

在 Twitter 上写长 Thread,已然成了博客的替代品,尤其科技行业的名角儿,也多喜欢在 Twitter 上发声。Hum 曾把在微博上写长文的人称作微博艺术家(不过他已经好多年不看微博了),借他雅言,Twitter 上发 Thread 之士,也可以称为推文艺术家。
然而,Twitter 上的内容来也匆匆,去也匆匆,发布者自己一个不爽就随手删了——一句话,Twitter 上的内容,比网页更容易消逝,也就更需要保存到本地。这篇文章沿着 《一种将线上内容精简格式后保存到本地的方法》、《剪藏网页到本地的自动化思路(以 Keyboard Maestro 为例)》 和 《剪藏网页到本地的轻量化思路》 的思路,尝试将长推文保存为 PDF,以供日后阅读和参考。
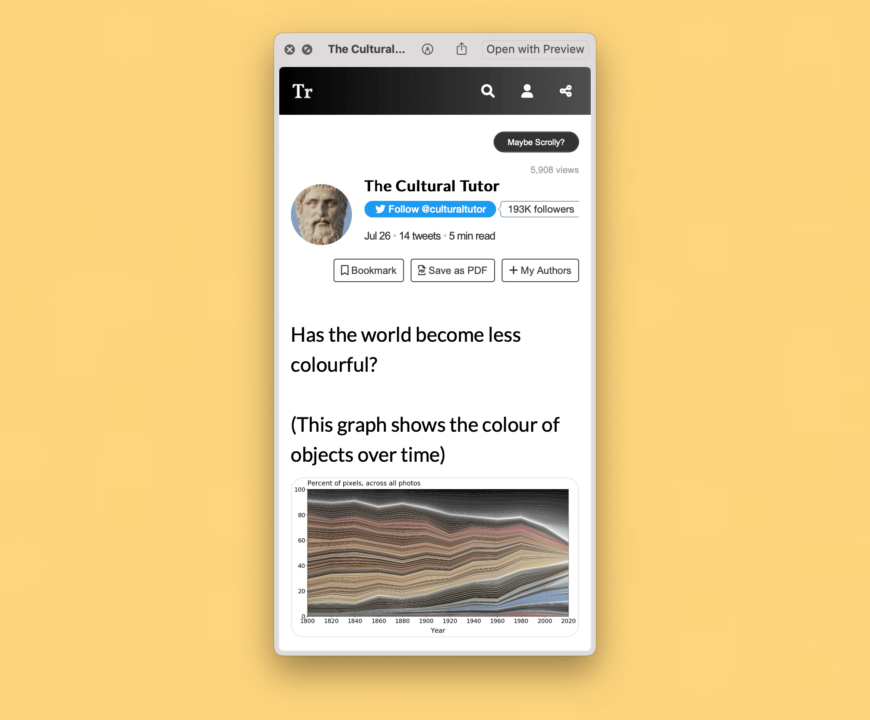
杂症诊断
保存 Thread 难于普通推文,一般的内容,只是寥寥数语配上几张图,丢进网页剪藏工具,如同伸手摘下低垂的果子;而 Thread 则堪比文章,篇幅甚巨,有些人在 Twitter 上长篇大论(比如 这个),有的则开列清单喋喋不休(比如 这个(存档)),Thread 下不经意间就有几十条回复,一般的网页剪藏工具很难悉数摘取——何况在线工具本身说不定比在线内容更早灭绝,我怎么敢把鸡蛋放在它们的篮子里?
过去十年里,我在 Evernote、Instapaper、Pocket 和 Notion 等工具中颠沛流离。这些工具获得的剪藏内容好像落叶堆,最顶上的叶片新鲜靓丽,但稍微往下挖一点,就会发现缺胳膊少腿者;而一旦深挖到底,则是彻底腐烂的内容,超链接丢失、图片打不开、文章被拦腰截断,比比皆是。毕竟我们没有为存储服务掏钱,这些工具也没有必要做老好人。
于是我们还得自己动手。就保存网页内容为 PDF 而言,有两个核心步骤。
- 清理网页版面的工具。通常可以用浏览器的阅读模式,但如果网页本身广告不多,我还是愿意保留其版式,毕竟网页设计就像杂志装帧,本身就是阅读体验的一部分;苟一律套用阅读模式,难免要失去一些风味。
- 打印 PDF 的服务。可以是 DEVONthink 或 Javascript 脚本等复杂方案,也可以是 Safari 自带的导出功能,对于图文混排的文章来说,导出单页的连续 PDF 效果更好,图片不会被硬生生裁开搁在两页。同样,如果网页广告没有堆成九龙城寨,我更倾向于使用 Safari 原生导出功能,而不愿动用 DEVONthink 等重型工具。

而 Twitter 在上述两步都可谓坎坷。一般而言,我们习惯在手机上刷 Twitter,理想情况就是转到 Safari 打开 Twitter 链接,截屏后查看缩略图,然后找到导出全页面 PDF 的选项,前述两步本可并作一步。然而,直接打印的尝试将以失败告终。
处理步骤
首先是 Twitter 官方限制。如果你使用客户端,那几乎上就别指望导出任何东西;即便使用网页版,Twitter 也设下重重藩篱,就算你能够浏览网页上的全部内容,也不能将其保存下来——你可以试试复制 Twitter 网页,得到的甚至不是富文本,而只是开头的少许图文加上大量空白内容——并且打印网页也做不到,只会得到长长的白色空白页面,仿佛除了故障的超市小票打印机。其次,即便 Twitter 破天荒地拆除栅栏,Thread 中也有大量读者评论,这些玩意儿根本没资格和作者的推文黏在一起,我们还得想办法将其刨除。
跟随保存普通网页为 PDF 的思路,处理长推文也有两个步骤。起手仍然是清理格式,把推文转换为传统的网页文章。不少 Twitter Bot 都致力于这一工作,例如 Thread Reader、Threader 和 Unroll Thread,但我不愿意在别人的推文下写到此一游,因此倾向于使用这些工具的网页服务。我最常用 Thread Reader,并为之写了一个 Bookmarklet 小插件——你可以把 这个 链接加入浏览器收藏夹,之后在 Twitter 页面打开它,就能将当前推文发送给 Thread Reader,稍等几秒就会获得重新排版完毕的长推文。Bookmarklet 源码随后,请随意使用;另外,Shortcuts 版本的下载链接 在此,可以在 Twitter 或第三方客户端内部使用。
javascript:location.href%3D'https://threadreaderapp.com/search%3Fq%3D'%2BencodeURIComponent(location.href)%3B
Thread Reader 处理后的 Thread 就是一篇规矩文章,直接打印也不再有限制,还可以搭配阅读器模式,尽管我并不这么干,因为 Thread Reader 的界面已经足够简单。但某些浏览器或插件可以自定义 CSS,对版式有需求的读者,还是可以再作调整。
总之,Thread Reader 排好的图文已经可以交付打印。在手机上直接截图,然后导出整页 PDF;而在电脑上,则是点击菜单栏中的“Export as PDF…”选项,方能得到整页不断的 PDF,一如浏览 Twitter 时那样连续不断。Thread Reader 也有自己的推广内容,好在但凡能打印成 PDF,控制权就交到了我们手上:我们可以像裁切照片一样,直接的截图编辑界面下裁掉尾部的多余内容。
小结
我一直将信息采集比喻为食物采集:只在连接到网络时尽可能采集资料,最终全部贮藏在本地——打印为可靠的 PDF 格式。两年前,我知悉 Hum 同样苦恼于链接腐烂(Link Rot),于是我们编写了一些摘取网页内容的自动化工具;而微博(我们都不看)、公众号(Hum 不看)、Twitter 等现实意义上的局域网,却不能以通用方案解决,于是我仍然在摸索专用方法。
这篇文章针对 Twitter Thread 给出了一套思路,其中涉及的软件都是可以替换的(很庆幸不需要放出 DEVONthink),尤其是随时可能失效的在线服务。而剪藏网页,或许最需要鲁棒的方法。