

在《巴别图书馆计划(二):批量索引 DEVONthink 书籍到 Calibre》中,我以 DEVONthink 为例,介绍了将书籍索引1到 Calibre 的完整流程。
不过,DEVONthink 绝非必需。若以庖丁解牛之志条分缕析,不难发现,其实整个流程都可以还原为具体的动作,而这些动作并不需要和特定的软件绑死;打个比方,整套方法其实像极了制作通讯录:
- 一个集中管理书籍信息的软件,相当于通讯录,我选择的是 Calibre,但归根结底,用 Excel 表单似乎也没什么不妥;
- 一个数据和软件分离的阅读器,比如 DEVONthink,这样可以最大程度与书籍管理软件互通;
- 一种生成文件链接的方法,相当于提供了书籍的通讯地址,以便点击之后直接打开书籍原始文件。
一旦把软件分解为操作,DEVONthink 这个庞然大物就会乖乖躺下:你可以继续驾驭它,不必费心另寻出路;也可以轻装上阵,采取更通用的方法。本文就提供一套不需要任何第三方软件——除了 Calibre 本身——的思路,可以批量把任意文件夹中的书籍索引到 Calibre。
如何索引任意书籍文件到 Calibre
不借助任何第三方工具就完成索引,所需的准备当然也多一些,就像自己洗、切、炒、炖,需要的工夫肯定比自动料理机或半成品菜多一些。2简言之,需要:
- 在 Calibre 中准备一个登记文件链接信息的栏目(column);
- 在电脑上找一个存放后续所需数据的文件夹,请保持此文件夹固定在一处,以免造成链接失效;
- 配置好文章开头提供的自动化工具。
首先,还是得在 Calibre 中创建一个栏目,用于填写文件链接信息。如果你在阅读前文时已经添加过栏目,则可以跳过这一段。在 Calibre 的设置中,找到“Preferences - Add your own columns”,点击“Add custom column”以创建新的栏目,并将其命名为 uuid——可以是别的名字,只要你记得修改自动化动作中的相应代码。紧接着,将这个栏目的格式设置为 HTML,这样得到的链接才是一个超链接,可以直接点击。
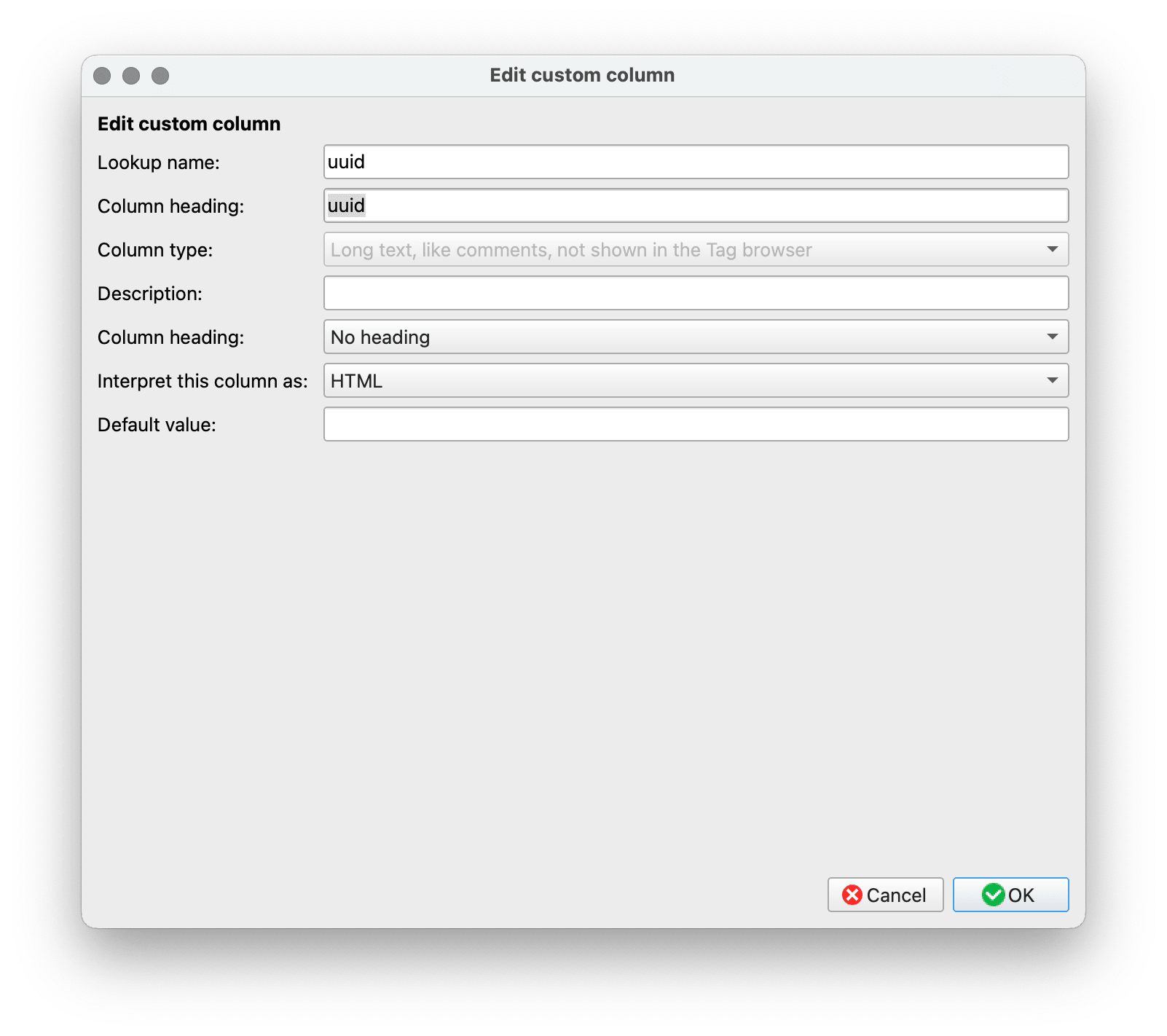
随后,在电脑上选一个不太会改动的位置,创建一个文件夹,之后的文件链接原始数据都放在这里。我喜欢在用户根目录 ~/ 下创建文件夹,一来不容易改动,二来路径比较短,生成的链接简短美观一些。我的文件夹名称是 KM,因为我习惯和 Keyboard Maestro 生成的链接共用一个文件夹(Keyboard Maestro 和本文无关,请勿在意),你当然可以另行命名——同样,要记得更改对应的代码。
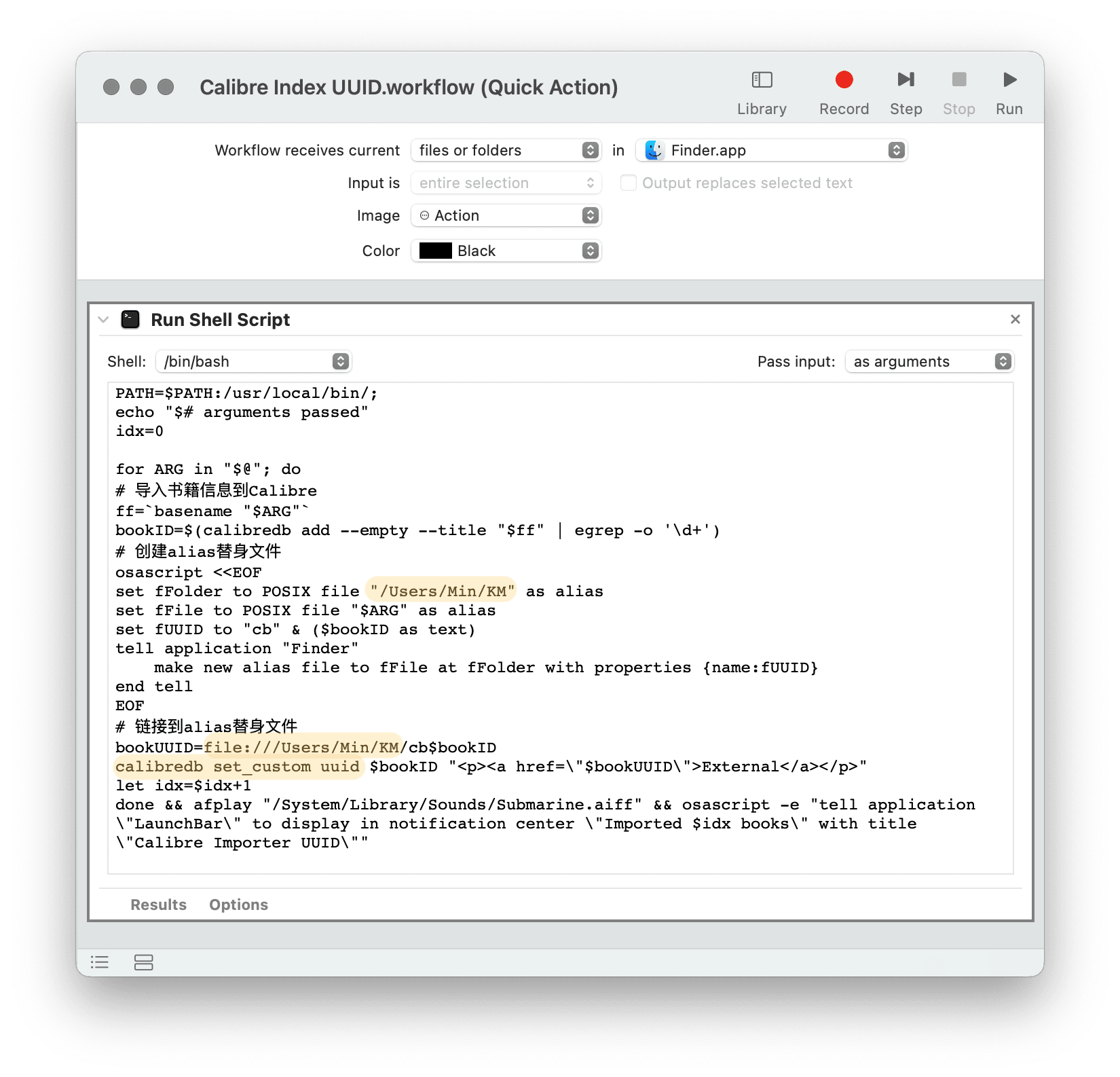
最后,打开文首提供的自动化动作,修改以下几处(以 Automator 版为例):
- 把
/Users/Min/KM改为你存放文件链接数据的文件夹; bookUUID=file:///Users/Min/KM/cb$bookID中的路径也如上一步一样作相应修改,以保持路径一致;calibredb set_custom uuid中的uuid是自定义的栏目名,如果你使用了别的名称,请同步修改。
完成以上准备工作以后,即可批量索引任何外部文件夹中的书籍文件到 Calibre,同时填好文件名及其链接;而在 Calibre 中,也可以点击链接直接打开原始文件,而不再担心原始文件如何移动和修改。3
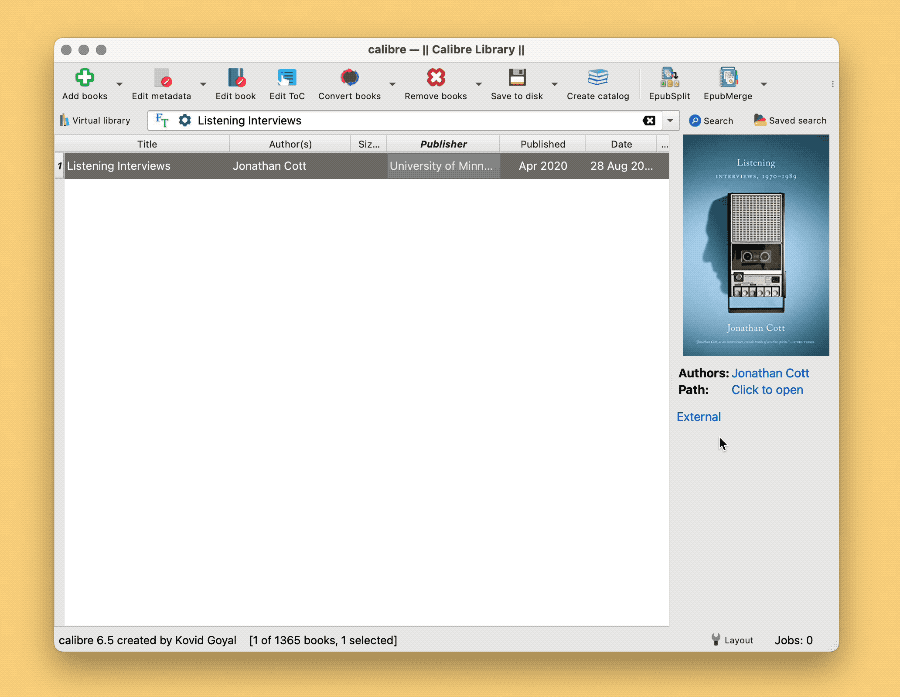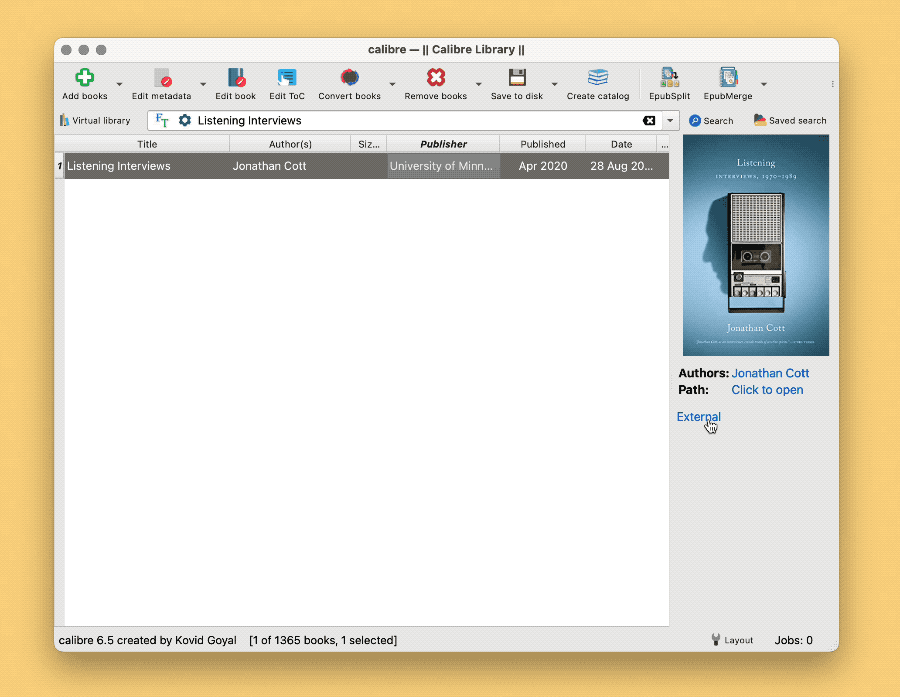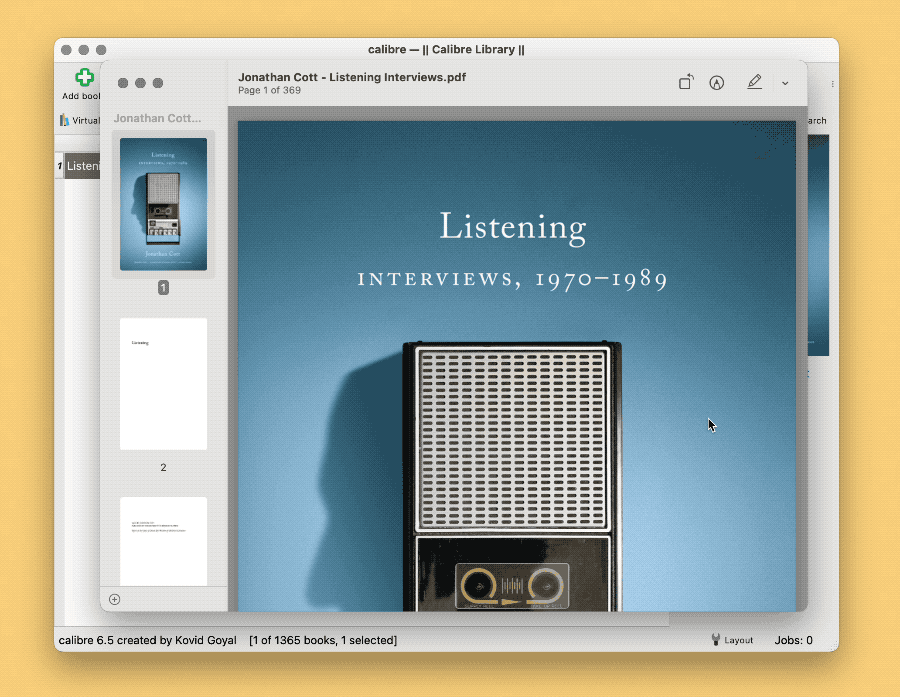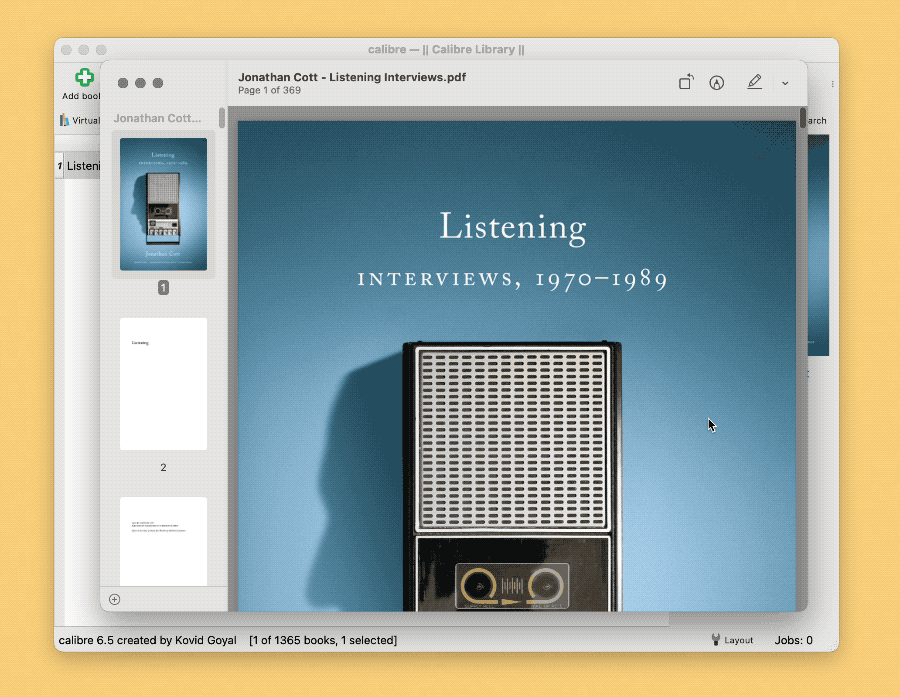
如果要问,为何不一开始就把 PDF 导入 Calibre?答案也很简单:通过索引的方式,管理和阅读得以分离,你可以用 Calibre 统一浏览、检索或创建书单,同时用任何一款趁手的阅读器研读原始文件。更深入的想法,在系列文章第一篇中已有讨论。
原理简析
离开 DEVONthink 之后,首先要解决的问题就是文件链接,即 item link 的替代品。这个链接的意义在于点击直达原文,并且要牢固可靠,即使原始文件被移动或者重命名(这是常有的事),链接仍然畅通可用。通常的方法是寻找 DEVONthink 的替代品,而常常混迹效率工具圈子的人,估计第一个想到的就是 Hookmark,更老一辈的人则会想到 Skim。这些工具固然优秀,但和 DEVONthink 放在一起,只是让武林群雄的场面更热闹一些;这种时候,往往会有一个扫地僧路过,轻描淡写地把一众高手撂翻在地。
这名扫地僧就是替身文件(Alias),相当于 Windows 中的快捷方式。在《macOS 中的阿里阿德涅之线——Deep Link》 和 《如何一键打开 macOS 中的任何文件(以 Keyboard Maestro 为例)》 两篇文章中,我都介绍过 macOS 下的替身文件,它胜在可靠,不管原始文件怎么改动,只要还在电脑上,通向文件的道路就是开通的;再往前走一步,获得替身文件的链接,其实就相当于得到了稳定的文件链接。4当然,为了保证替身文件链接本身是可靠的,还需要将其保存在专门文件夹中,通常不去修改它。
至于替身文件如何命名,我考虑过很多方案,包括保持原始文件名、使用时间戳以及纯粹的乱码(最后一个为 DEVONthink 所采),最终还是选择了与 Calibre 中的书籍编号保持一致。详言之,每次在 Calibre 中新建一个条目时,都会得到一个唯一编号,这个编号恰好可以用来命名替身文件,比如编号 1001 的书籍,它的替身文件链接就是 ~/KM/cb1001,又短又有实际含义。5对了,替身文件不需要拓展名,最终生成的文件链接不仅得以尽可能短,而且减少了字符过多带来的不可控因素。
获得关键的文件链接之后,整个索引流程就简单了:
- 获取 PDF 文件名;
- 为 PDF 创建替身文件,并获得替身文件的链接;
- 在 Calibre 中创建一个新条目,并把文件名和文件链接添加进去。
其中的技术细节、如何与 Calibre 交互等等,在 前文 中已有涉及,这里不再浪费笔墨。说到底,无非是提取数据,然后添加到 Calibre 而已。
小结
Calibre 之所以能够成为电子书管理的枢纽,不仅仅依靠其本身,各种形式的链接可能居功更甚。链接是 Calibre 与其他工具沟通的桥梁,而通过本文的方案,我们彻底摆脱了对具体某个工具的依赖,只要能找到原始文件,就可以索引到 Calibre。
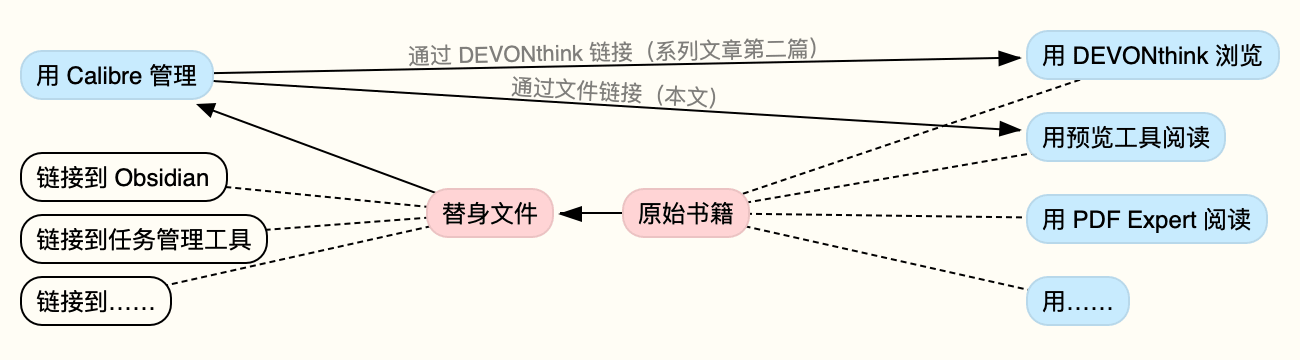
使用 Calibre,就是走出了分离的第一步,将阅读与管理分开,各自使用更适合的工具;而通过文件链接,则进一步把存储也分离出去,不需要为了某个阅读器而牺牲整个文件存储结构——这只是避免了消极的一面,积极之处在于,文件链接可以放诸笔记软件、任务管理工具或者其他任何支持超链接的地方,让你在 Obsidian、Logseq、MindNode、Scapple 等工具之间来去自如,只不过,这些都是后话了。
毕竟,阅读器可能会换——回忆一下,五年、三年或一年前你在用什么阅读器——但文件本身的寿命要长久得多。我们不囿于某个阅读器,也不把原始文件交给 Calibre;一旦拉长时间线,想想几年后的自己,恐怕数据、阅读和管理,还是解绑为好。
- 是“索引”(Index)而不是“导入”(Import),我们取前者,只需要将书籍信息添加到 Calibre,而无需动到书籍的原始文件。导入不属于本系列文章讨论范围,因为一旦导入,就是被锁死在特定软件中,和整个系列文章的初衷背道而驰。 ↩
- 如果自动料理机设计得不好,那么花费的力气将比自己动手做菜还多。在软件领域,这样的情况屡见不鲜,所以你很少看到我介绍那些流行一时的工具。 ↩
- 图中的封面、作者、出版社和出版时间等信息需要手动添加,这不在本文负责范围之内。你可以搜索一下 Calibre 的豆瓣数据导入插件,不过豆瓣上的数据本身就参差不齐——同一个作者可以有四五个译名,像茴香豆的写法一样多——我宁愿对照多个数据来源,手动录入书籍信息。 ↩
- 严格来说,替身文件也有可能失效,比如当你一次性处理几百个文件后,一部分替身文件就可能“没反应过来”。不过,失效之后只需重新指定一下原始文件即可。 ↩
cb是 Calibre 的缩写,因为我和在替身文件夹中还有其他文件,用这个缩写可以作出区分。 ↩