
DeepSeek 掀起了一阵本地部署的热潮,越来越多的人开始关注如何将强大的语言模型直接部署到自己的电脑上。
对于程序员来说,使用 Ollama 通过命令行部署模型并不难,但对大多数人来说,命令行的复杂配置和繁琐的操作可能让人望而却步。好在现在有了 LM Studio 这样的图形化工具,普通用户也能轻松搞定模型的本地部署。
通过 LM Studio,不需要任何编程基础,你就能在自己电脑上运行 DeepSeek R1 模型,随时随地和它对话,甚至可以将它集成到自己的应用中。
本文就以 LM Studio + Lobe Chat 为例,完全在本地实现一套实用又美观的 DeepSeek 方案。
通过 LM Studio 部署和使用 R1 模型
先了解一下 LM Studio,这是一款图形化界面的应用,专为简化本地部署和使用大型语言模型而设计。它自动检测你的电脑硬件,并根据配置推荐适合的模型,极大地降低了技术门槛。
安装 LM Studio:首先,你需要从 LM Studio 官网下载并安装该应用。安装过程非常简单,按照提示完成即可。
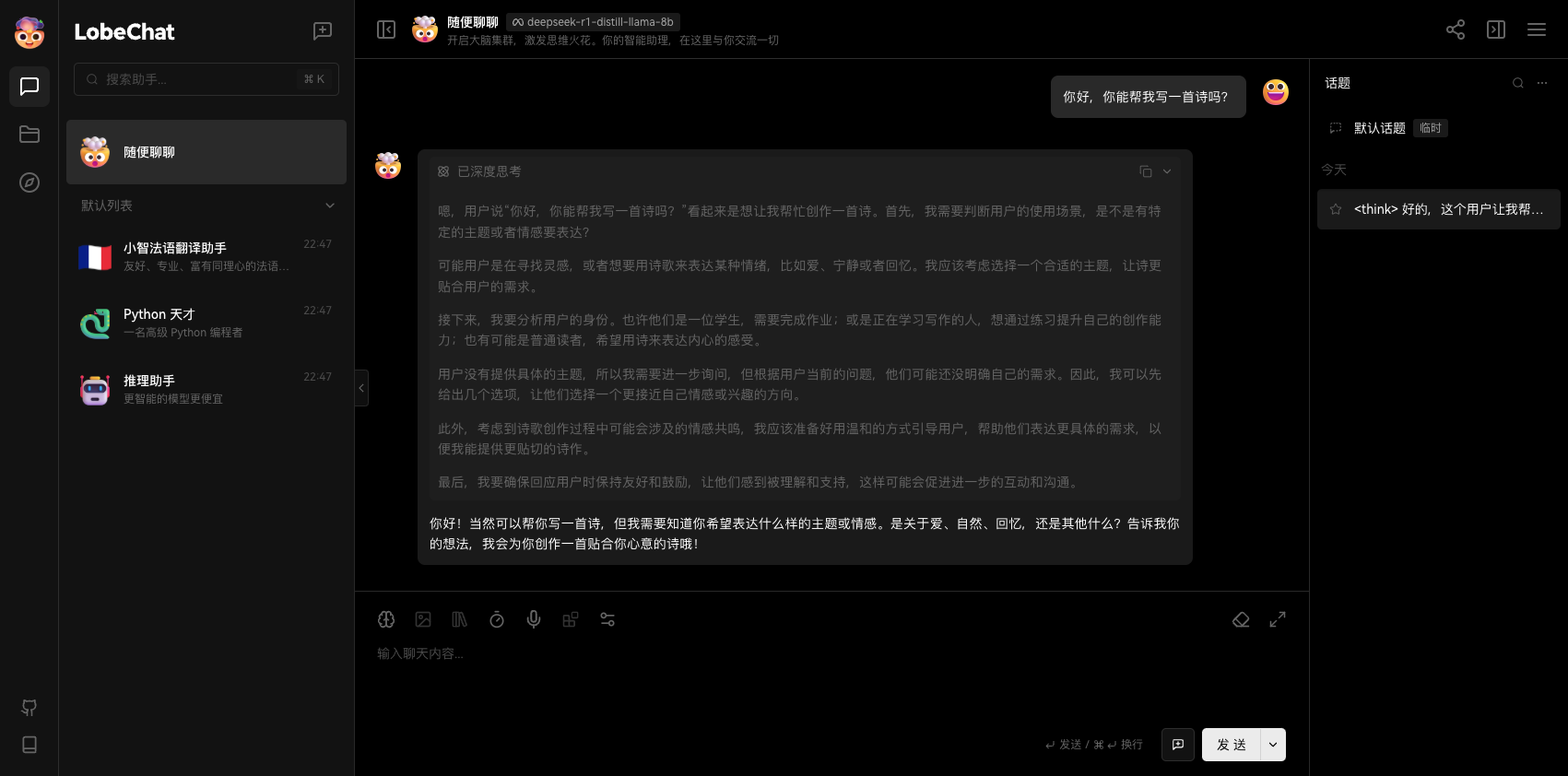
选择和下载模型:启动 LM Studio 后,点击左侧的“搜索”图标。在这个界面里搜索“DeepSeek R1”,可以看到结果中出现了 DeepSeek R1 Distill (Qwen 7B) 和 DeepSeek R1 Distill (Llama 8B) 这两个版本(Distill 的意思是蒸馏版)。
LM Studio 会根据你的电脑配置自动推荐适合的模型。以我使用的 Mac mini M4 为例,它会推荐适合该硬件的 Llama 蒸馏版 8B 模型。所以你只需要点击右下角的 Download 即可(这里我已经下载了显示的是 Use in New Chat)。
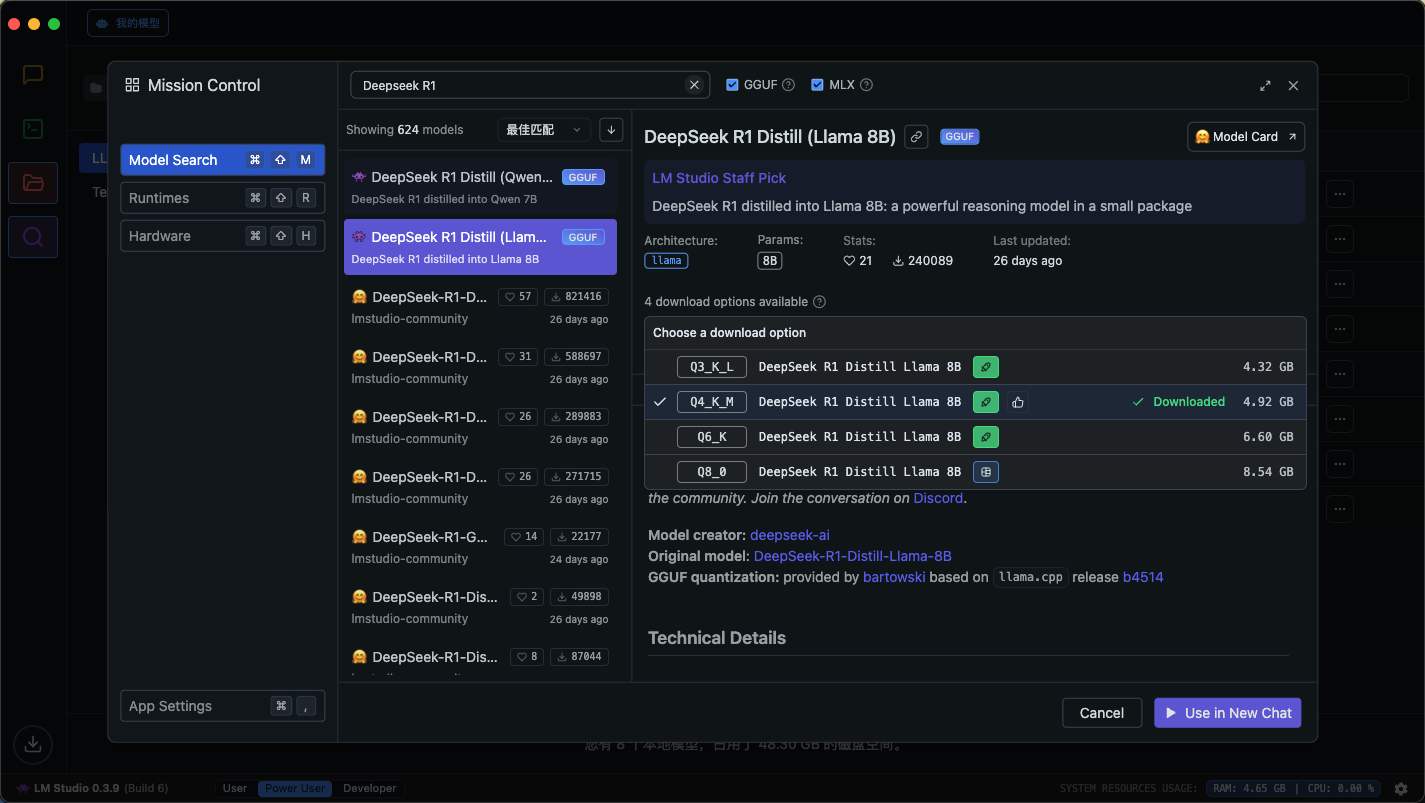
启动模型:下载完成后,点击 LM Studio 顶部的下拉框,选择刚刚下载好的模型,然后点击“加载模型”即可,LM Studio 会自动为你部署模型。
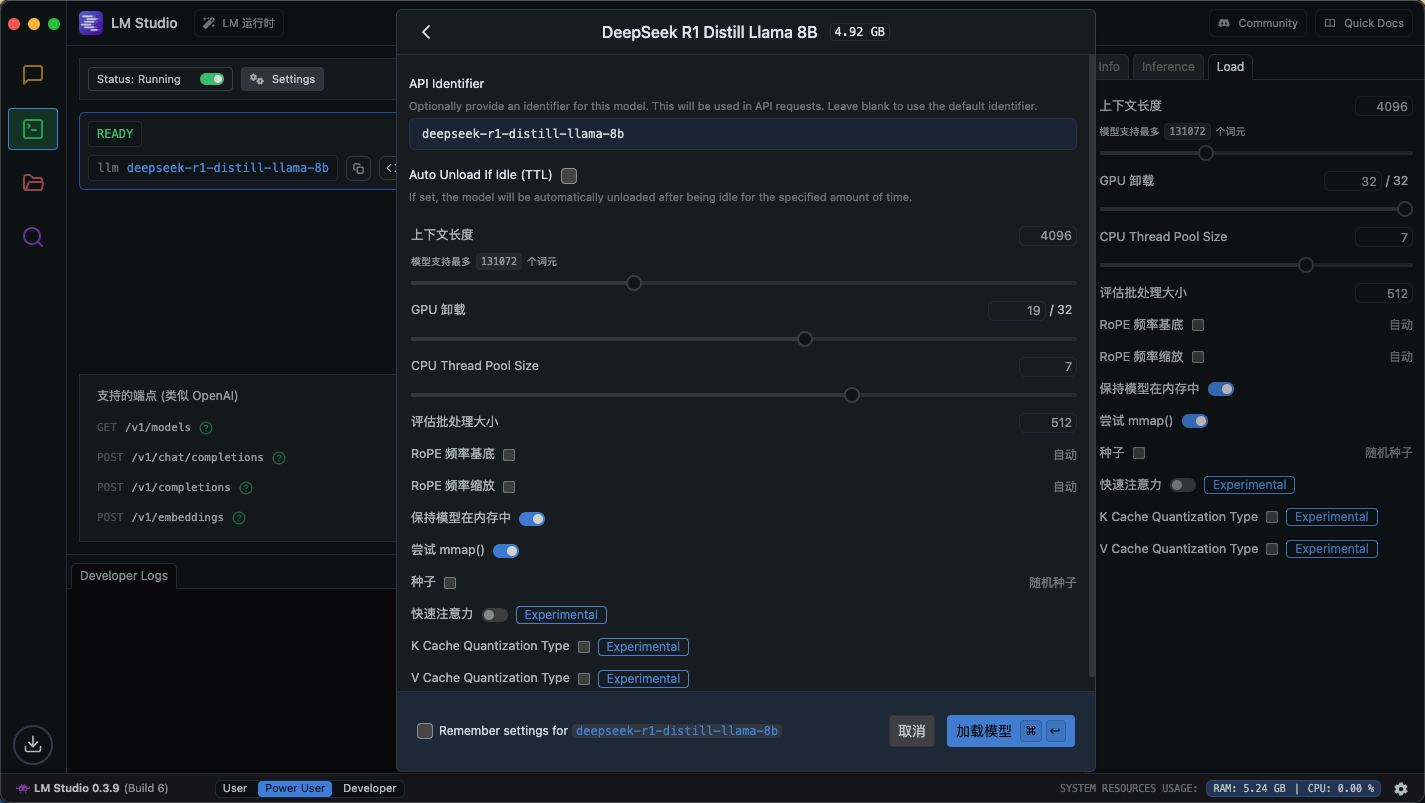
完成后,就可以点击左侧的聊天图标,进入对话界面了。LM Studio 提供了一个对话界面,你可以直接与 DeepSeek 对话。
关于模型参数量和精度等级
这里需要补充一些小知识,大语言模型的表现与模型的参数息息相关,7B 中的 B 就是 Billion,即 70 亿参数量。
模型下载列表中显示的 Q3_K_L 和 Q4_K_M 这些信息,是指 gguf 格式的模型量化时的精度等级,Q3_K_L 表示将权重量化为 3 位精度,而 Q4_K_M 则表示量化为 4 位精度。这个指标通常用于减少模型大小和加速推理速度。
- 你可以在这里了解更多精度等级的相关知识:GGUF quantizations overview · GitHub
我们在一台个人电脑上能用的模型通常在 1.5B ~ 70B 之间,而官网提供的是高达 671B 参数量的满血版本。因此两者的表现是一定会有差异的。
所以,我们在网上看到的各种“部署什么规格的模型需要什么显卡配置的表格”版本非常多,且极有可能是 AI 生成。因为你的电脑可能跑不起 14B 的 Q8 但可以跑得动 70B 的 Q2,这都是有可能的。
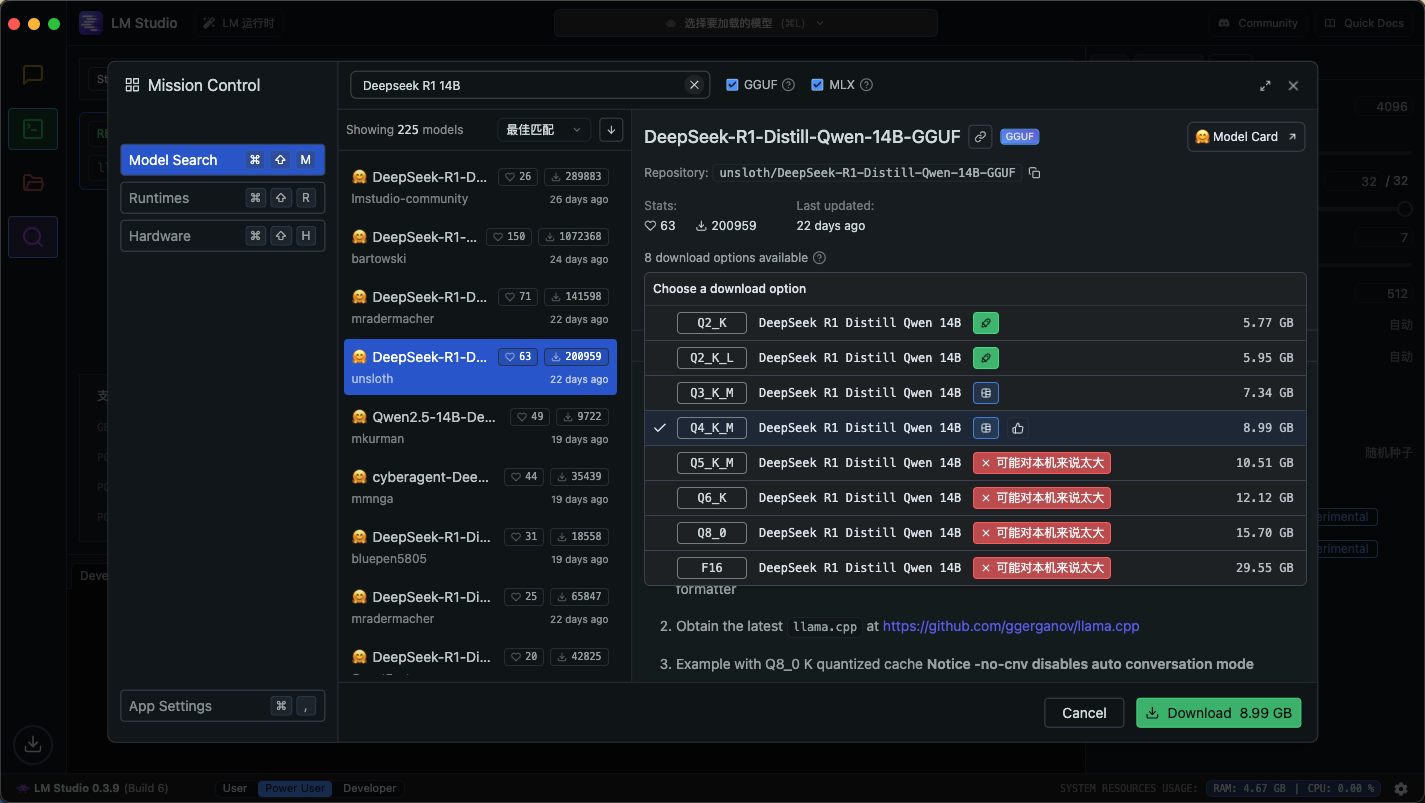
LM Studio 在这方面给了充分的参考,告诉你应该下载哪个版本的模型。我的建议是根据它提供的建议进行选择。即使你能勉强跑的动“过大”的模型,也可能会出现输出过慢之类的问题。
进阶操作:开放 API 进行第三方集成
如果你希望将 DeepSeek R1 的功能应用到其他软件或服务中,LM Studio 也提供了 API 支持,可以将模型作为 API 开放出来。这样,你就可以通过接口与本地部署的模型进行交互了。
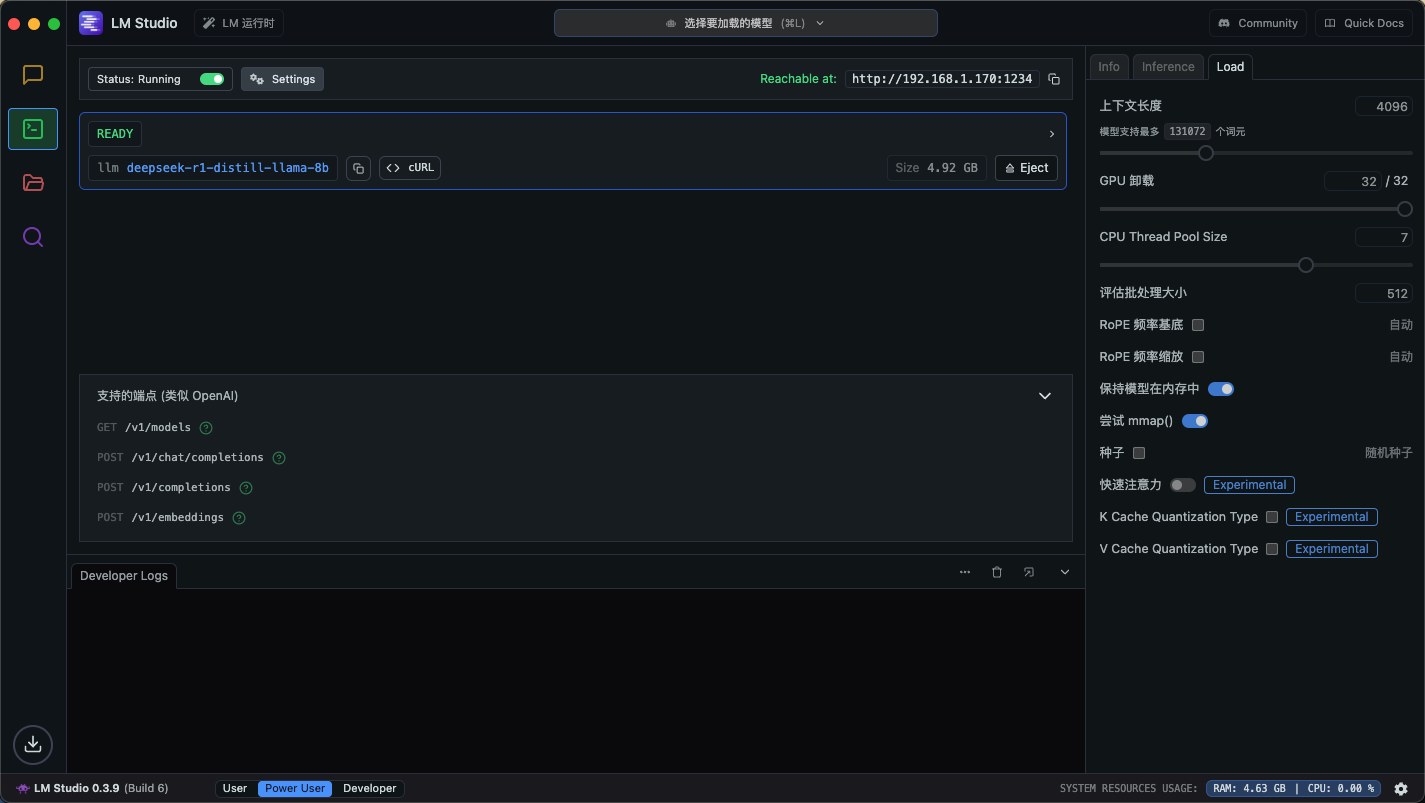
启用 API 服务:在 LM Studio 中,点击左侧的“终端”图标,点击 Status 开关,就可以启用 API 服务。系统会自动为你生成一个 RESTful API 服务。通常开放在 http://内网IP:1234 上(显示在右侧)。
案例:使用 Docker 部署 LobeChat 来接入本地模型
如果你希望进一步增强本地环境的功能,或是需要更强大的聊天平台,可以通过 Docker 部署 LobeChat。
LobeChat 是一个开放源代码的 AI 对话平台,它支持与多种语言模型集成,提供更多的插件和功能。可以去这里了解更多:🔗 Lobe Chat 中文介绍。
本文这里主要介绍如何本地部署 LobeChat 来接入刚刚部署好的 DeepSeek。
部署这个需要用到 Docker,如果你在自己的 Windows、macOS 设备上部署,可以先到 Docker 官网 下载 Docker Desktop 并按照要求安装。
安装完毕后,打开一个终端,运行以下命令来自动拉取和运行 Lobe Chat。
docker run -d -p 3210:3210 lobehub/lobe-chat:latest
完成后你就可以进入 http://127.0.0.1:3210 看到对话界面了。
接下来,你需要在设置中配置一个 OpenAI 语言模型,具体配置如下——
- API Key:无,任意填写即可
- API 代理地址:http://host.docker.internal:1234/v1
- 使用客户端请求模式:关闭
- 模型列表:输入 deepseek-r1-distill-llama-8b 后手动添加
最后检查一下是否可以正确连接。
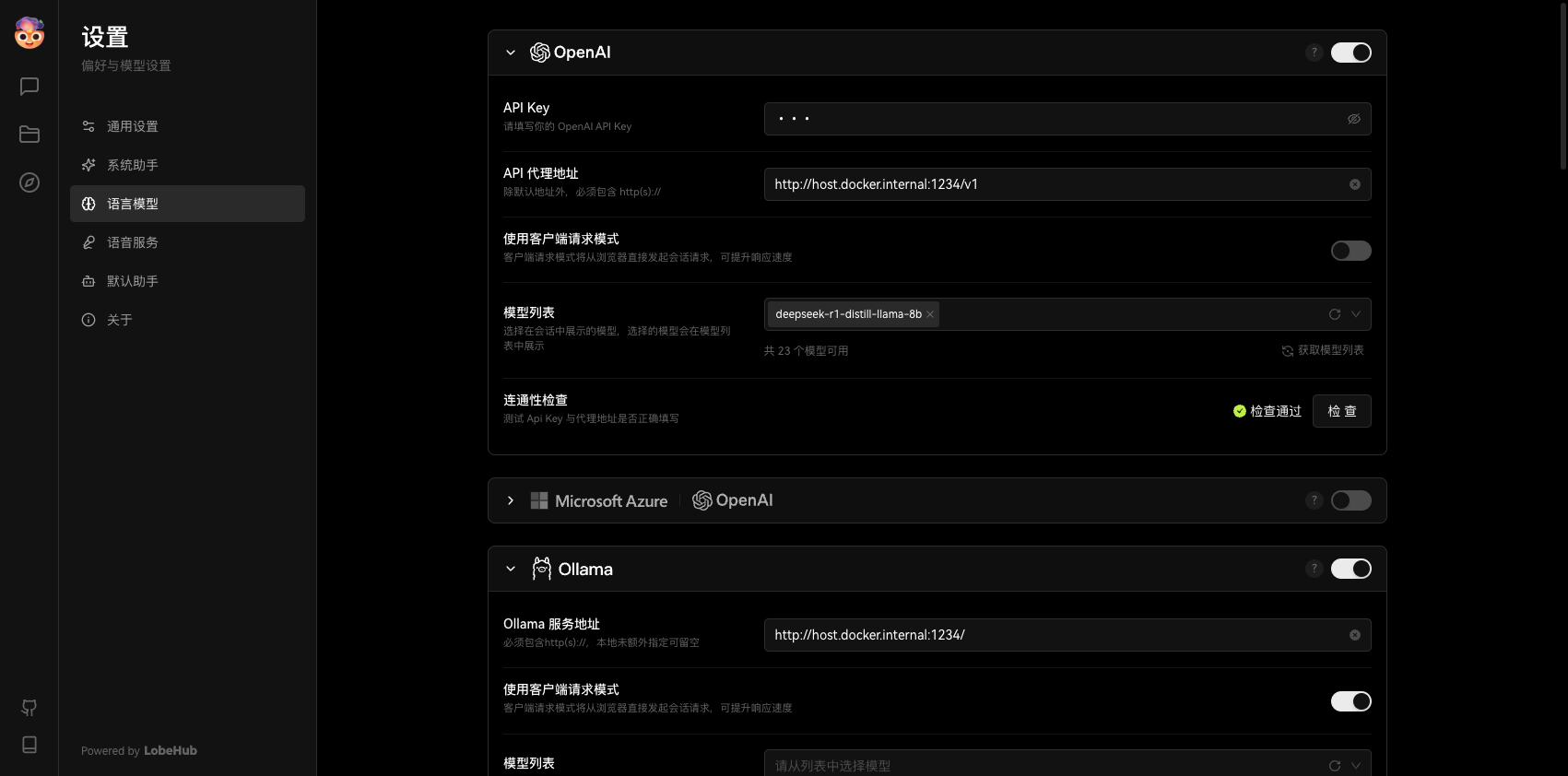
LM Studio 采用了 OpenAI 兼容接口,所以只要是“允许自定义 API 代理地址”+“自定义模型名称”的服务,都可以借用 OpenAI 连接器来实现连接,无需找单独的 LM Studio 接口。
这样你就实现了用外部服务去连接本地模型的功能,不过 DeepSeek R1 模型目前暂时不支持 Function Calling,导致无法使用 LobeChat 中的插件功能。
Lobe Chat 在 2025 年 1 月 15 日的 PR 中正式添加了对 LM Studio 的支持,不过目前暂时没有正式上线,具体原因可以查看开发者的回复,大意是这是一个 Breaking Change,还需要一些时间。
更多用途
此外,你也可以在 VSCode + Continue 的组合中配置 DeepSeek,来实现本地模型的问答。
你也可以通过部署一个 DDNS-GO、FRP 等服务,来实现公网映射,这样就可以把自己的模型暴露到公网,通过公网的服务直接使用。
小结
使用 LM Studio 部署和使用 DeepSeek R1 模型非常简单,即便是零基础的用户也可以通过图形化界面快速上手。你可以直接与模型进行对话,或者通过 API 将其集成到其他应用中。不再被“服务器繁忙,请稍后再试”所困扰。