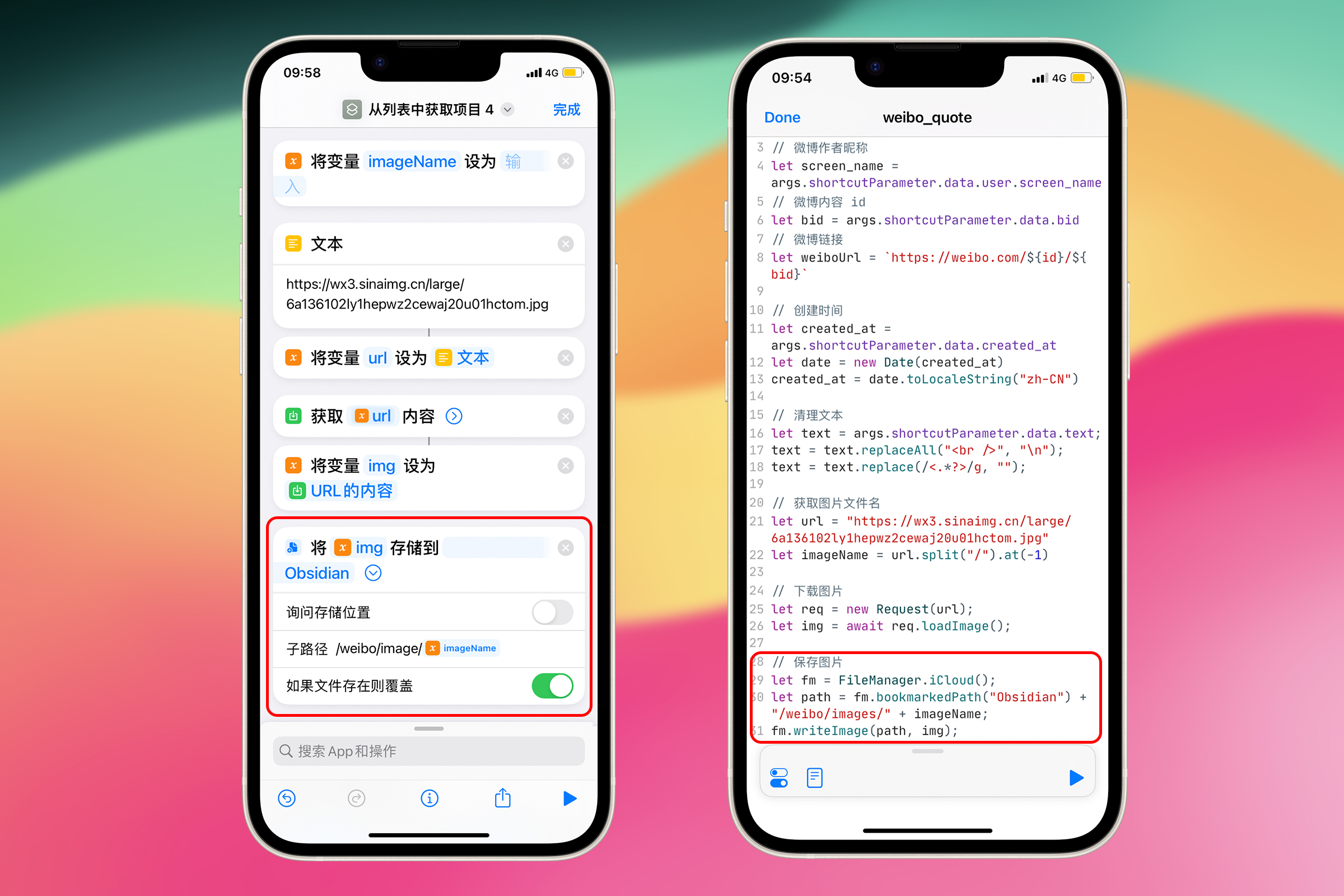
至此,下载和保存图片的代码就写好了,全部代码如下所示
// 获取图片文件名
let url = "https://wx3.sinaimg.cn/large/6a136102ly1hepwz2cewaj20u01hctom.jpg";
let imageName = imageUrl.split("/").at(-1);
// 下载图片
let req = new Request(url);
let img = await req.loadImage();
// 保存图片
let fm = FileManager.iCloud();
let path = fm.bookmarkedPath("Obsidian") + "/weibo/images/" + imageName;
fm.writeImage(path, img);
使用 Scriptable 保存文本
// 获取 FileManager 对象
let fm = FileManager.iCloud();
// 设置 markdown 文件的路径
let markdownPath = fm.bookmarkedPath("Obsidian") + "/weibo/weibo_quote.md";
// 读取文件的内容
let fileContent = fm.readString(markdownPath);
// 将新的文件内容写入文件
fm.writeString(markdownPath, weibo_quote + fileContent);
与前面保存图片类似,需要先创建文件对象并且指定路径,然后写入内容。而且目前 Scriptable 不支持直接向现有文件追加内容。需要首先读取原始文件的全部内容,然后把新的内容添加到读取到的原始内容后面,最后将合并后的内容写入文件。 如果你需要追加内容到一个非常大的文件,那么首先需要将这个大文件的全部内容加载到内存中,这可能会消耗大量的内存。
Shortcuts 在保存文件方面要更加简单,应该根据情况灵活选择使用 Shortcuts 或 JavaScript。
测试 Scriptable 输出的 3 种方式
在使用 Scriptable 进行编程时,常常需要测试,主要有以下三种方式进行输出测试。
使用 console.log
let text = "This is a message.";
console.log(text);
通过 console.log() 将信息输出到日志面板。但这个输出只能进入代码编辑界面才能看到。
使用 Alert 对话框 以信息以弹窗的方式展示出来。
let alert = new Alert();
alert.title = "Alert Title";
alert.message = "This is a message.";
await alert.presentAlert();
使用 Notification 通知 将信息以通知的方式展示出来。
let notification = new Notification();
notification.title = "Notification Title";
notification.body = "This is a message.";
notification.schedule();

Scriptable 的功能与限制
总的来说,Scriptable 与一般的 JavaScript 运行环境存在一些关键性的区别。首先,Scriptable 不允许导入外部包,这限制了其使用范围。其功能也受限于 Scriptable 自身所提供的接口,不能完全使用 JavaScript 的全部特性。 另外,使用 Scriptable 编写的不完全是通用的 JavaScript 代码。在其中有一部分功能是 Scriptable 开发者自定义的,这使得在其他环境下运行可能会出现问题。
尽管 Scriptable 存在这些限制,但其在数据处理方面的效率仍不容忽视。通过有效利用 Scriptable 的特性和接口,我们依然可以创建出强大的自动化脚本,优化自动化流程。