

许多刚刚上市的电子书,往往是英文或其他语言先行,随后半年甚至几年才发布中文版,以至于孜孜于阅读的读者们,要么悬梁刺股苦学外语,要么草船借箭淘台版书,更多的则是嗷嗷待哺干等简体中文版(但不少书可能永远不会有中文版)。
其实相当一部分书,我们读的是书中“资讯”而非阅读享受,尤其是近年刚刚出版、尚未成为书林经典的书籍——特别是《解密 Instagram》《巨人的工具》等人物传记和商业书——主要目的就是看个故事、学点技巧,而非读小说、诗歌或历史那样沉浸其中。一旦明确了“获取资讯”这一目的,使用机器翻译也就无伤大雅。
本文将分享一套外文 epub 转换为中文文档的方法1,支持输出 Word 文档或者 PDF,保留原始排版风格,无需安装任何软件,不用注册任何帐号,还不用掏钱。

文章演示的具体操作在 macOS 下进行,由于不依赖特定工具,Windows 甚至 iOS 也可以如法炮制。
转换流程
epub 其实是一份打包好的“网页”,其结构比较复杂,拥有表格、配图、矢量文件等元素,大概是这个原因,你可以搜到不少“在线 PDF 翻译”“在线 Doc 翻译”,却很难觅得“在线 epub 翻译”。所谓的 epub 翻译,其实就是把 epub 文件转换成其他常见格式后再进行翻译,收获的文件也以 Doc 或 PDF 居多。
并不推荐直接使用格式转换工具处理 epub,如果是纯文本电子书倒也无可厚非,但在转换带图片的 epub 时,“傻瓜式”的一键格式转换工具容易造成排版错乱,所以本文更推荐手工操作。
另外,似乎直接将 epub 打印成 PDF、旋即使用 PDF 翻译工具也是一条诱人的捷径,实际上,将外语译成中文后文字篇幅会有较大变动,排版会错得离谱、不是稀稀拉拉就是溢出页面,即便本文的要求已经放低到“获取资讯”而不奢求享受,读这种支离破碎的文档也实在是摧残自己。
总之,接下来的方法介绍就从 epub 电子书的预处理开始。
将 epub 电子书预处理为 Doc
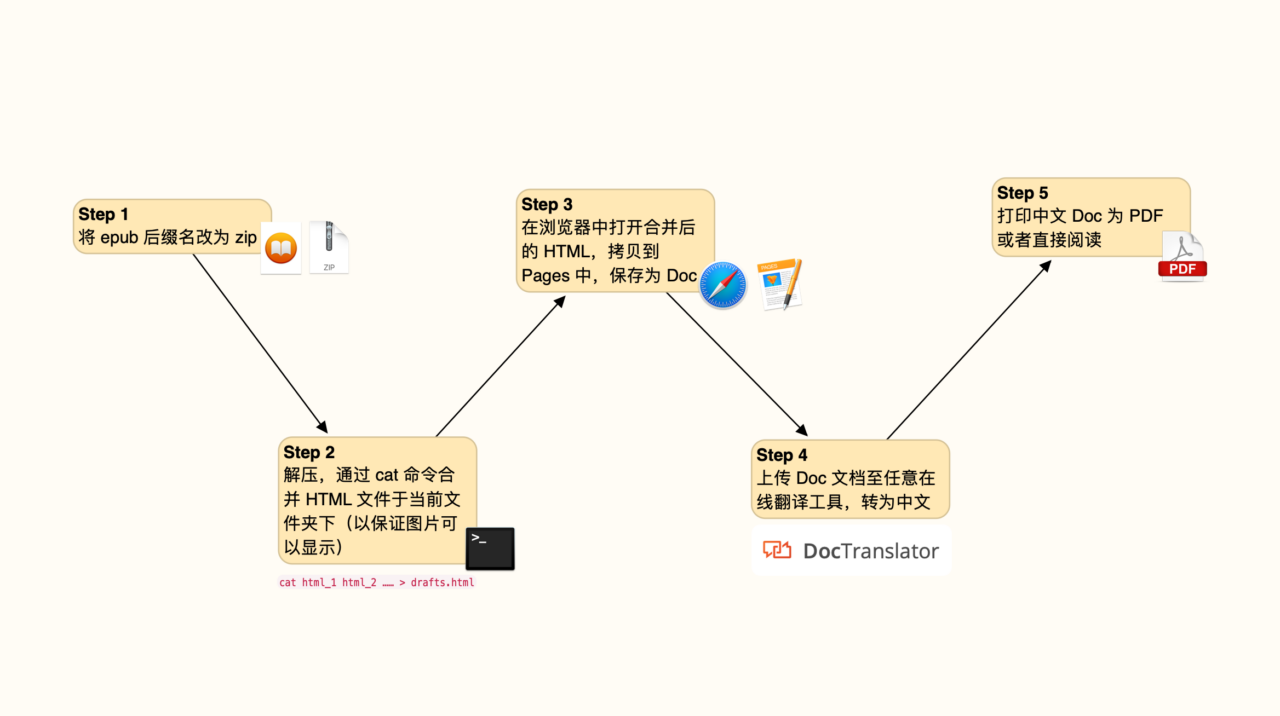
处理 epub 的第一步就是将其还原为基础的“材料”。如前文所述,一个 epub 文件本质上是一个压缩包,所以我们可以径直将其后缀名改为 .zip 并双击打开,通常马上可以看到其内部结构。
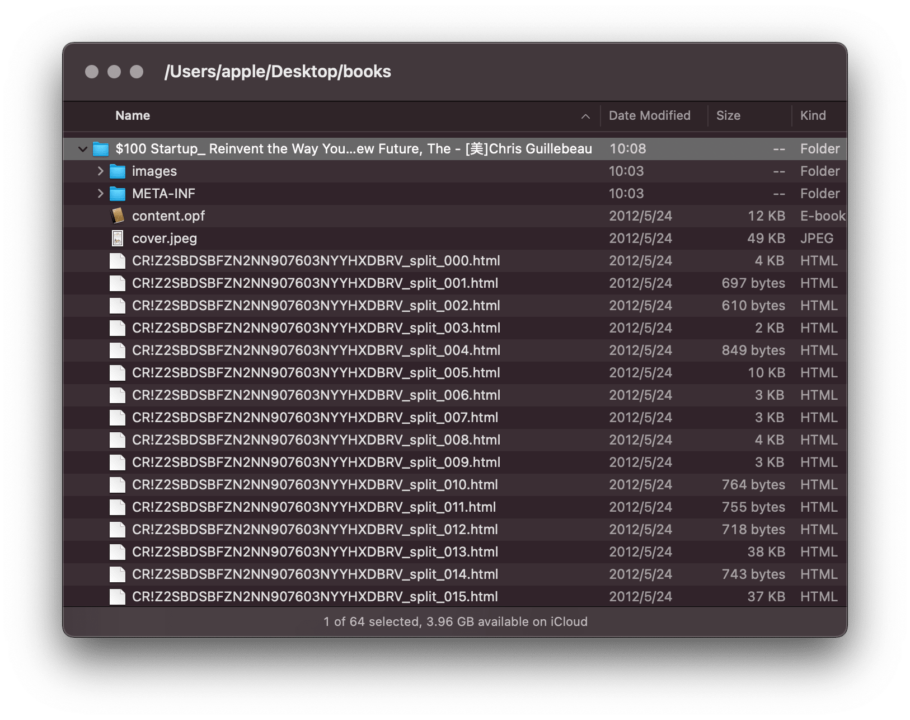
奇怪的是,我从 macOS Big Sur 开始就发现系统经常无法解压这些改过后缀名的压缩文件,不过随便下载一个第三方解压工具就能打开,这一现象无法验证是否为个案,建议遇到类似问题也试试第三方工具。
从上图中可以看到,epub 内部拥有大量 HTML 文件,这也是将 epub 视为本地网页的原因。当然,epub 不是从网上加载图文素材,而是从本地调用配图。现在,需要将这些分散的 HTML 文件合为一份,以便随后将其转换为独立文件,而非当前凌乱的状态。“合并 HTML”听上去是个偏门得不能再偏的需求,其实实现起来非常简单:HTML 也是一种纯文本文档,完全可以用一行命令来搞定:
cat 文件1.html 文件2.html 文件3.html …… > 输出文件.html
其中 文件1.html 文件2.html 文件3.html 犯不着手动输入,直接全选 epub 内部的 HTML 文件后拖进终端(Terminal)即可。当然,为了保留书籍的章节顺序,拖进去的文件也应当按顺序排列,为此可以先选中第一份 HTML(编号可能是 000),按住 ⇧Shift 键后再选中最后一份 HTML 文件,这样拖入的文件就是顺序排列的。
偶尔也会遇到解压后只有一份 HTML 文件的情况,那就可以不碰命令行,直接跳到之后的步骤。现在,把合并后的 HTML 文件放在 epub 文件夹中,使其可以读取到 epub 中的配图等素材,否则会丢失图片。接着在浏览器中打开这份 HTML,即可看到保留了原电子书排版的离线网页。现在你有两个选择,如果待翻译的是一份小册子或仅仅是书中的一章,页数不多,那么可以马上使用 Safari 的自带翻译引擎,不用再做多余的事情即可得到中文页面!

如果你想翻译的是整本书,则 Safari 可能会报错,不过根据我的经验,这个阈值大概是十万字——一般的书都够用了。配合《一种几乎永不失效的网页中英对照翻译方案》中的中英文对照翻译方法,还可以输出一段英文、一段中文的文档,方便比对阅读。

将外文 Doc 翻译成中文文档
继续处理 Safari 中的文件。首先,按下 ⌘Command-A 全选当前页面的全部内容,将其复制到 Pages 或 Word 等富文本编辑器中(这样才能保留原文排版),并导出为 Doc 或 Docx 格式。这一步视电脑性能而耗时不同,作为参考,导出7万字左右、每章有几幅插图的英文电子书大概需要十几秒,而字数更多、配图更丰富的书籍可能会更耗时。

获得 Doc(包括 Docx 格式)文件后,就可以着手翻译工作。
等到导出了 Doc 文件,整个翻译过程已经成功了一大半,毕竟翻译 Doc 文档的工具选择余地很大。搜索一下 Doc 在线 翻译 就能获得一堆工具,我通常选用的是 DeepL。这些翻译工具的使用方式都大同小异,上传文件并选取目标语言后,即可开始翻译。
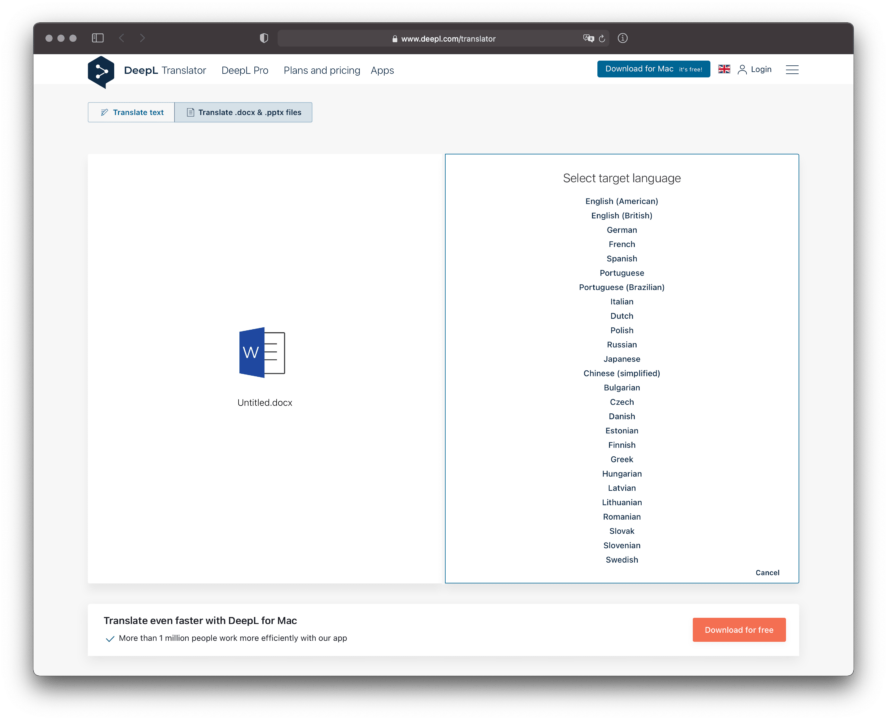
由于每本电子书的篇幅、排版和配图数量差异较大,很容易遇到某个翻译工具崩溃而其他工具奏效的情况,多试几款翻译工具即可,除了 DeepL,我还备有 Doc Translator、有道文档翻译 或者 Google Docs 的翻译功能。注意,如果你使用的是在线服务而非离线工具,请勿翻译任何内部文档,避免造成数据泄露、染上麻烦。
翻译完成后可以下载 Doc 文件,有些翻译工具也提供了 PDF 格式下载,青菜萝卜各有所爱,用哪种格式全看读者自己的需求。下面是我下载的 PDF 格式译本,基本保持了原文的排版,标题底色、引言居中、首字放大(Initial)等细节都有保留,就“获取资讯”而言,这样的排版效果没什么好挑剔的。

其他格式电子书的处理
外文书籍并非总是 epub 格式,比如美亚(美国亚马逊)上购买的书籍就是 azw3 格式,有些较早的书籍可能还提供 mobi 格式,均需要先转换成 epub 才能处理。这里涉及一些 DRM(Digital rights management,数字版权管理)保护的问题,道德方面本文不做评价,但是因为我国大陆地区《著作权法》豁免范围较小2,故本文不能介绍“去除保护”相关方法,只能介绍后续的格式转换。
下图是我以 Kindle 为例整理的电子书格式发展关系图,理论上除了最新的 KFX(一种较新的 Kindle 电子书格式,不过我还没买到过这种格式的作品),mobi 和 azw3 都可以转换为 epub 并尽可能保留原始排版。
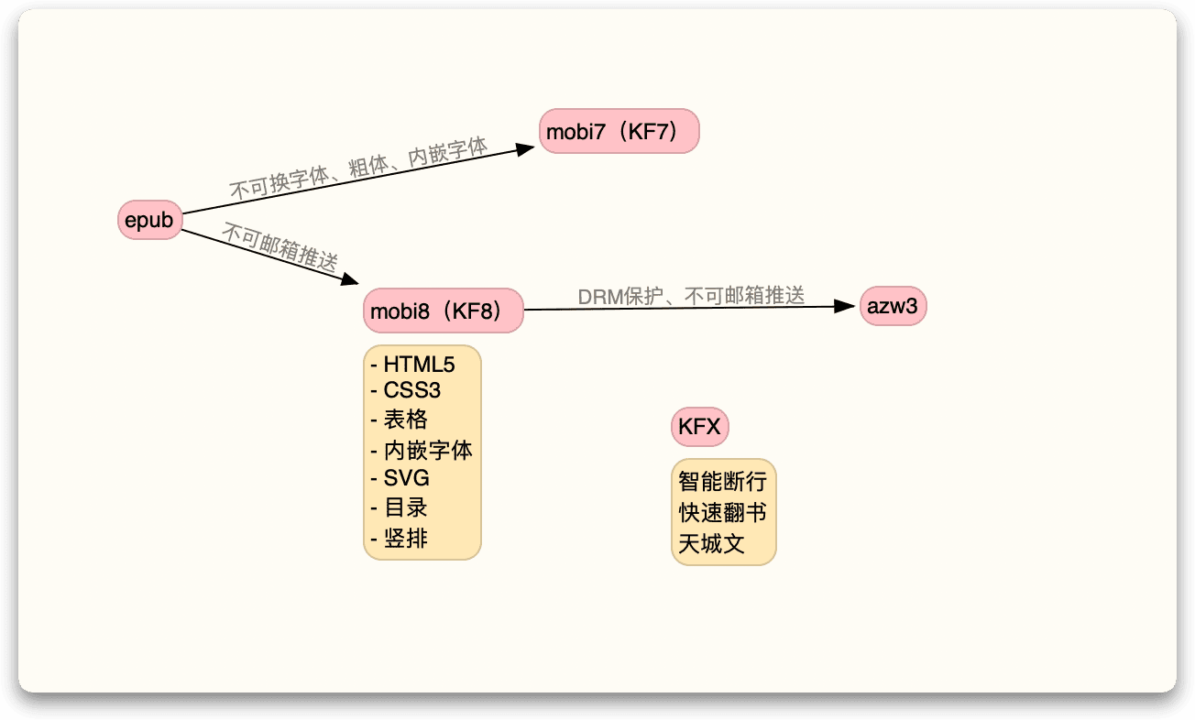
推荐使用的格式转换工具是 Calibre,它覆盖了上图 KFX 以外的多数格式,从美亚到日本、台湾主流书商处买到的电子书基本可以转换(只要书商提供电子书下载)。而只要得到了 epub 格式的文件,剩下的翻译方式则与前一节无异。
小结
中学时,常被老师教导“(hǎo)好读书不好(hào)读书,好(hào)读书不好(hǎo)读书”,这说的是年轻时脑力正盛却不喜欢读书,等日后来劲儿了早已精力不再,以此劝君珍惜光阴;现在读外文书、特别是有时代性和时效性的商业书,我也喜欢用同样一句话鞭策自己,意思却大有不同,前后半句也要倒过来念,谓之“好(hào)读书不好(hǎo)读书,好(hǎo)读书不好(hào)读书”:发现一本好书的时候没有中文版,等条件允许、出了中文版,这些书早已成了明日黄花或者变成“全民读物”,让人失去了阅读的兴趣3。
就以获取资讯为目的的外文书而言,不如趁刚上架时就自制一份机器翻译版,只为了解故事和偷师学艺而已;如果此书果真经得起时间检验,等中译本出版后再读一遍也不吃亏。