自 macOS 和 iOS 引入 Live Text 以降,OCR 引擎逐渐成为很多操作系统的自带组件,而成熟的商业 OCR 引擎也达到极高的精度。然而,无论配备人工智能的最新款 iPhone 还是价格令人咋舌的商业软件,在多语言环境中都常常出现“打击错误”:辛辛苦苦等上半个时辰,好不容易识别完几百页的书,结果发现语言没选对,识别出来一堆乱码(如果不是全部的话)。
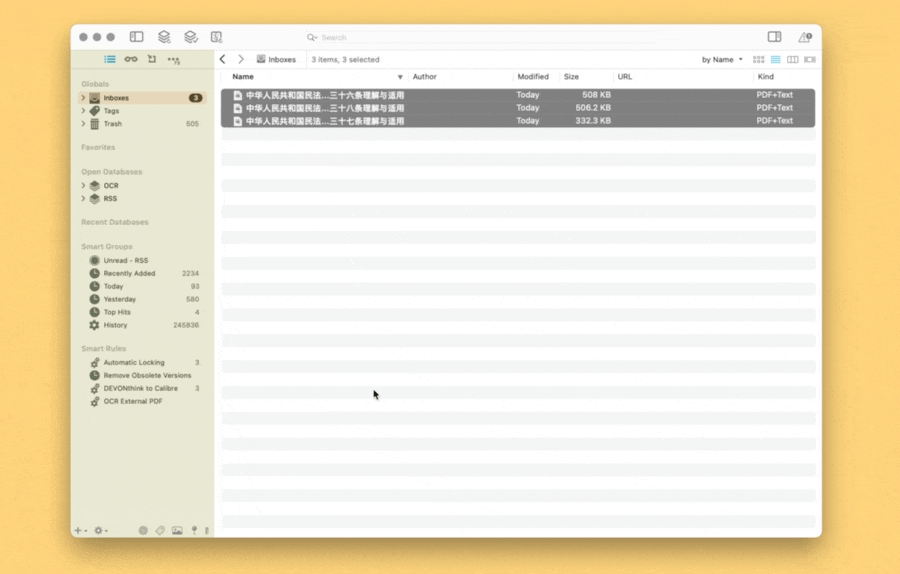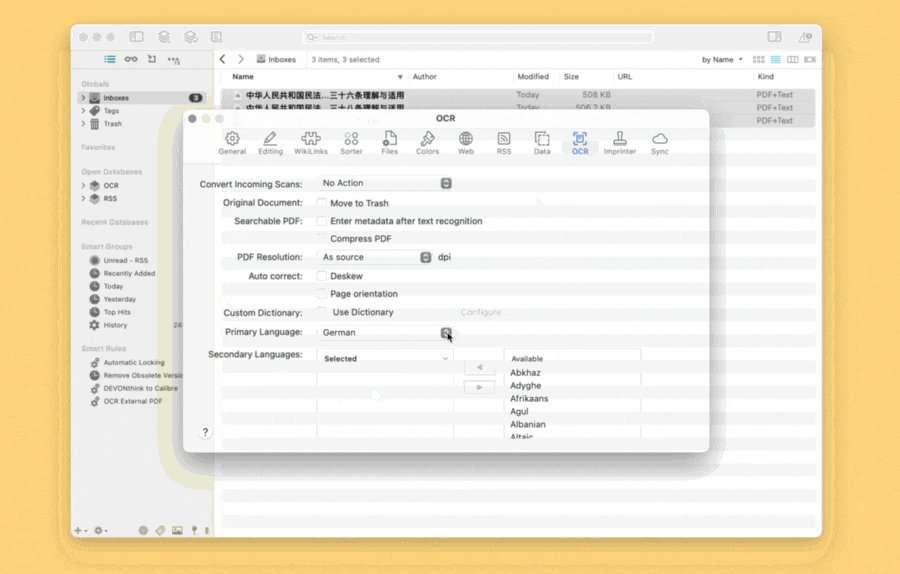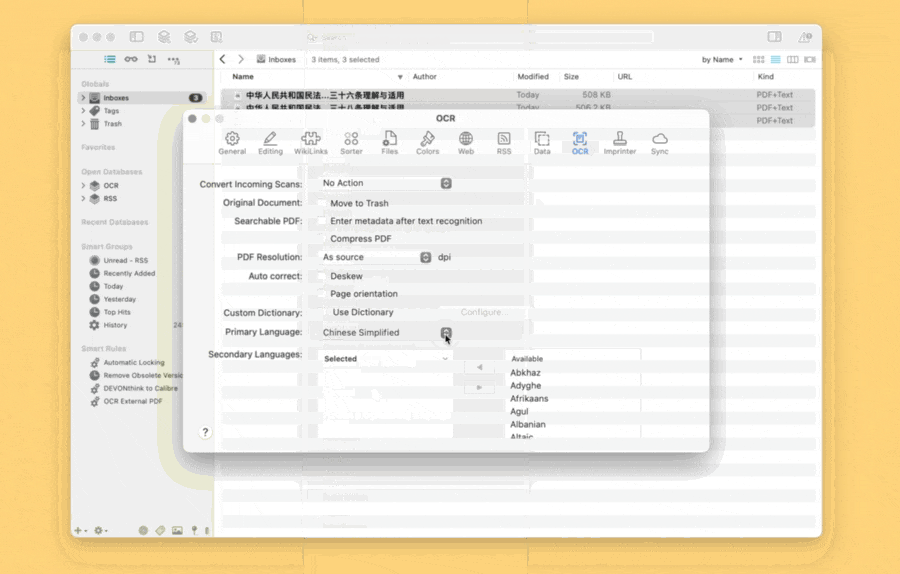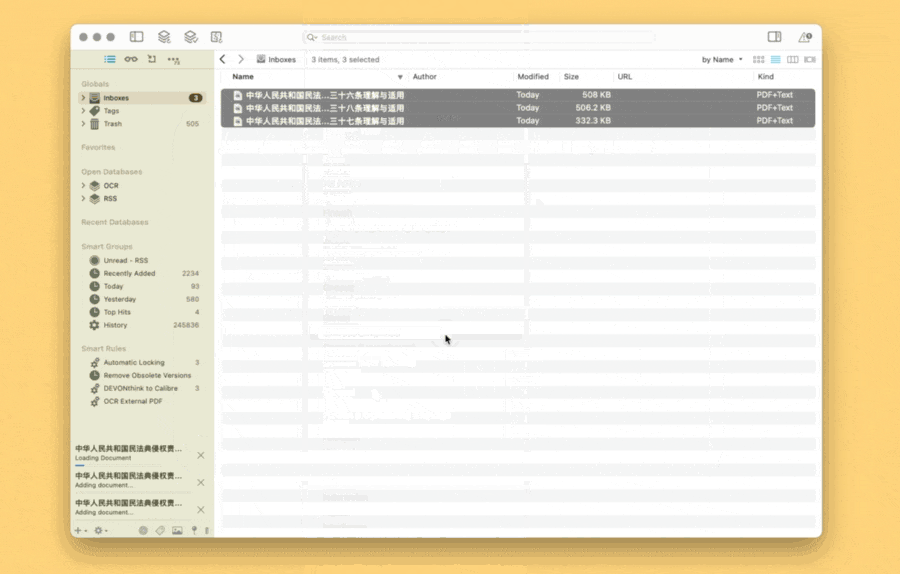
虽然不少软件都自称可以自动判断材料的语言^1,但实际效果非常糟糕。例如 DEVONthink,它早就支持预设多种语言,但官方也承认选对语言才能保证精度。^2既然不能自动,那能否退而求其次?很可惜,DEVONthink 的语言选项藏在设置界面中,不能通过脚本或命令行调整,结果就是每次处理 PDF 时,绝大多数人恐怕都不会特意检查语言。十多年前就有人想要更简单的语言设置,但直到近年依然无果。
从底层技术一路退到表层的交互界面后,我不得不引入自动化工具,用 Keyboard Maestro 重构 DEVONthink 的 OCR 交互。在新设计的交互中,我依托 Keyboard Maestro,每次 OCR 文件前都会弹出语言选择界面,选好退出后再继续处理文件,以免白费算力和时间。