

吾生也有涯,而知也无涯。
好书太多了,不知道读哪本收益最高,最符合自己的需求。好在豆瓣网站已经整合了无数读者的点评和建议,为我们提供了一个直观的平台来预览书籍信息。通过豆瓣读书,我们可以看到每本书的综合评分、读者评论、及相关介绍。
第二个问题随之而来,待读书单里已有 100 多本书了,一个个翻网页去比对这也太麻烦了吧?如果能将书籍信息汇总到一个表格里,进行筛选和排序就很方便了。Notion Database 擅长做这个事,通过创建个性化的数据库,辅以筛选和排序功能,轻松地对待读书单进行管理。
那么,如何将豆瓣上的书籍信息方便的录入到 Notion 中呢?Shortcuts 可以将二者一拍即合。

用 Shortcuts 从豆瓣抓取书籍信息,然后通过 API 保存到 Notion 中。只需要几次点击,就可以建立自己的图书馆。
早期我是将所有信息存在 CSV 中,每次打开总要在 Numbers 中操作一番显示格式和过滤,不如 Notion 方便。所以现在调整为直接保存到 Notion,留一份备份在 CSV 文件中,线上线下兼得。
得益于 Apple 的全平台特性,本套方案无需任何修改即可在 Mac 上使用:
在 Safari 中打开豆瓣书籍页面——分享——Shortcuts——运行获取豆瓣书籍信息的 Shortcuts 即可。不管在哪里看到好书,随时抓取到自己的书库里~
安装后填入自己的 Notion API key 和 Database id。
从豆瓣获取书籍信息
创建 Database
在 Notion 中新建一个 Full page Database,比对着豆瓣网页上提供的书籍信息,建立自己希望保存的属性。并为属性选择合适的数据类型,稍后我们将书籍信息保存到这个 Notion Database。
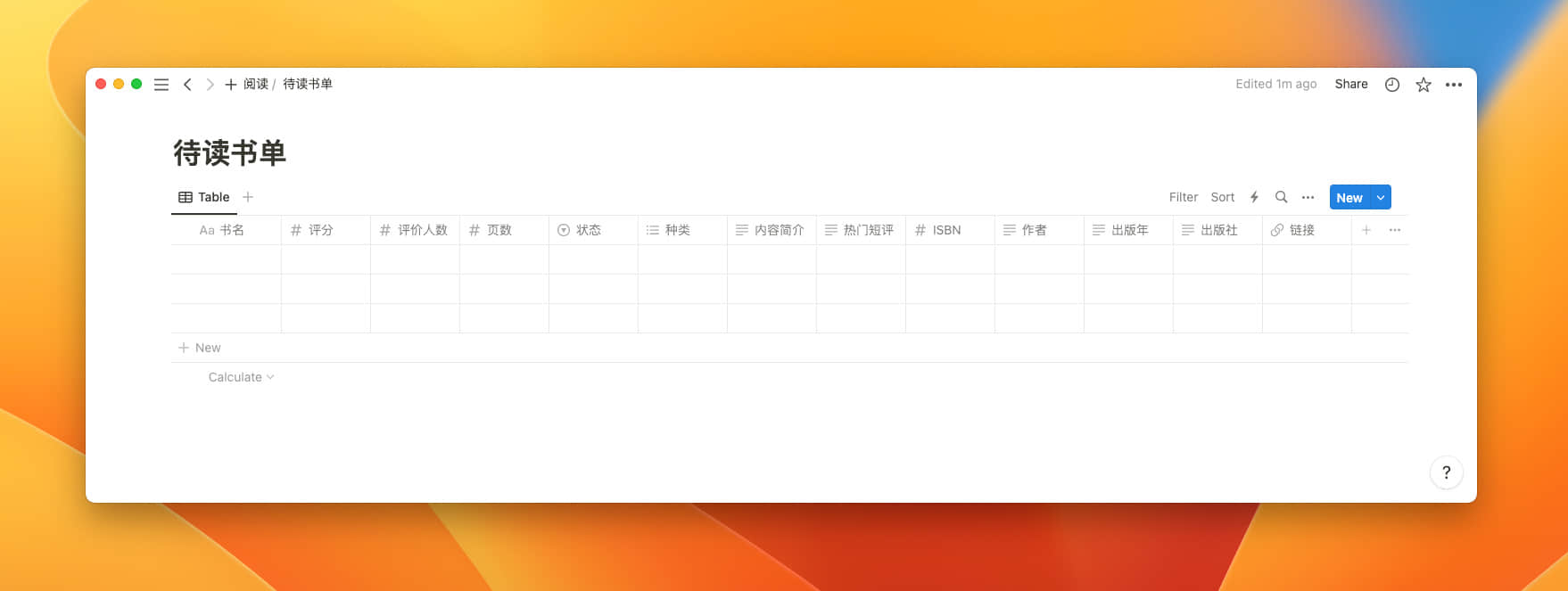
打开 Database 模板 链接,点击右上角的 “Duplicate” 可以直接复制我的模板到自己的 Notion 中。
“状态”和“种类”是我自己添加的 Database 属性,用来帮助筛选书籍。
“状态”是一个标签,用来表示是否打算阅读一本书,只有一种状态就是“看”。目前想看的书我会标记上“看”,进行初步筛选。
关于如何使用标签,Minja 在《3-7 标签作为一种管理工具:指示性标签》有详细的说明。
再如阅读文章,我就只有一个维度:看,没有什么稍后看、过几天看以后再看、放进愿望清单这种无穷倒退式的标签分类。
UNTAG 会员文章《会员讨论:星标、旗标、优先级》也有过相关话题的讨论。
“种类”用来根据自己情况进行书籍分类,也是用来筛选书籍的一种手段。例如想读小说时,肯定要把编程类书籍过滤掉。
获取信息
1. 书名、评分、评价人数
建立好 Database 后,先从第一个 Database 属性——书名,开始从豆瓣网页上获取数据。
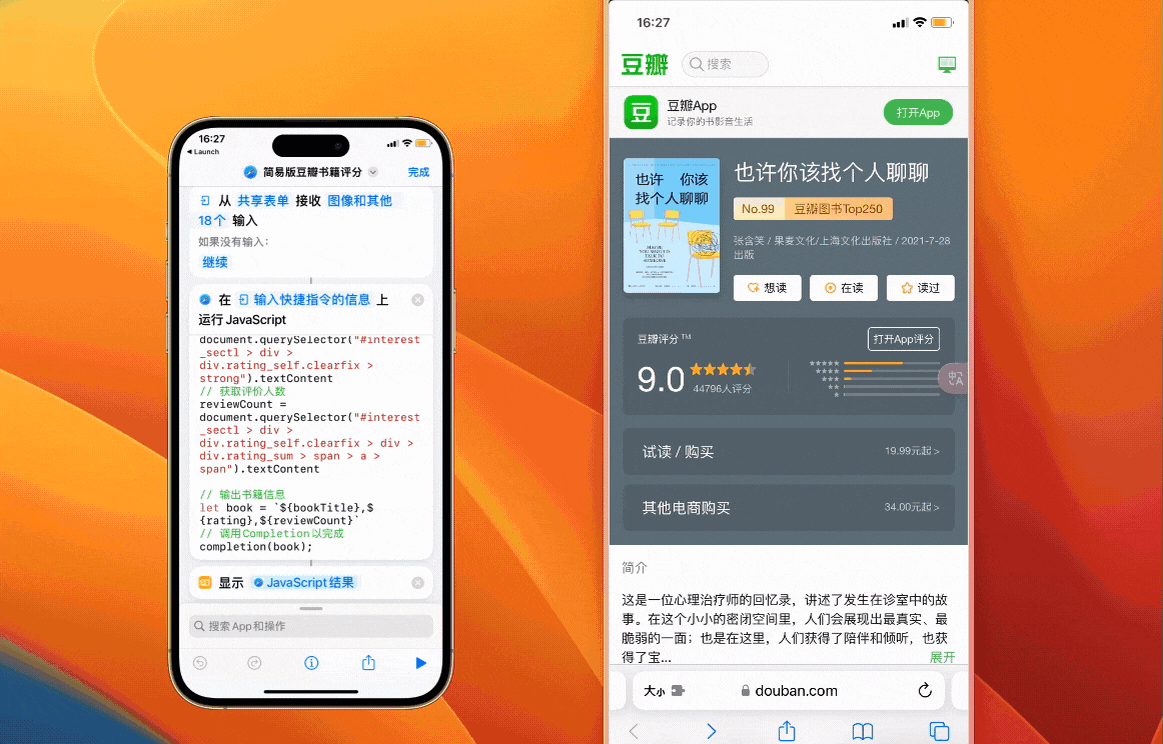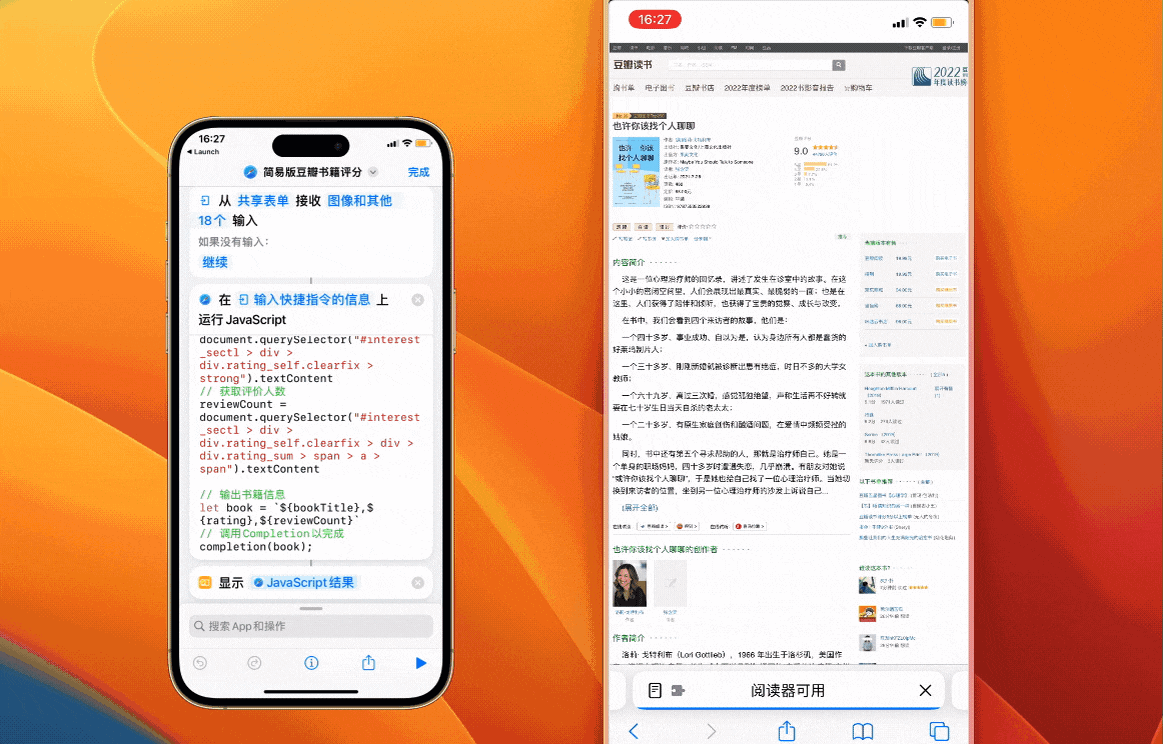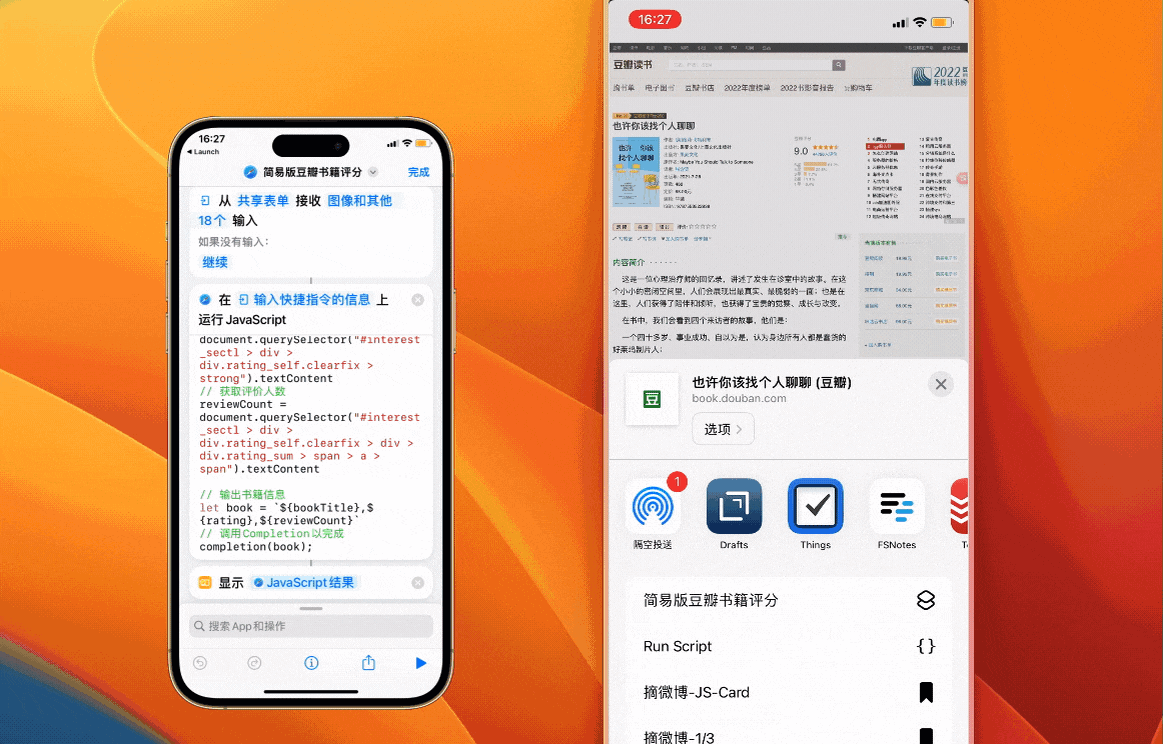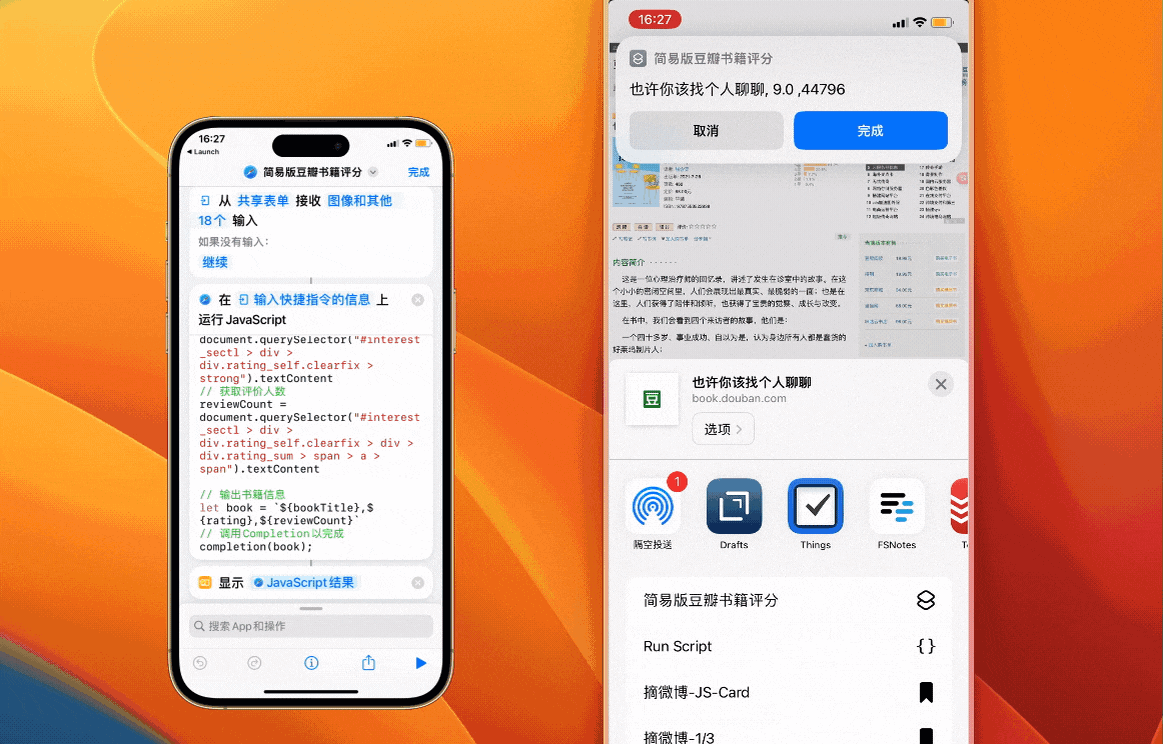
以《也许你该找个人聊聊》这本书的详细页面为例:
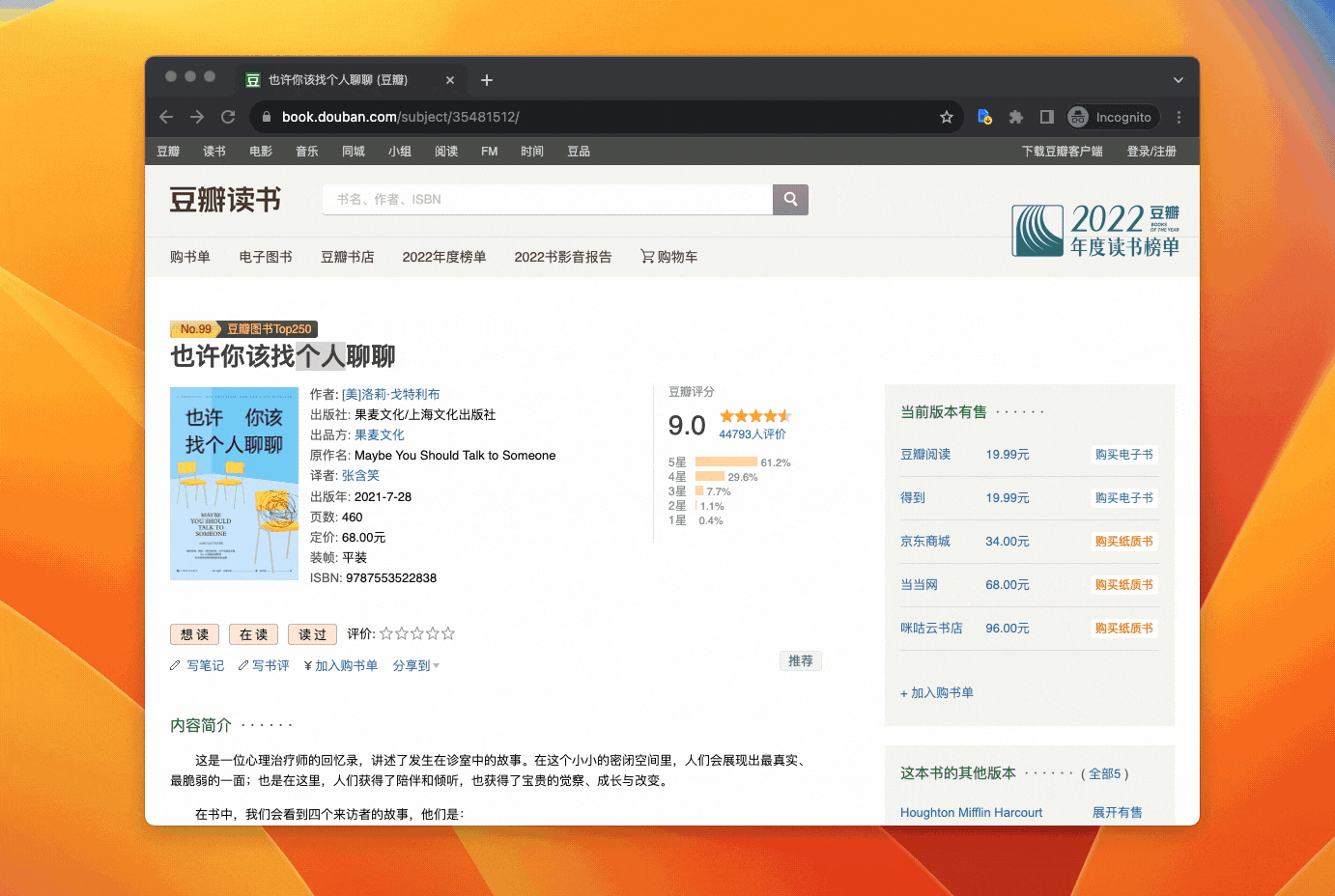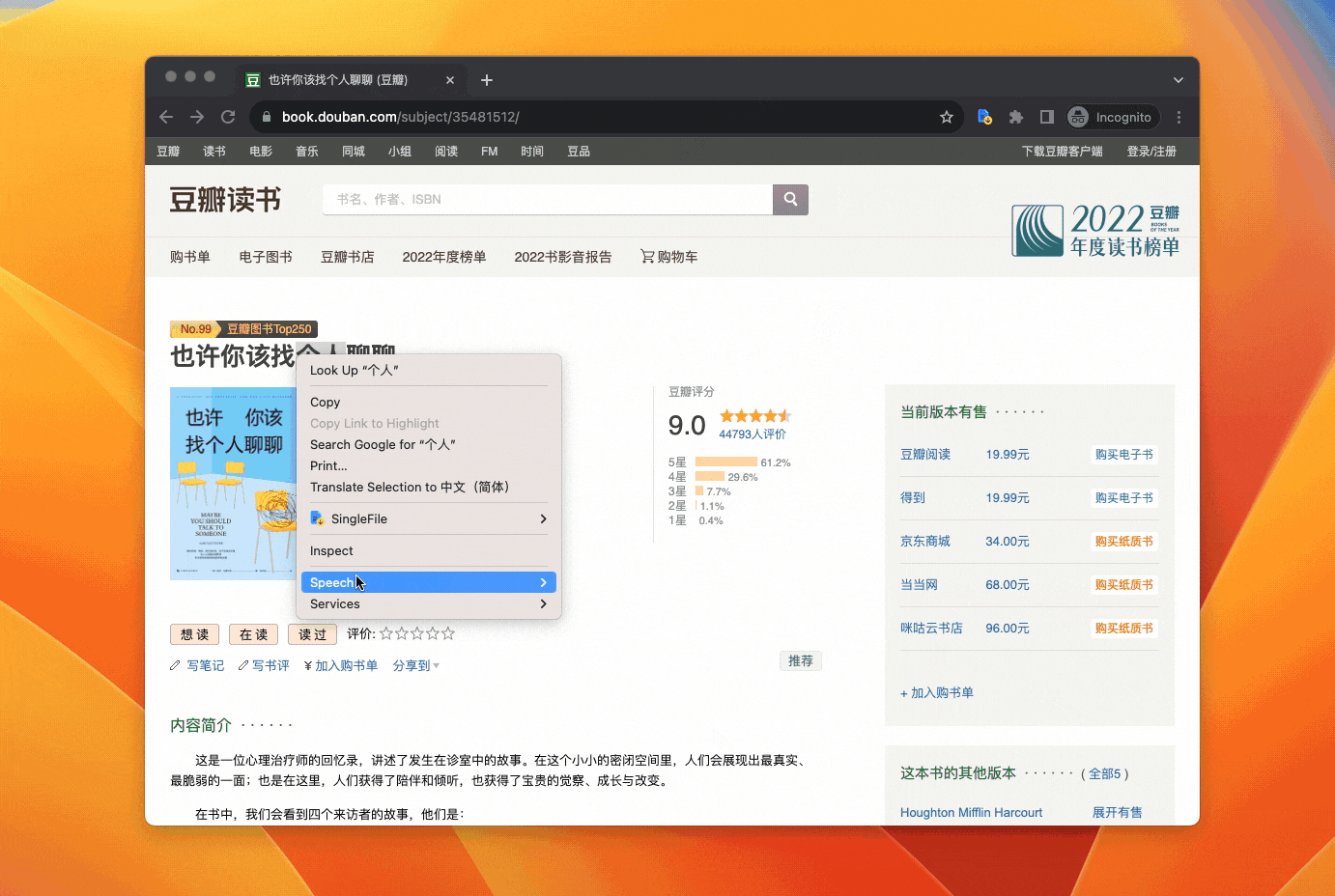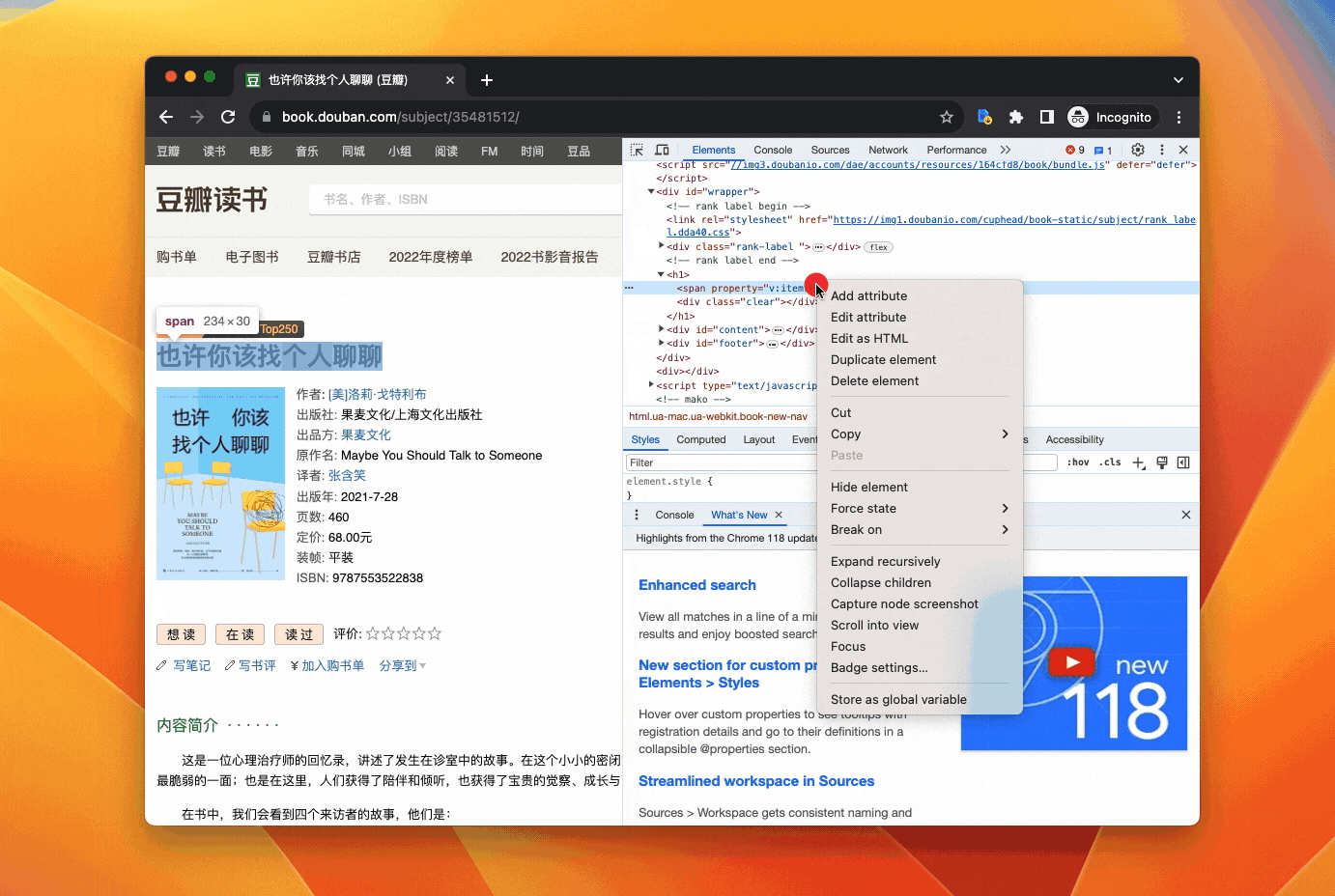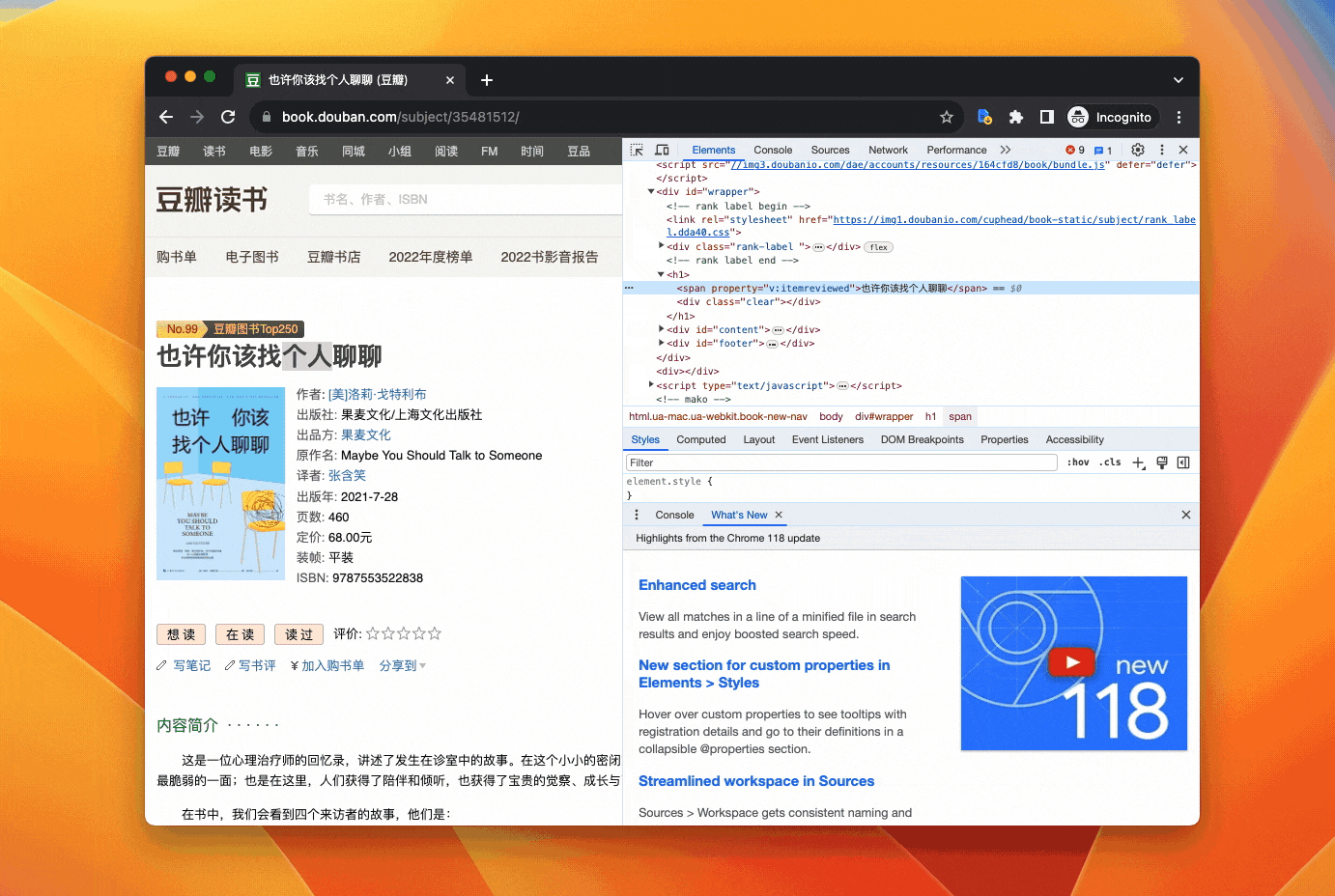
在书名上右键——Inspect——在高亮的 HTML 代码上右键——Copy——Copy JS path,会得到如下的代码
document.querySelector("#wrapper > h1 > span”)
在这行代码的后面加上一个 .textContent,可以获取上面查找到的 HTML 元素的文本内容。
把组合后的代码输入到 Console,按下回车,你会得到书名:
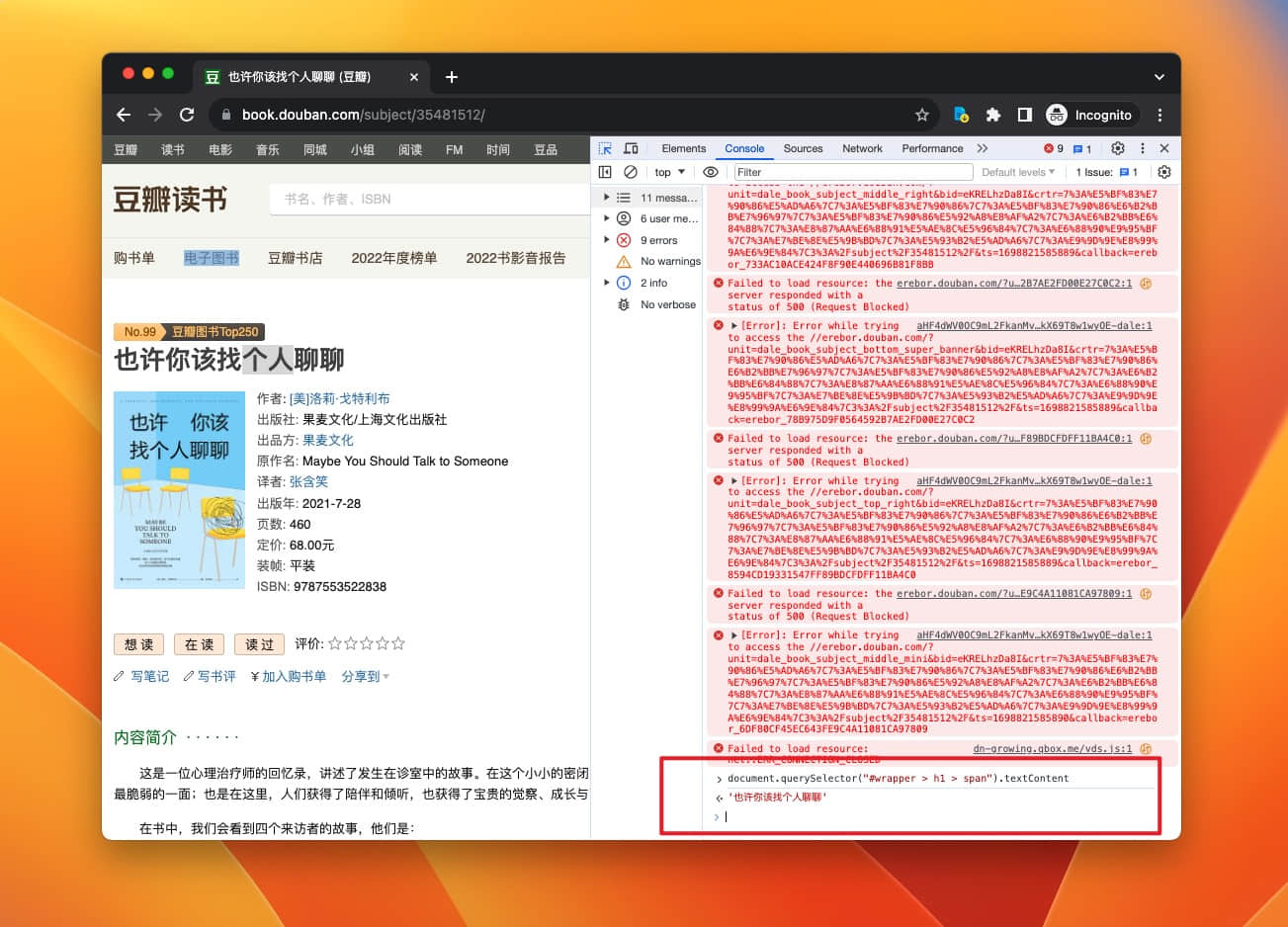
关于如何定位元素、什么是 JS path、什么是 document,见旧文《保存网页时一键裁切不必要的部分》有详细说明,本文不做详细介绍。
接下来如法炮制,获取评分、评价人数:
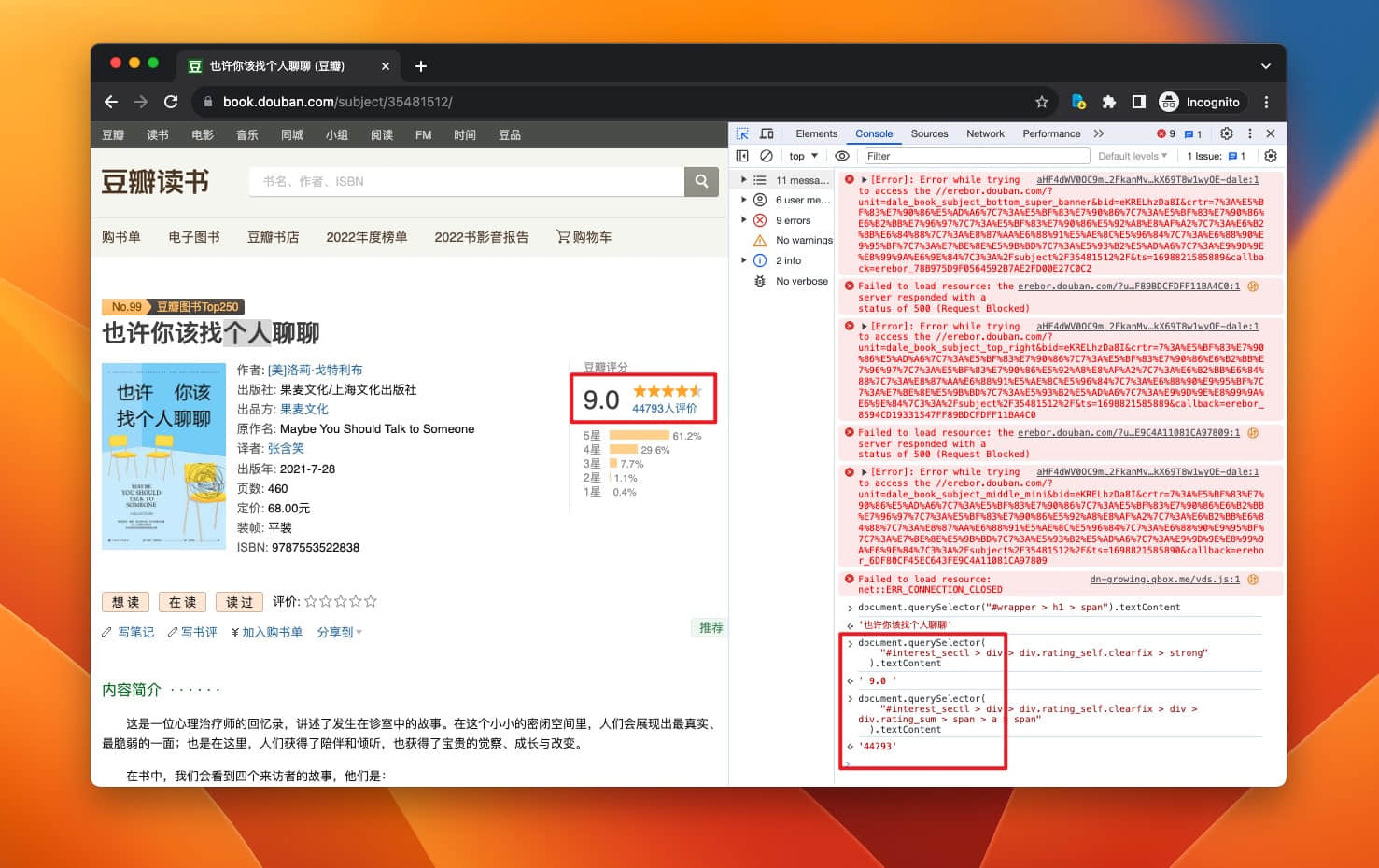
代码如下:
- 评分:
document.querySelector("#interest_sectl > div > div.rating_self.clearfix > strong").textContent - 评价人数:
document.querySelector("#interest_sectl > div > div.rating_self.clearfix > div > div.rating_sum > span > a > span").textContent
这个时候只要在 Shortcuts 中简单组装一下上面的代码,就拥有了简易版的获取豆瓣书籍评分工具
// 获取书名
bookTitle = document.querySelector("#wrapper > h1 > span").textContent;
// 获取评分
rating = document.querySelector("#interest_sectl > div > div.rating_self.clearfix > strong").textContent
// 获取评价人数
reviewCount = document.querySelector("#interest_sectl > div > div.rating_self.clearfix > div > div.rating_sum > span > a > span").textContent
// 输出书籍信息
let book = `${bookTitle},${rating},${reviewCount}
// 调用Completion以完成
completion(book);
通过 Shortcuts 在网页上运行 JavaScript 若要返回数据,必须在 JavaScript 中调用完成处理程序,即代码中最后一行的 completion(book)。
有关 “在网页上运行 JavaScript 动作” 的一些技术细节可以阅读苹果官方文档。
注意:使用时先点击右上角绿色计算机图标,将页面从手机端切换为电脑端,再运行 Shortcuts。手机端访问时默认呈现的页面缺少了很多信息。
对整体流程有了初步的了解之后,我们继续获取其他信息。
2. 书籍信息:作者、出版社、出版年、页数、ISBN
还是按照前面选择元素的方法,分别在作者、出版社、出版年上右键...(省略后续步骤),可以发现这些信息都属于 info 这个元素:
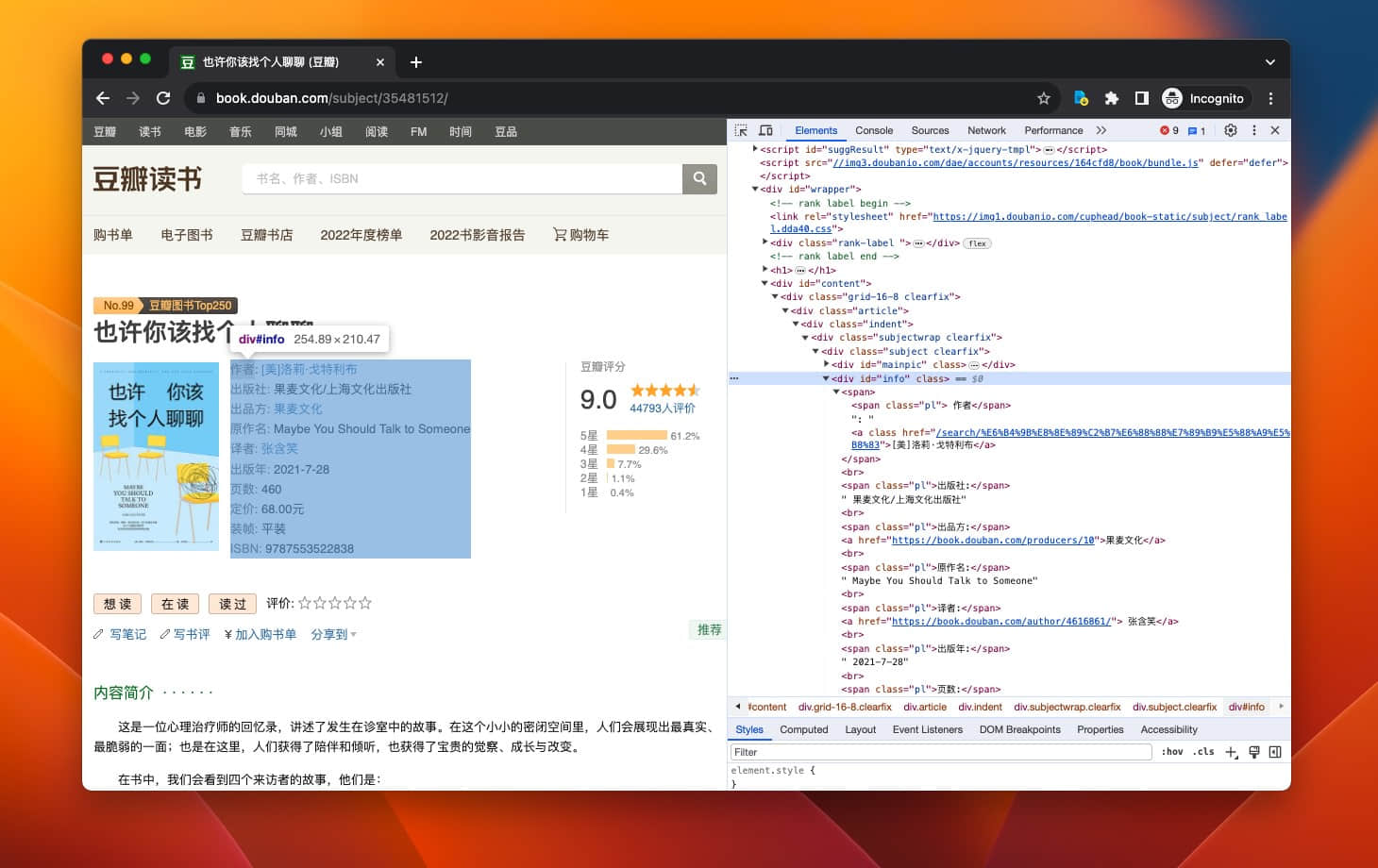
那能不能直接获取 info 中的文本然后再想办法拆分呢?
用 info 的 JS path 测试了一下是可以的:

获取了全部文本,如何提取为结构化的内容呢?这种困难的工作就交给 GPT 老师好了。

经过几次调试和经过获取 100 多本书信息的准确性验证后,这是最终的代码:
// 获取书籍信息
let info = document.querySelector("#info").textContent;
// 用于存储提取的键值对信息
let infoJson = {};
// 正则表达式,用于匹配“key: value”这样的字符串
// (.+): 捕获一或多个任意字符(代表键),后面跟着一个冒号
// \s* 匹配零个或多个空白字符
// (.+) 捕获一或多个任意字符(代表值)
// g 表示在文本中找到所有的匹配项
let regex = /(.+):\s*(.+)/g;
// 用于存储每次正则表达式匹配的结果
let match;
// 使用 while 循环重复地在 info 文本内容中查找与正则表达式匹配的项
while ((match = regex.exec(info)) !== null) {
// 从匹配的结果获取第一个捕获组(即键),使用trim()删除前后的空白字符
let key = match[1].trim();
// 从匹配的结果中获取第二个捕获组(即值),删除前后的空白字符
let value = match[2].trim();
// 将键和值添加到 infoJson 字典中
infoJson[key] = value;
}
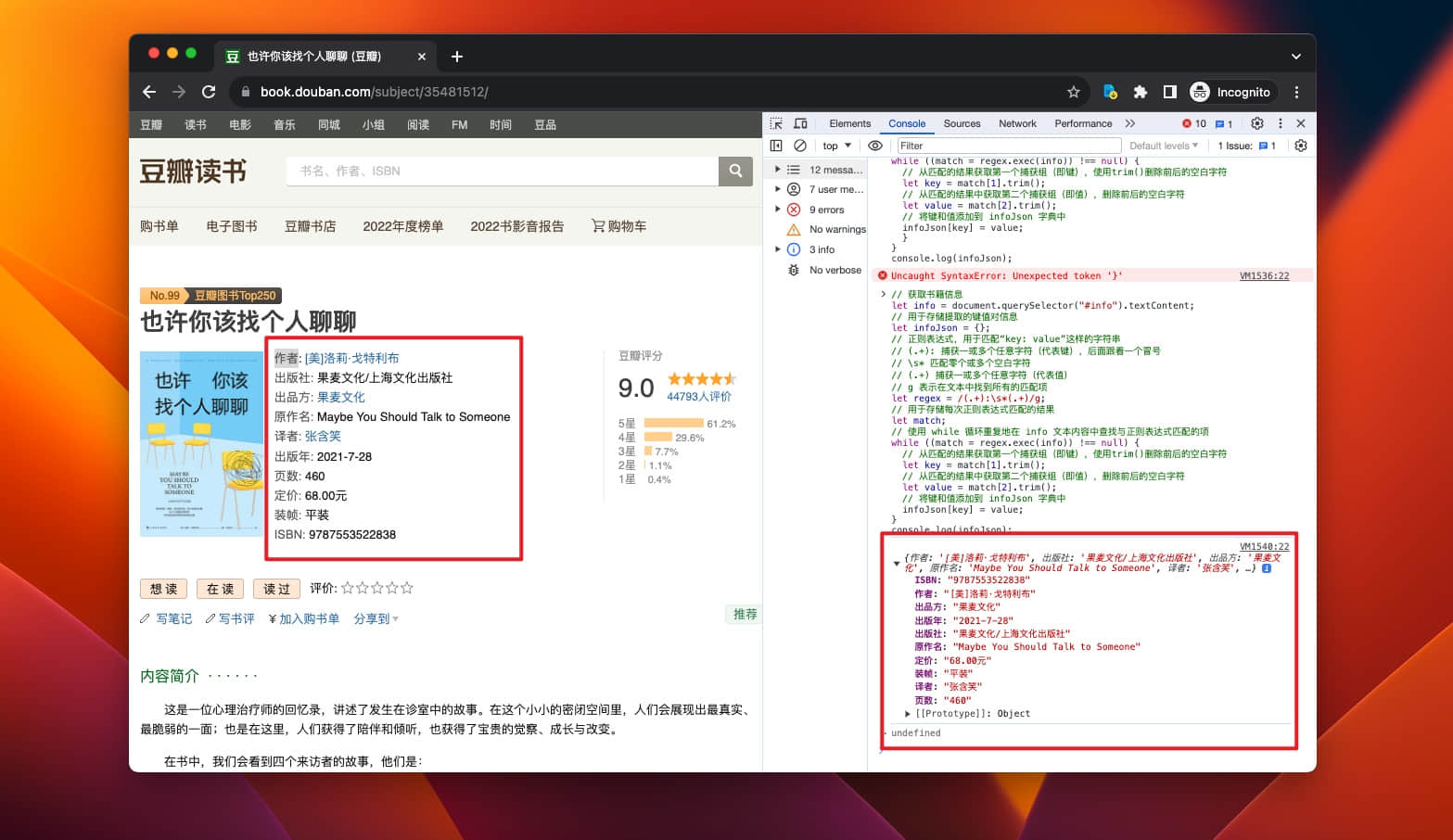
// 在 Console 输出 infoJson
console.log(infoJson);
输入到 Console 中试试。
感谢 GPT 老师。
3. 内容简介
接着往下看,这次是取内容简介。
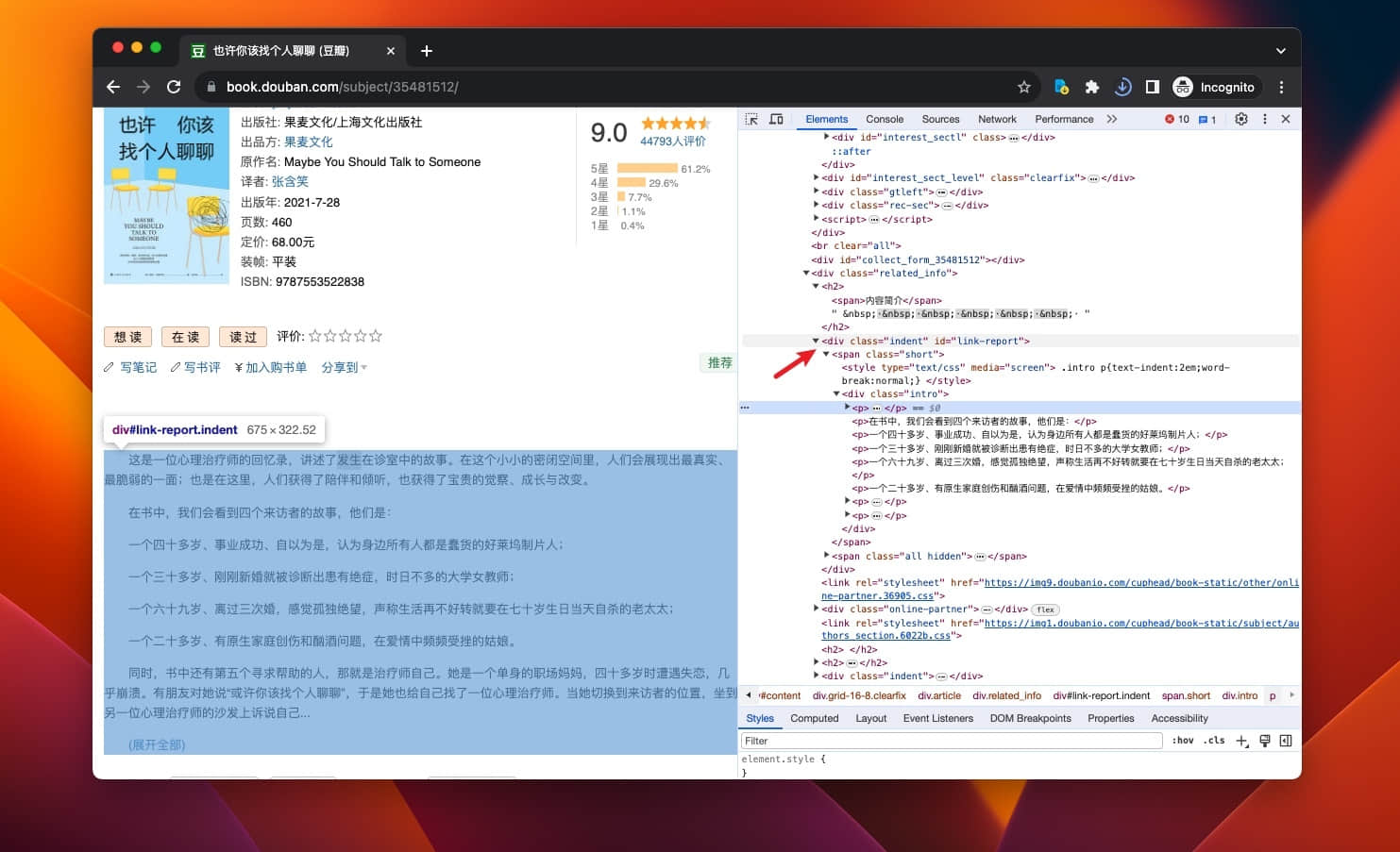
仍然按照:右键——Inspect...的流程。注意要取 <div class="indent" id="link-report"> 部分的 JS path,下方的 <div class="intro"> 有些书籍会没有这部分。
之前从查找到的 HTML 元素获取文本内容使用的是 .textContent,这里稍做变化,改为 .innerText。不知道什么原因,豆瓣网站在“内容简介”中使用 CSS 代码隐藏了一部分文本,直接使用 .textContent 会取得多余文本。innerText 与 textContent 稍有不同,它返回元素的“渲染”文本——即页面上实际显示给用户的文本,而不包括那些隐藏的文本。
还有一点细节要注意,内容简介中可能会有 " 号,在保存为 CSV 文件时会影响格式,需要将 " 号替换为 ' 单引号。
总结以上流程的代码为:
// 获取内容简介的“渲染”文本
let bookDescription = document.querySelector("#link-report").innerText
// 使用 replace 正则表达式替换 bookDescription 中的所有双引号(")为单引号(')
bookDescription = bookDescription.replace(/"/g, "'");
// 在 Console 输出 bookDescription
console.log(bookDescription);
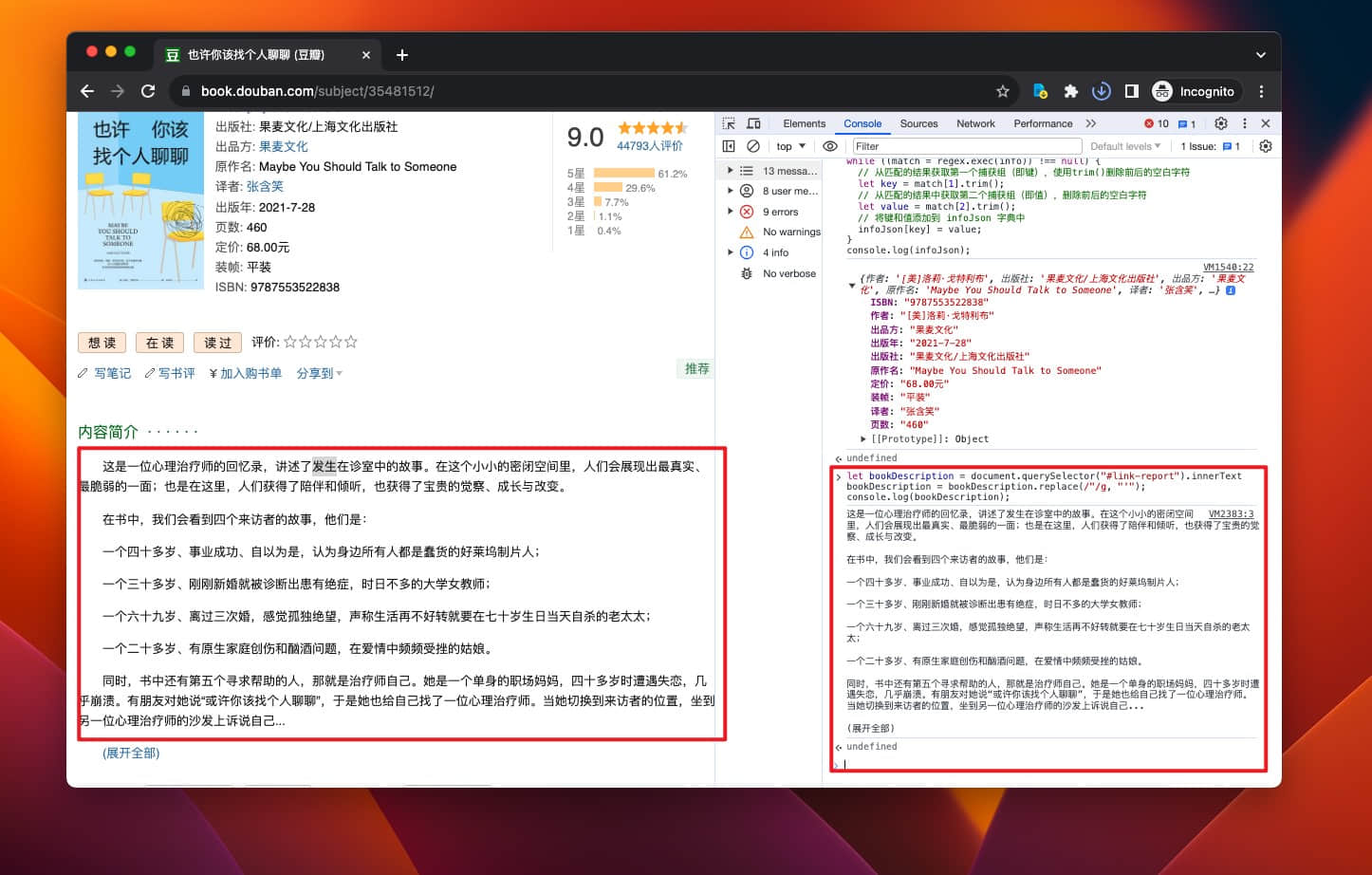
搞定。
4. 热门短评
来到获取数据的最后一步了,热门短评。
照例在热门短评上右键,Inspect...
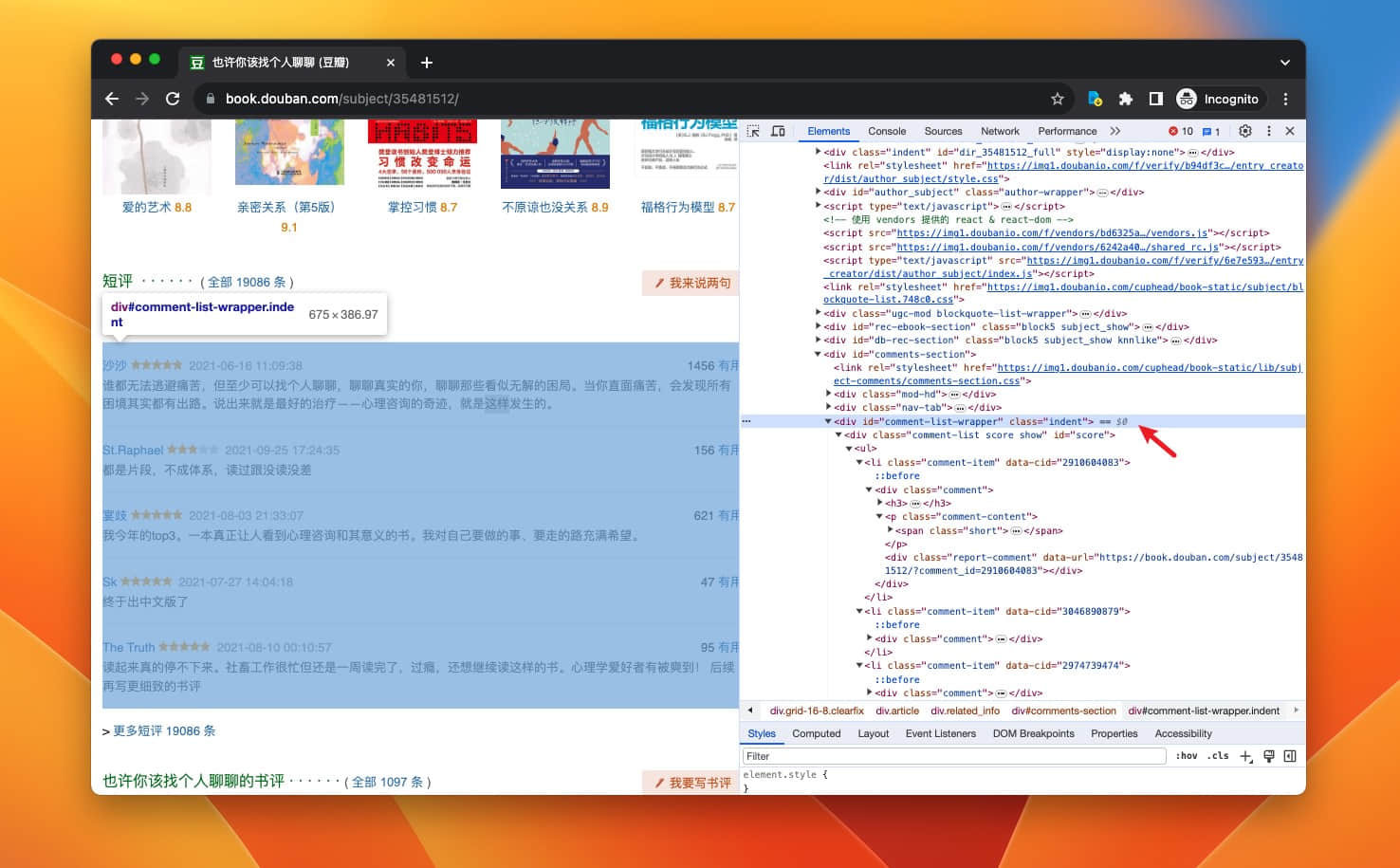
替换其中的 " 号为 ' 单引号。
// 获取热门短评的“渲染”文本
let hotShortComments = document.querySelector("#comment-list-wrapper").innerText;
// 替换所有双引号(")为单引号(')
hotShortComments = hotShortComments.replace(/"/g, "'");
console.log(hotShortComments);
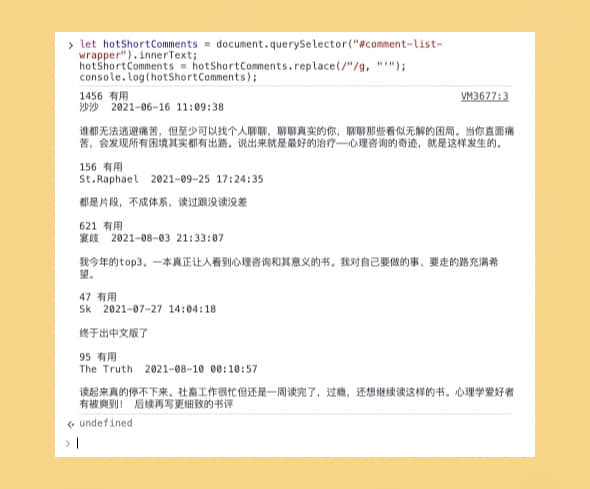
搞定,进入下一环节。
代码整理
这里只说明必要环节,完整代码在下面部分给出。
Database 中还有一个条目没有获取,就是当前页面的链接,这个非常简单,只要一行 JavaScript 代码就可以
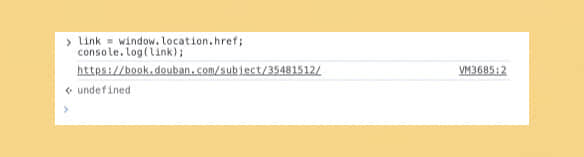
// 获取当前页面的链接
link = window.location.href;
console.log(link);
将所有抓取的信息组合为一个 JSON 字典方便在 Shortcuts 中根据通过键名调用。
// 将所有抓取的信息组合为一个 JSON 字典
let book = {
bookTitle: bookTitle,
rating: rating,
reviewCount: reviewCount,
pageCount: infoJson["页数"],
description: bookDescription,
hotComments: hotShortComments,
ISBN: infoJson["ISBN"],
author: infoJson["作者"],
publicationYear: infoJson["出版年"],
publisher: infoJson["出版社"],
link: link,
csvRow: `"${bookTitle}","${rating}","${reviewCount}","${infoJson["页数"]}","状态","种类","${bookDescription}","${hotShortComments}","${infoJson["ISBN"]}","${infoJson["作者"]}","${infoJson["出版年"]}","${infoJson["出版社"]}","${link}"`,
};
在整个 book 字典中,我额外添加了一个包含所有书籍信息的字符串 csvRow,其中都是用逗号分割的文本,利用这个长字符串可以直接将书籍信息保存为 CSV 文件。
在 console 中测试一下
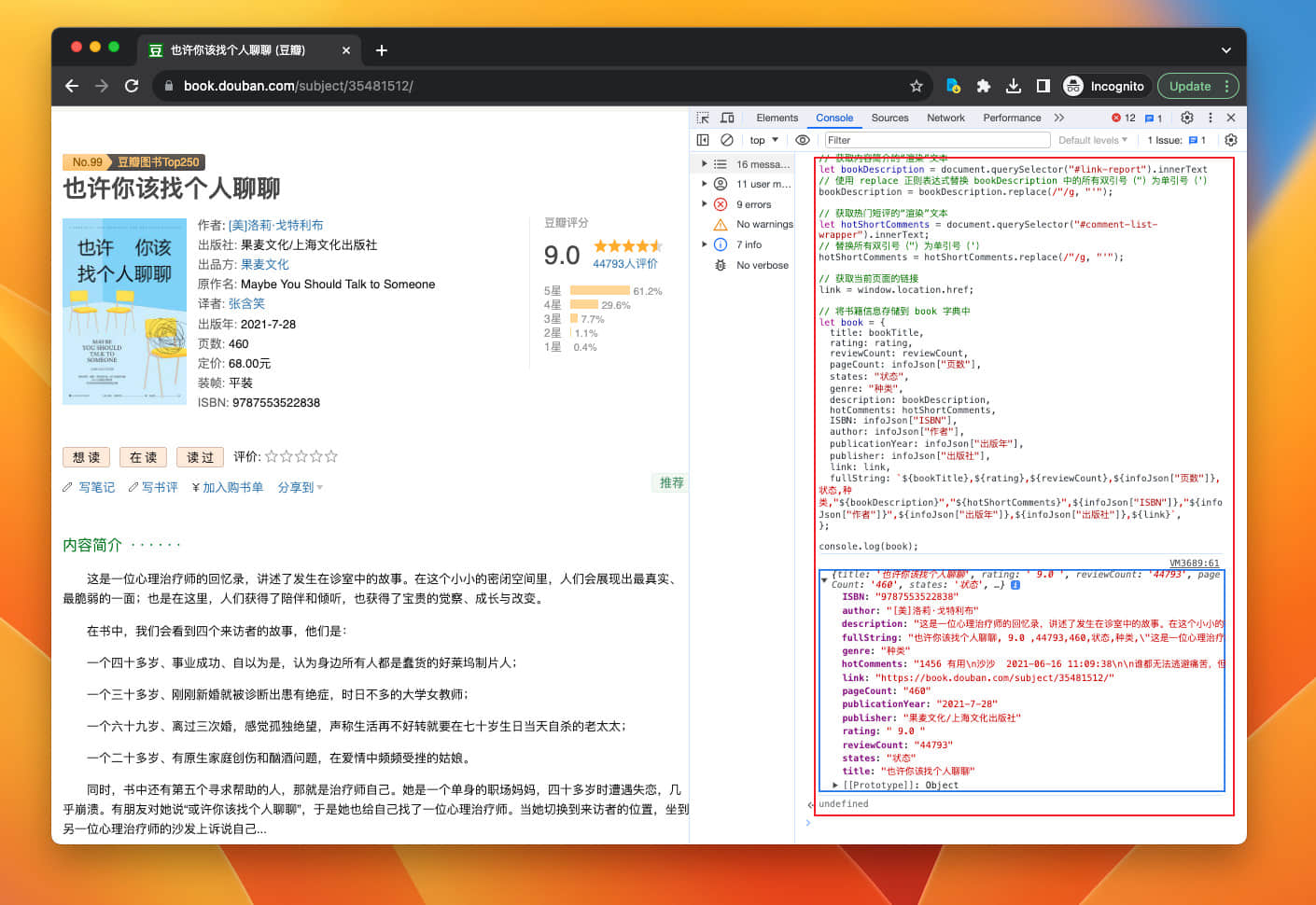
成功获取到所有信息。
截止这部分的完整代码见 Github
处理异常
在获取网页上的信息时,经常会遇到各种意外情况,可能是元素没有成功加载,也可能是网页上没有这个元素,所以我们要进行一些异常处理,来确保当意外发生时不影响代码的正常运行。
这个非常简单,只要通过 try...catch 语句包围原本的代码即可。try 部分尝试执行操作,如果这个操作成功了,那么一切正常,bookTitle 会存储元素的文本内容。但是,如果在尝试执行代码时发生了错误,则 catch 块中的代码会被执行。在 catch 块中,bookTitle 被赋予了一个默认值"N/A"。这样,即使出错,bookTitle 以一个默认值继续运行程序。
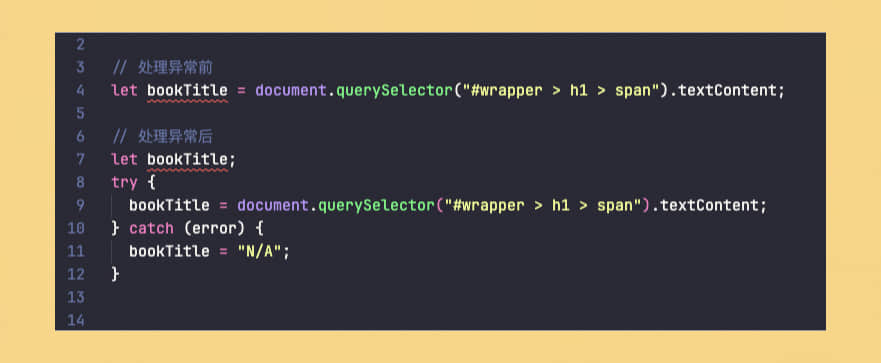
还有一点要注意的是,要在 try{} 外面声明变量 bookTitle。这是因为 JavaScript 的作用域规则。在 try 块里面声明变量会导致这个变量只能在 try 块里面访问得到,也就是说它的作用域被限制在了 try 块内。在 catch 块或者 try 块之后的代码中就无法访问到 bookTitle 变量了。
增加处理异常后的完整代码见 Github
获取完所有信息后,就是保存到 Notion 了。
保存书籍信息到 Notion
创建 Notion 集成(integration)
Notion 通过集成来实现 API 自动化操作。在 Notion My integrations 创建一个新的集成。默认在当前工作区创建集成,随便填一个名字,点击 Submit,保存生成的 API 密钥。
进入之前创建的待读书单 Database 页面,点击右上角 ... 向下滚动到 + Add Connections,搜索刚才创建的集成并选择它。
了解 Notion API
浏览 Notion API 文档,Create a page 看起来像是我们需要的。
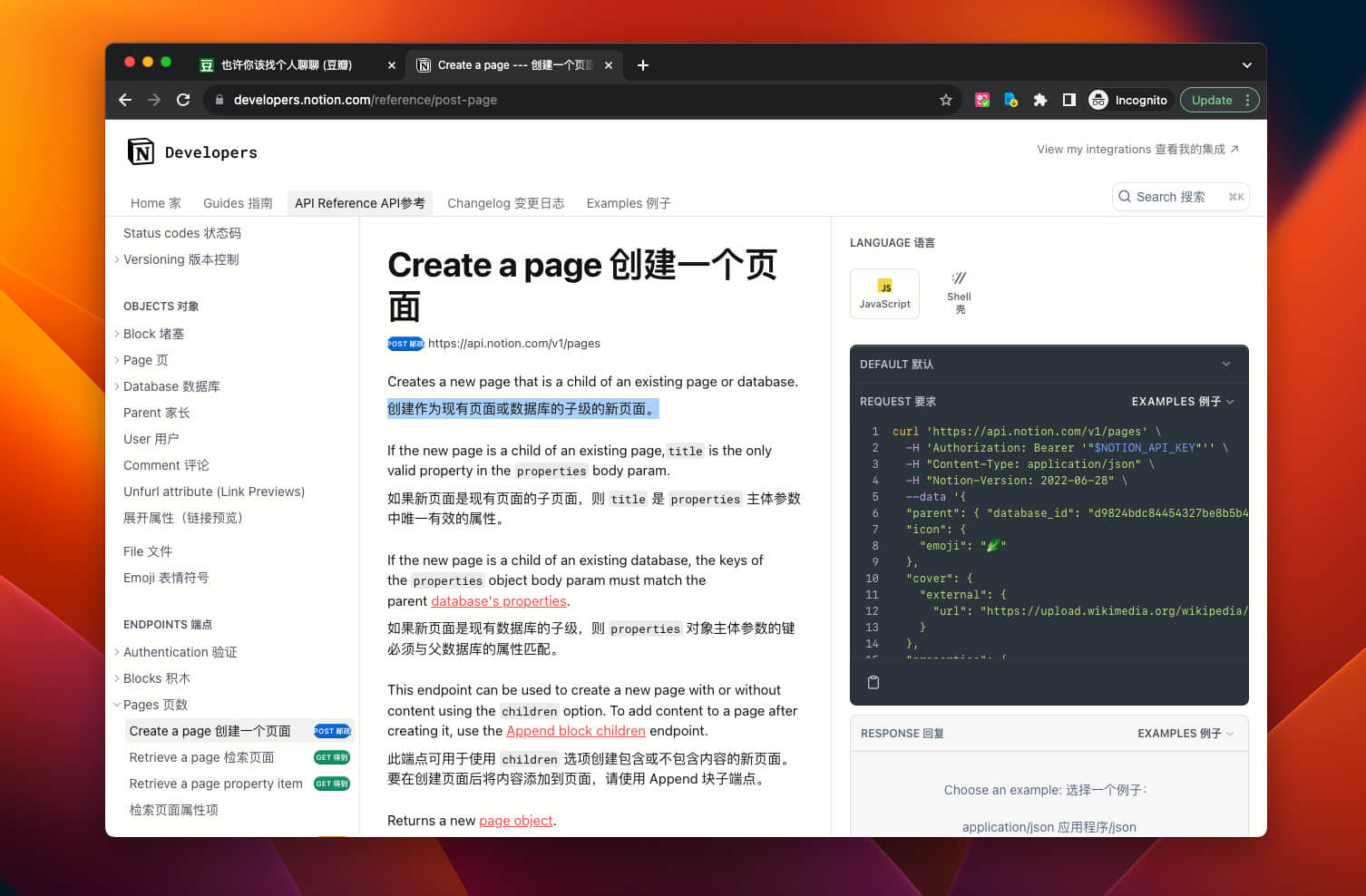
简单浏览了一下,了解到创建作数据库的子级的新页面需要使用 POST 方法。 API 请求必须提供 database_id、properties 和 Notion-Version 参数,请求成功时返回 200 状态码。
在文档中的另一处 Working with databases 部分,说明了如何获取 database_id:
在 Notion 中将数据库作为整页打开。使用 Share 菜单来 Copy link 。现在将链接粘贴到文本编辑器中,以便您可以仔细查看。URL 使用以下格式:
https://www.notion.so/{workspace_name}/{database_id}?v={view_id}在您粘贴的 URL 中找到与 {database_id} 对应的部分。它是一个 36 个字符长的字符串。该值是您的数据库 ID。
了解到必要的信息后,看一下右侧的 API 请求示例。这个示例有些繁琐,提供了很多不必要的信息,先将它精简一下,便于我们学习如何使用。
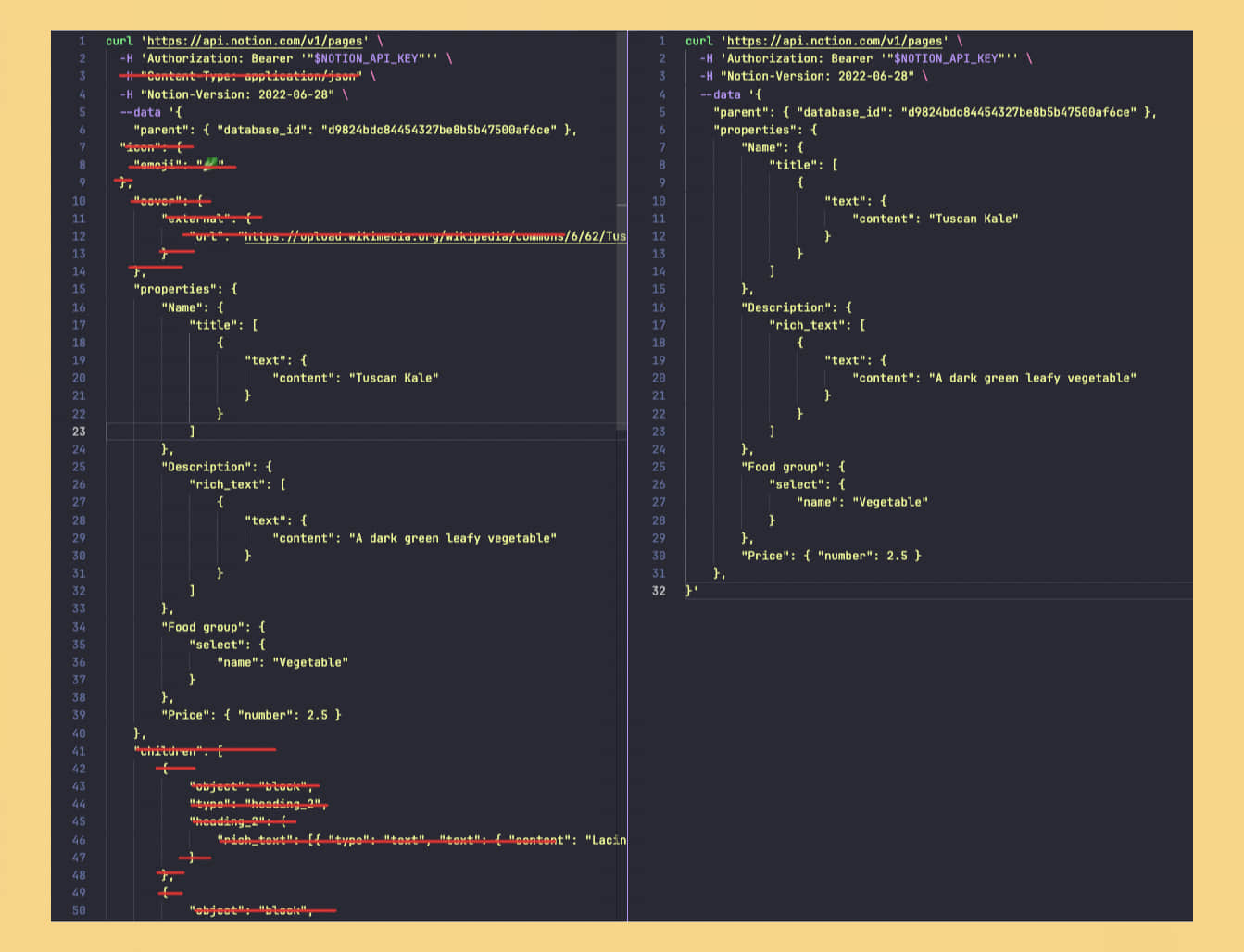
Content-Type、icon、cover、children 这几个参数都是不需要的。
文档中还有一句很重要的话:“ 如果新页面是现有数据库的子级,则 properties 对象主体参数的键必须与父数据库的属性匹配。”也就是说,在提交数据时要同时提交数据库属性的数据类型。
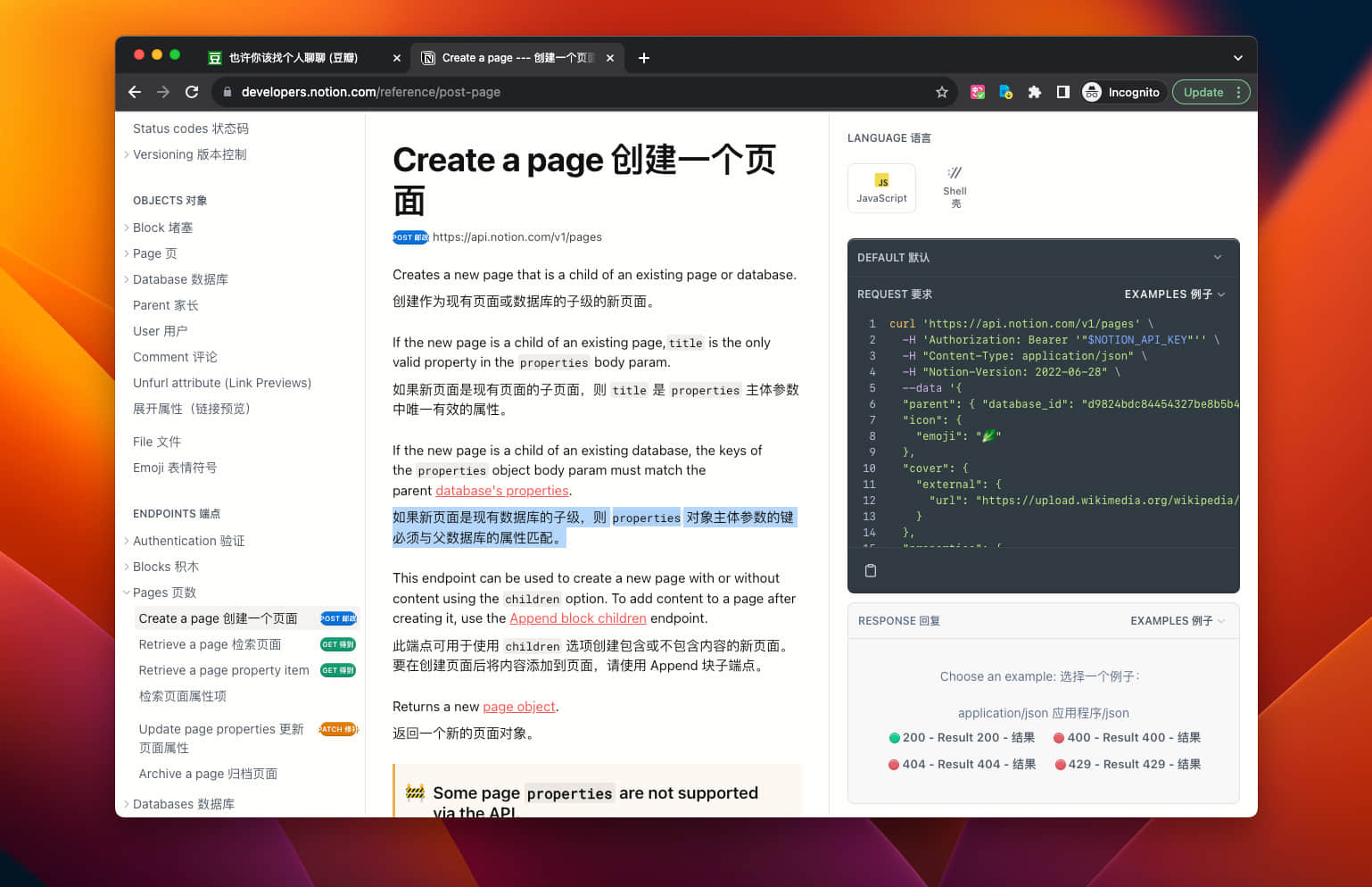
这句话在右侧的例子中的应用是:Price 中要先写 number 然后才是数值 2.5,不能直接写 2.5。
根据以上获得的信息可以制作出一个最简单的 Shortcuts 用来测试 API 请求:
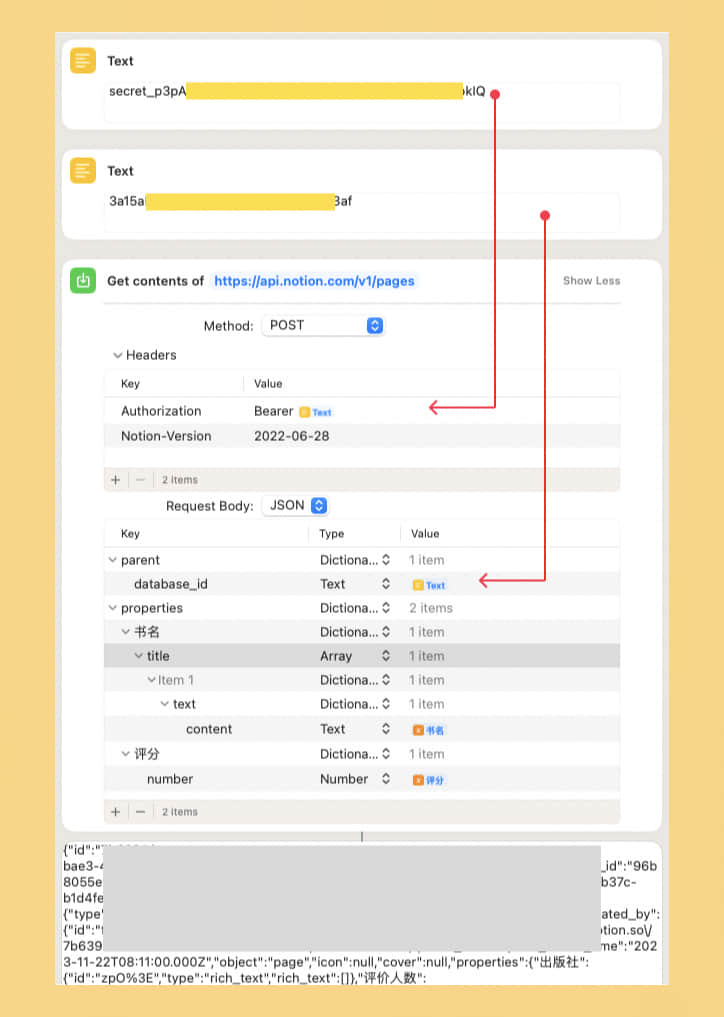
在 Shortcuts 中构造 Notion API 请求是个手工活儿~ 需仔仔细细的正确选择每个选项。
成功向 Notion 发送数据后,会返回一个 JSON 响应。通过这个响应可以大概了解向 Notion 发送了什么数据。
向 Notion Database 发送书籍信息
先从网页的返回值中获取字典(Shortcuts 中动作名字是“从输入中获取词典”),然后将字典中的每个值保存为变量,以便在 API 请求中使用。
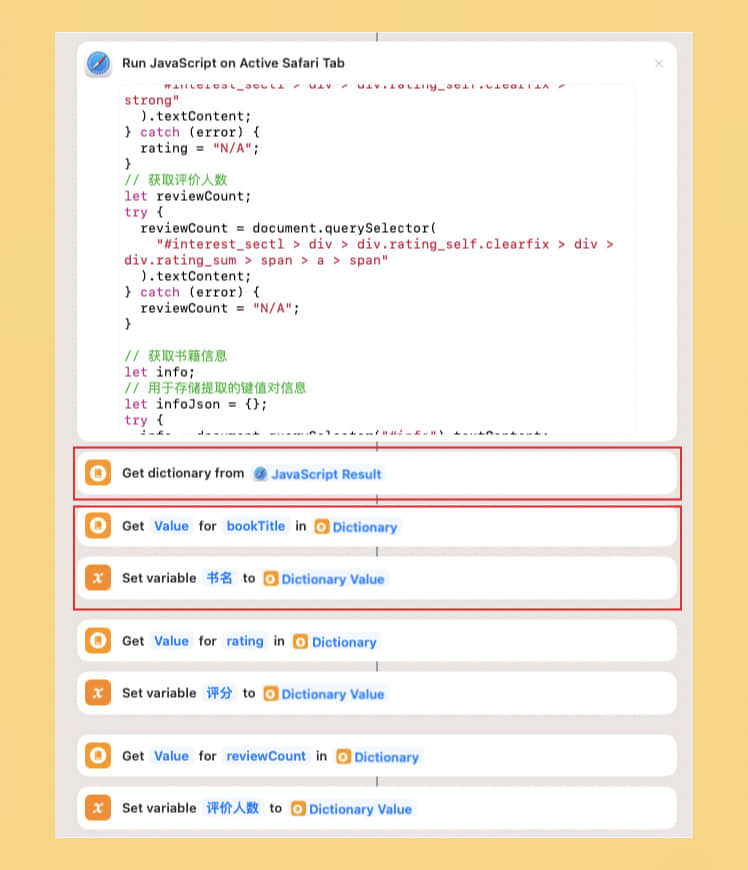
截图中仅展示了部分,未截取完整截图。
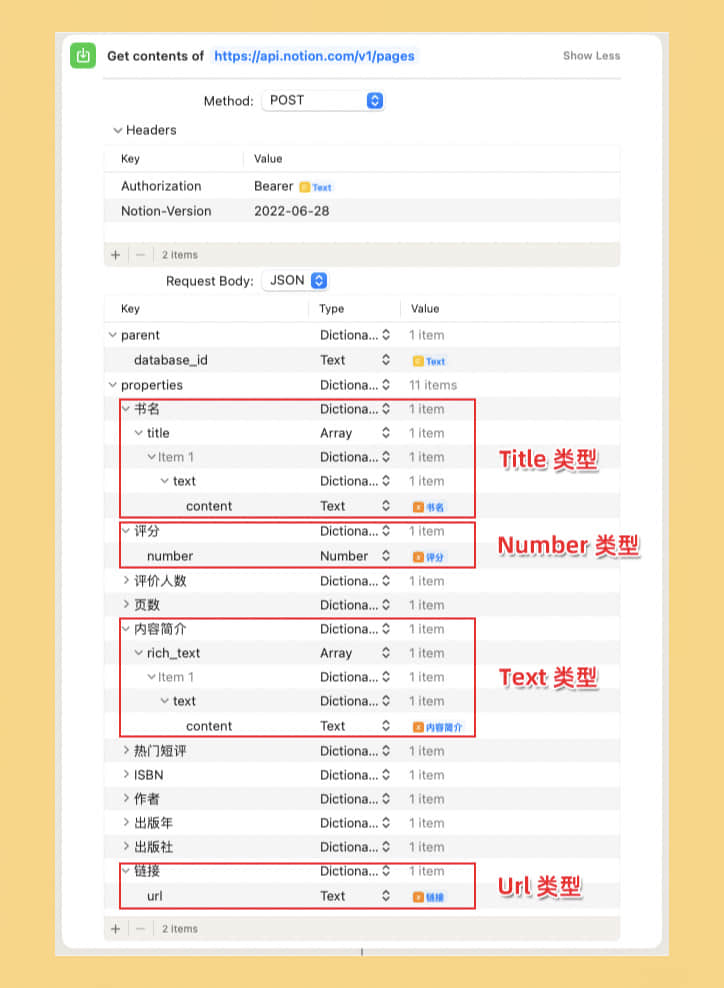
在我们的 Database 中一共有 13 个字段,将其按照类型分类如下:
title类型 1 个:书名text类型 5 个:内容简介、热门短评、作者、出版年、出版社number类型 4 个:评分、评价人数、页数、ISBNurl类型 1 个:链接- 不需要填写 2 个:状态、种类
每一种类型对应一种 API 写法,一共需要 4 种,这 4 种也是比较常用的 Database 属性。
根据类型来构造 API 请求,红框部分依次对应 title、text、number、url 类型该如何在 Shortcuts 中构造请求,仔细地的填入正确的选项即可。
在下方可以加上一个“显示结果”动作,方便了解 Shortcuts 运行结果。
加一道保险
为了避免碰上 Notion 无法访问的情况,可以在请求 API 之前,先将数据保存一份 CSV 到本地。
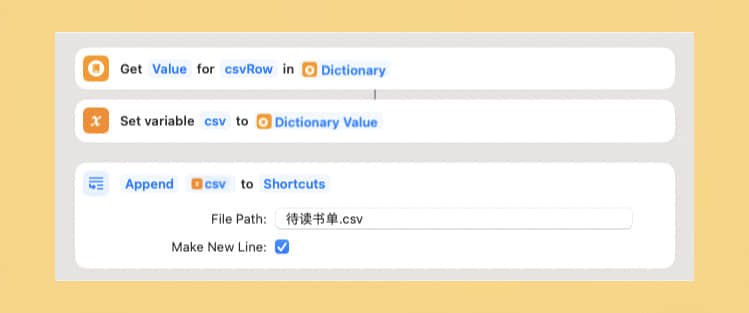
想进一步了解 Shortcuts 和 CSV 可阅读《Shortcuts 结合 CSV,在本地创建、读取和修改表格》