
在自我提升时警惕虚假指标
作者:Hum
摘要:对虚假指标脱敏的办法是停止自我感动,在自我感动处自我怀疑。面对指标,尽量想清楚它的意义,别别人定个指标你就听。不自己想清楚,就会陷入别人给你设计的思考轨道。意识形态这个领域,总要有个主人,你放弃做这个主人,就会自动被别人的模式填塞。
标签:自我提高, 屏幕时间, 任务管理
在 Wired 读到一篇文章《Tracking Screen Time Is Ruining Your Life(跟踪屏幕时间正在毁掉你的生活)》,讲的是作者 Sarah Hagi 从拥抱屏幕时间,到因为屏幕时间产生焦虑,最后拒绝屏幕时间的故事。拧巴的逻辑一下激活了我对所有“量化自我中的虚假指标”的记忆。
先从文章说起。
Sarah Hagi 对屏幕时间的焦虑产生于和朋友们的谈话。当作者知道(工作和互联网无关的)朋友的屏幕时间是 3 个小时,而(作为科技作者的)自己的屏幕时间是 7 小时后,她陷入了反思和焦虑。她删除社交 App,但憋不住用浏览器继续浏览;她把手机调成灰度(黑白屏幕无其它色彩);她把手机放到室外充电;她还下载了防止打开其它 App 的 App……
但她发现这一切于事无补,最终她写道:
I learned an important lesson: The amount of time you spend on your phone doesn’t actually matter, and you’re better off keeping those numbers a mystery.
我学到了一个重要的教训:你花在手机上的时间实际上并不重要,你最好让这些数字保持神秘。
她关掉了屏幕时间。剩下的文章,她试图论证这一行为的正当性。
屏幕时间仅是一个辅助数据
一个很明显的错误是,把屏幕时间简单地看做“坏”,越长,越坏。
这句话一旦写出来,读出来,正常人都能意识到问题。展开来说,有两个方面:一,屏幕时间只是综合辅助指标,二,“好坏”要看标准是什么。
一个综合指标,特别是屏幕时间这样如此综合的指标,没有办法讲述细节。这是定义上就能读出来的。综合=细节不够。最简单的例子,比如说“平均工资”。
屏幕时间是一个人用所有应用程序的时间的和而已。它不会反映任何细节。大概只有很少的情况下也许有直接指导意义,比如一个人一天用 20 小时手机。这说明 ta 睡眠时间可能不够。但这也有争议。比如有人需要晚上 YouTube 播放一个视频助眠1。这样 ta 屏幕时间超过 20 小时也不是不可能。
更重要的是,“好坏”的标准是什么。不同的人,不同的时期,不同的环境,“好坏”的标准可太不一样了。做为科技作者,Sarah 比非互联网从业者的朋友人更频繁查看手机获取信息再正常不过。如果她是个游戏职业玩家或者代打,又或者有些憋着 iPad Only 的科技作者,那更长也没问题。这就像健身教练、健身运动员比正常人在健身房呆的时间长一样天经地义。
所以屏幕时间只能是一个辅助数据。你必须把它打散了,再结合自身情况,才有可能知道是“好”还是“坏”。比如说,学习用的 App 用了多久,娱乐的用了多久。
但如果再深分析,会发现,哪怕打散它,它也不能定义好坏,它也仅是一个辅助数据。因为我们只能用它统计时间,但不能获取行为细节。它只能统计看了多久 YouTube,但不知道看的是公开课还是搞笑视频。再往深了说,搞笑视频算“坏”吗?
屏幕时间的合理用法
屏幕时间做为一个辅助数据,它的合理用法只能是提供“时间”方面的统计信息。利用这一点,我想了两个,可以抛砖引玉一下:
第一个,计算做一件事用了多久。比如一位接私活的设计师,他要根据工作时间来算报酬。通过屏幕时间知道自己用了多久的设计工具,就能相对精确地统计自己的工作时间。
第二个,计算单位时间内的效率,但前提是这一段时间内的工作单调且重复,不涉及太多创意。比如一个做文书工作的白领。可以通过用 Excel 的使用时间和处理的文件量来算工作效率。
屏幕时间的最大价值
屏幕时间的最大价值,是在一个人无意识的时候进行的“自动统计”。这种自动统计比通过意识主动统计好很多。因为主动统计不仅不准,而且会因为个人的价值观而变得不可信。
不准体现在忘了 check-in 和 check-out。我用过太多这样的工具,至今很难保证百分百准确的打卡。
而主动统计的不可信则是一个基于人性的不可避免发生的事。这就是因为人心里总有“好坏”。有“好坏”,就想多一点“好”而少一点“坏”。就会自欺欺人。但为了自我提高进行的数据统计,骗自己就失去了所有意义。
各式各样的虚假指标
屏幕时间只是个引子,只是因为我恰巧看到了这篇文章。但比屏幕时间荒唐的虚假指标不胜枚举,在此简单罗列一些,排名不分先后:
RSS 阅读篇数多、剩余篇数少
社交时代刚开始开始,读 RSS 的人就有一种莫名的优越感了。随着推荐算法逐渐统治,使用 RSS 的人的优越感逐渐攀升。甚至有人会在招聘时以是否阅读 RSS 来判断人信息源的好坏。在这无根的优越感之中,最莫名其妙的是读的多,读得完的人。多年前在我的某一篇文章的评论里,出现了自称日读 3000 篇 RSS 的人。我一下惊了,就是说他一天 24 小时全阅读,每小时要读 125 篇文章。
RSS 的阅读数量和完成度,充其量和一些事情有某种相关性,但这种相关性远不到可以产生自豪或者自卑的程度。
稍后读读的越多越好
这和 RSS 是一样的事,反思却产生在我自己身上。我早先写过不少稍后读和信息处理流程相关的文章,算是个拥趸。但直到 2019 年我从 Pocket 获得了一封邮件,里面告诉我是 Top 1 的读者,读了 740 万字,我陷入了沉思。
和刚才同样的计算。一年读 740 万字,365 天不休息,平均一天 20000 字。这虽然不算夸张,但我懂得了什么?更重要的是,如果我读的是论文,这可以是 740 篇 10000 字的论文。这两者的信息质量差了多少?
这所谓的“一年读 740 万字”,我是珍惜了时间,还是浪费了时间?
读多少本书
读书在很多人眼里还是很神圣很正面的事。这很难讲,但无论如何没办法仅仅通过数量一个维度来评价。看完前面的 RSS 和稍后读,你会意识到这是同一个思维陷阱。“一年读 54 本书就能如何如何”的说法,有可能是来自于出版社。
一个可以使用的参考维度是,你可以读多少让你真正引用的书。所谓真正引用有以下几个可能性:
- 写论文引用。这代表这本书是领域公认的专业书籍,而你在一个被认可发论文的机构。
- 写严肃报告引用。同上。
- 做投资决策。这不必写作和发表,但这本书里的某些信息是决定你采取某个投资决策的关键信息。这种情况一般很少发生,因为等书都出版了,时机早已过去。
任务完成数统计
Todoist 里有个 Karma 系统。Karma 系统记录任务完成数量,给予用户相应的等级。任务完成得越多,级别越高。最高级别是“Enlightened(开悟)”,需要完成 50000 个任务。
如果一个人到达了“Enlightened(开悟)”还会高兴和庆祝,还不能领悟到这个任务完成的数字和“Enlightened(开悟)”没有任何关系。那某种程度上也算是开悟了。
虚假指标的来源和坏处
除了上面的例子,在几乎任何领域都充斥着大量的虚假指标。多所美国大学甚至已经退出以论文发表和引用为主的世界排名系统。这些虚假指标之所以通行,根底或许源自于人的愚蠢、懒惰、虚荣,但更直接的,是我们不去对评判标准反思,甚至崇拜一种一刀切的评判方式——分数。
从小被分数评判的我们容易对分数产生依赖。这是一种来自错误教育系统的 PUA 引发的自我 PUA,还有可能对下一代进行这样的 PUA。但考试的分数,也只是一个评判我们在一个考试体系所设计的题目里能掌握百分之多少,仅此而已。所有的分数都只是一个参考指标,它只是帮你知道哪里没有掌握到位,并不在于和别人比较的时候位置在哪。学习中的排名有应试的特殊意义,这让人们更加迷失在分数和排名之中。每一次考试不应该是结束而是开始,但几乎所有人都弄反了。
再进一步地说,任何考试的体系都会根据不同的情况而产生变化。比如在允许教神创论的地方你回答的全是支持进化论的,得不了高分。但在以进化论为唯一答案的地方探讨其它生命来源的可能性,可能更加危险。工作里也有很多指标是一样的。在一种形势下重要的指标,在另一种形势下马上会变得次要。如果公司意识不到这一点,公司就会落后于时代。如果公司意识到了这一点,而有的员工没有意识到这一点,还在拼命追求前一个热门指标,那这种员工就会被优化。被优化的时候可能还很郁闷,“我分明和以前做得一样好”。
当陷入对分数的依赖,就会陷入一种错误方向的自我感动。人会变得越来越关注参考数据。当实际结果仍然不理想,还是会告诉自己“努力”了。因为数据在那摆着——一星期天天去健身房,还能有错了?
更深层的问题是,这种感动很有可能是别人设计给你的。比如“一年读 54 本书”,它很可能是出版行业、贩卖焦虑靠卖书拿提成的视频博主给你设计的目标。而这些编辑和这些视频博主一年也读不了 54 本书。
对虚假指标脱敏的办法是停止自我感动,在自我感动处自我怀疑。面对指标,尽量想清楚它的意义,不要别人定个指标你就听。不自己想清楚,就会陷入别人给你设计的思考轨道。意识形态这个领域,总要有个主人,你放弃做这个主人,就会自动被别人的模式填塞。
直接用 Siri 让 HomePod 播放 Spotify
作者:文刀漢三
摘要:HomePod v17 软件的发布,让 HomePod 获得了用 Siri 播放 Spotify 的能力。
随着 iOS 17 发布,HomePod 也发布了软件 v17 更新,其中有一条更新说明是:
Siri 支持隔空播放,让你直接在 HomePod 上通过语音即可从 iPhone 或 iPad 开始隔空播放会话,以便在 HomePod 上播放范围更广的第三方音乐服务。
这也就意味着,你可以直接通过 Siri 让 HomePod 播放 Spotify 等没有适配 HomePod 的三方音乐服务了。
首先你需要在家庭 app 中,打开识别个人声音。然后对 HomePod 说:嘿 Siri,用 Spotify 播放 XXXX。
第一次使用时,可能需要在 iPhone 上允许 Siri 对 Spotify 数据的访问权限。经过我的测试,播放歌手、专辑、歌单、单曲都没有问题。
这里实际上有两步操作,首先是将 iPhone 连接到 HomePod 使用隔空播放,接着是通过 Spotify app 播放音乐。以至于我曾经做了很多个快捷指令用于快速播放 Spotify 音乐。更新到 HomePod v17 后,通过 Siri 就能一步操作。
HomePod 实际上有对三方音乐服务提供 API,三方适配后就能通过 Siri 唤醒 HomePod 播放,除了苹果自家的 Apple Music,像网易云音乐、QQ音乐等,都已经适配了 HomePod API。但由于 Spotify 这几年和苹果之间的流媒体战争,Spotify 并未支持 HomePod API,于是无法直接通过 Siri 播放。好在最新的 HomePod 版本提供了 Siri 隔空播放三方应用的能力,让我们得以曲线实现。与原生 API 相比,Siri 隔空播放需要你的 iPhone 或 iPad 在同个局域网下,而原生 API 则可以不需要 iPhone 或 iPad 设备独立播放。
在 iOS 17 使用 Spotlight 运行 App 快捷指令
作者:文刀漢三
摘要:在 iOS 17 中,Spotlight 的搜索能力被进一步增强,app 快捷指令会显示在最佳搜索结果中,方便你快速进行下一步操作。
我属于“简约桌面派”,不会在桌面上放太多应用图标,入选的应用分为两类:
- 每天都会用到应用,比如浏览器、相机、相册、记账软件等。
- 偶尔用到一次,每次用都特别着急的应用,比如地图、词典、计算器等。
此外,像日历和任务管理应用,由于我会在桌面放置它们的小组件,通过小组件也能打开应用,因此对应的图标也被我从桌面删去。剩余的应用,我都通过 Spotlight(聚焦)搜索查找。
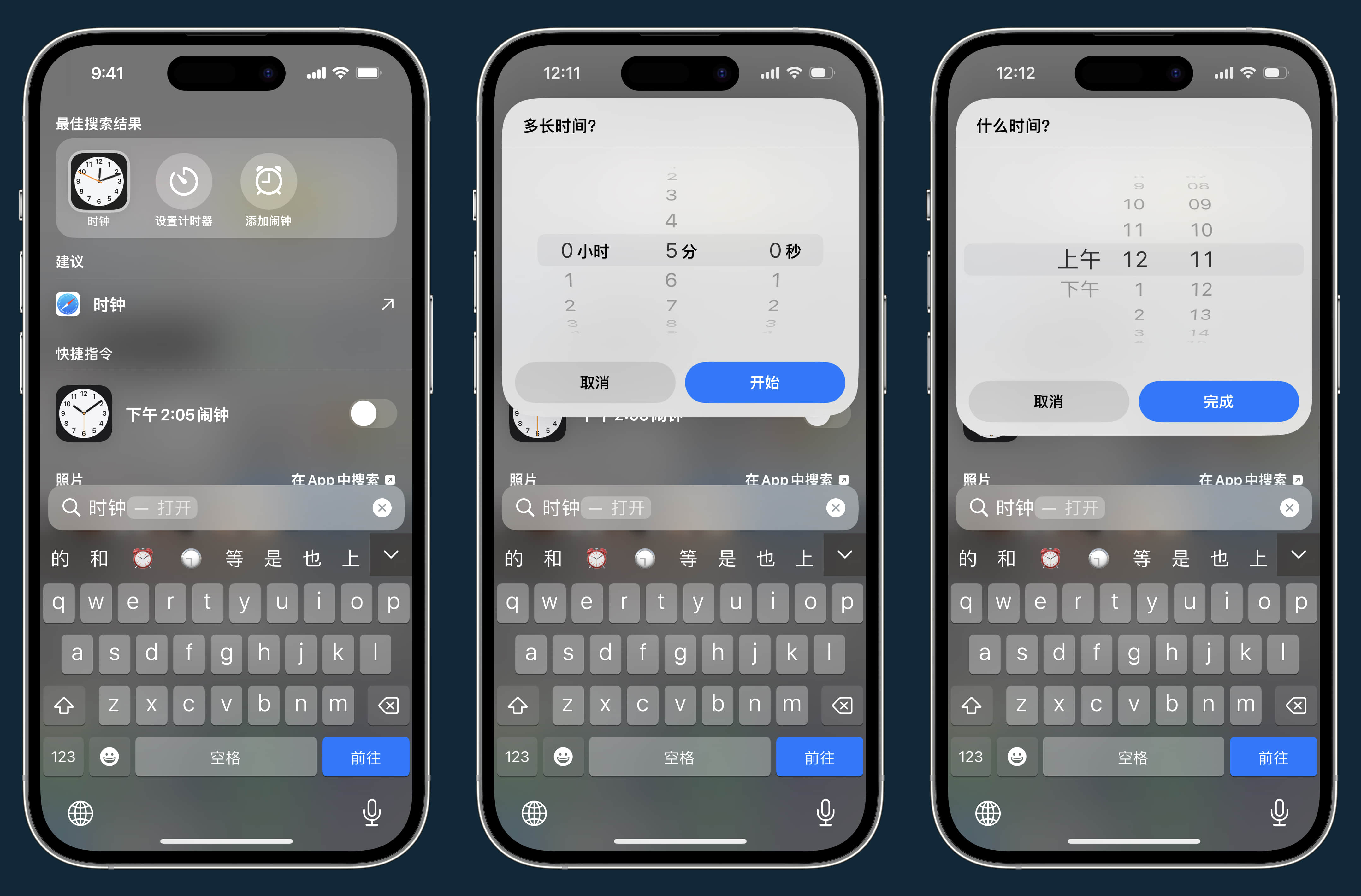
在 iOS 17 中,Spotlight 的搜索能力被进一步增强,app 快捷指令会显示在最佳搜索结果中,方便你快速进行下一步操作。
比如时钟应用,可以快速设置计时器和添加闹钟,并且所有操作都在 Spotlight 中进行,无需进入到应用中。
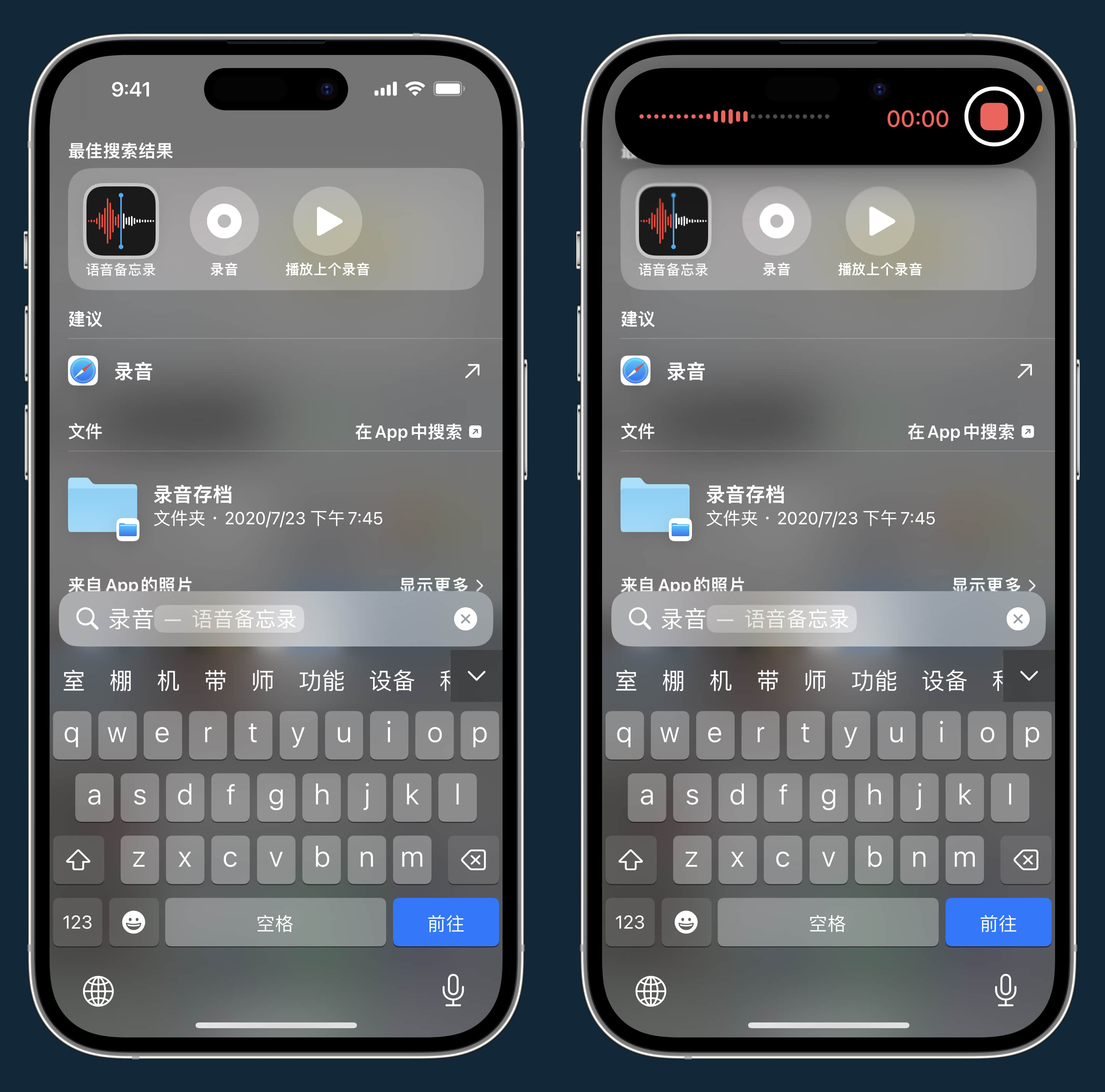
语音备忘录也可以直接开始录音:
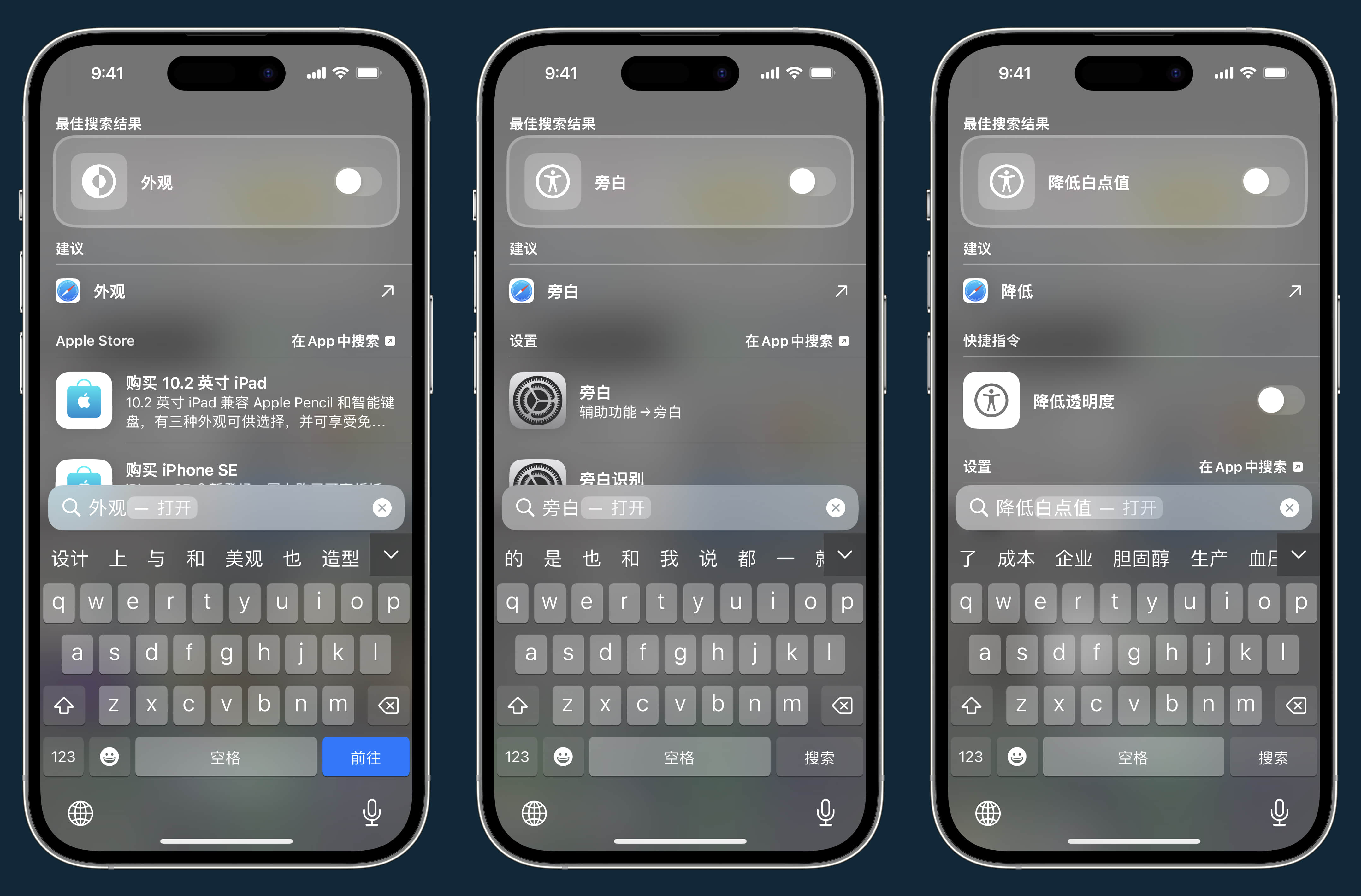
设置里的部分开关,比如浅色/深色模式、旁白、降低白点值等,也可以在 Spotlight 里直接开启:
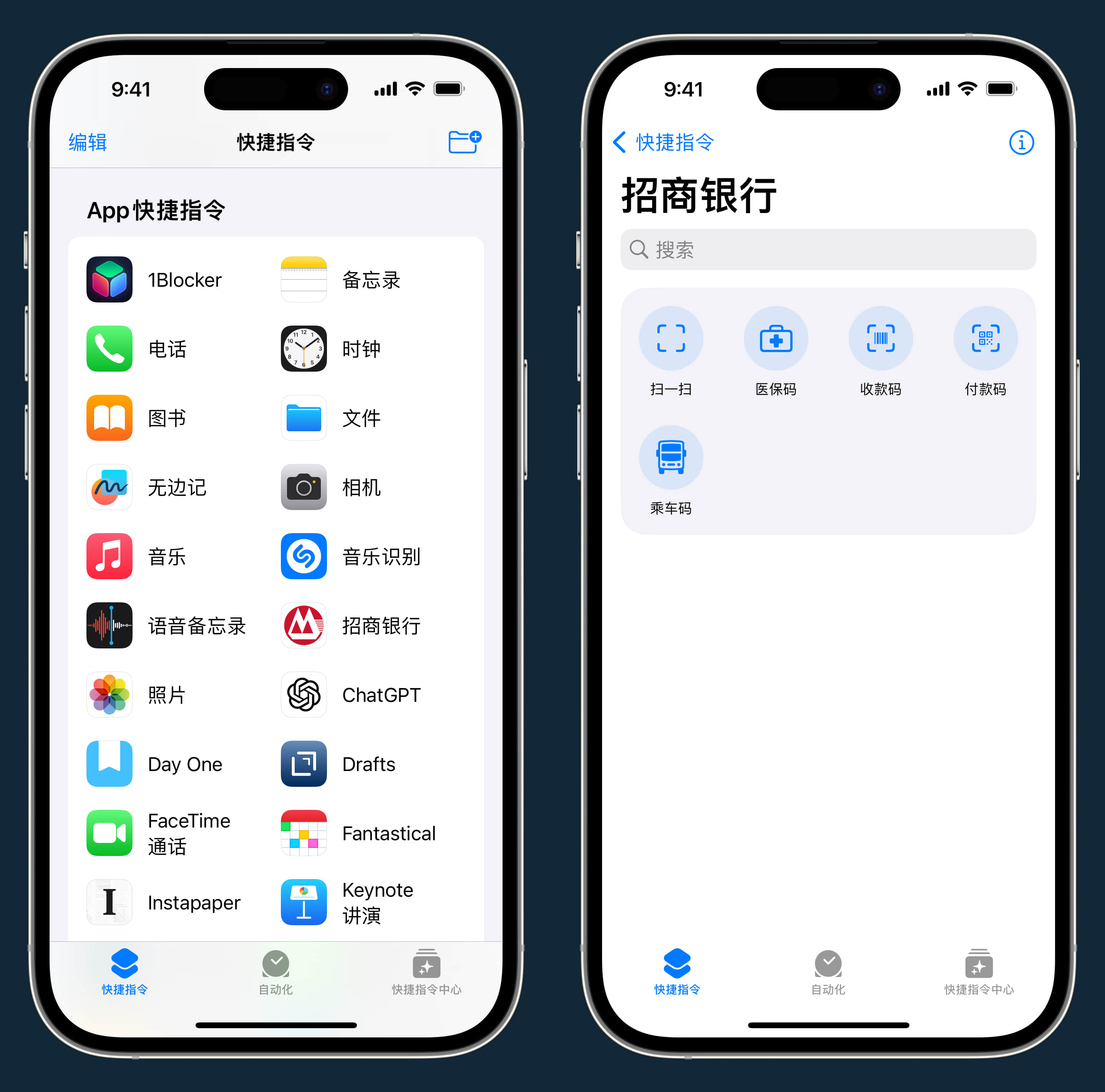
你可以进到快捷指令 app 中,滑到最底部,就可以看到所有支持“App 快捷指令”的应用。
Excel 打开乱码 CSV 的正确方式
作者:沨沄极客
摘要:一个非常常见的 Excel 问题,许多人都有着自己的解决方法,但就是不用 Excel 自带的。
在我们日常生活中,经常会遇到一类常见的表格文件:CSV 文件。CSV 的全称很容易理解:Comma-Separated Values (逗号分隔值)文件,这类文件由于其简单的结构被广泛应用。
不过,中文 CSV 常常会有字符编码问题,导致有时候在使用 Excel 打开 CSV 时,会遇到乱码、无法正常解析的问题。
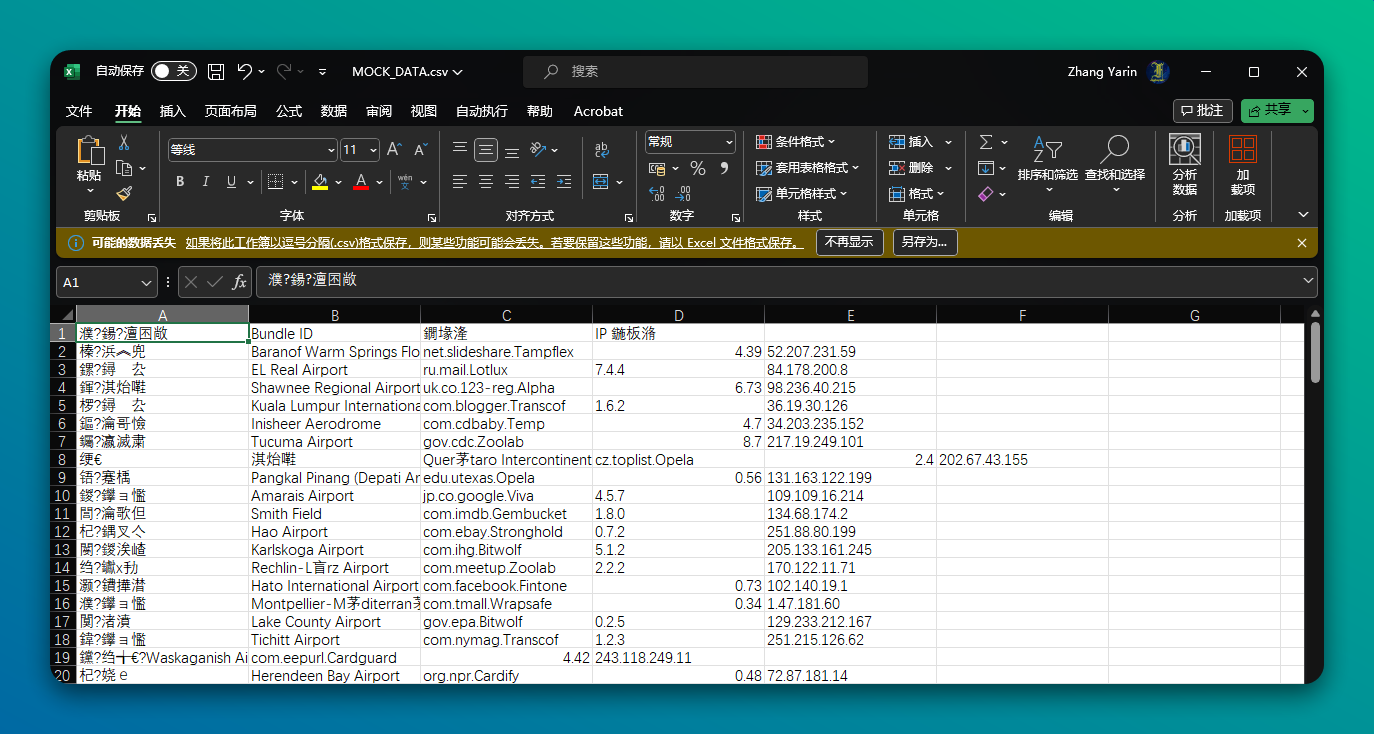
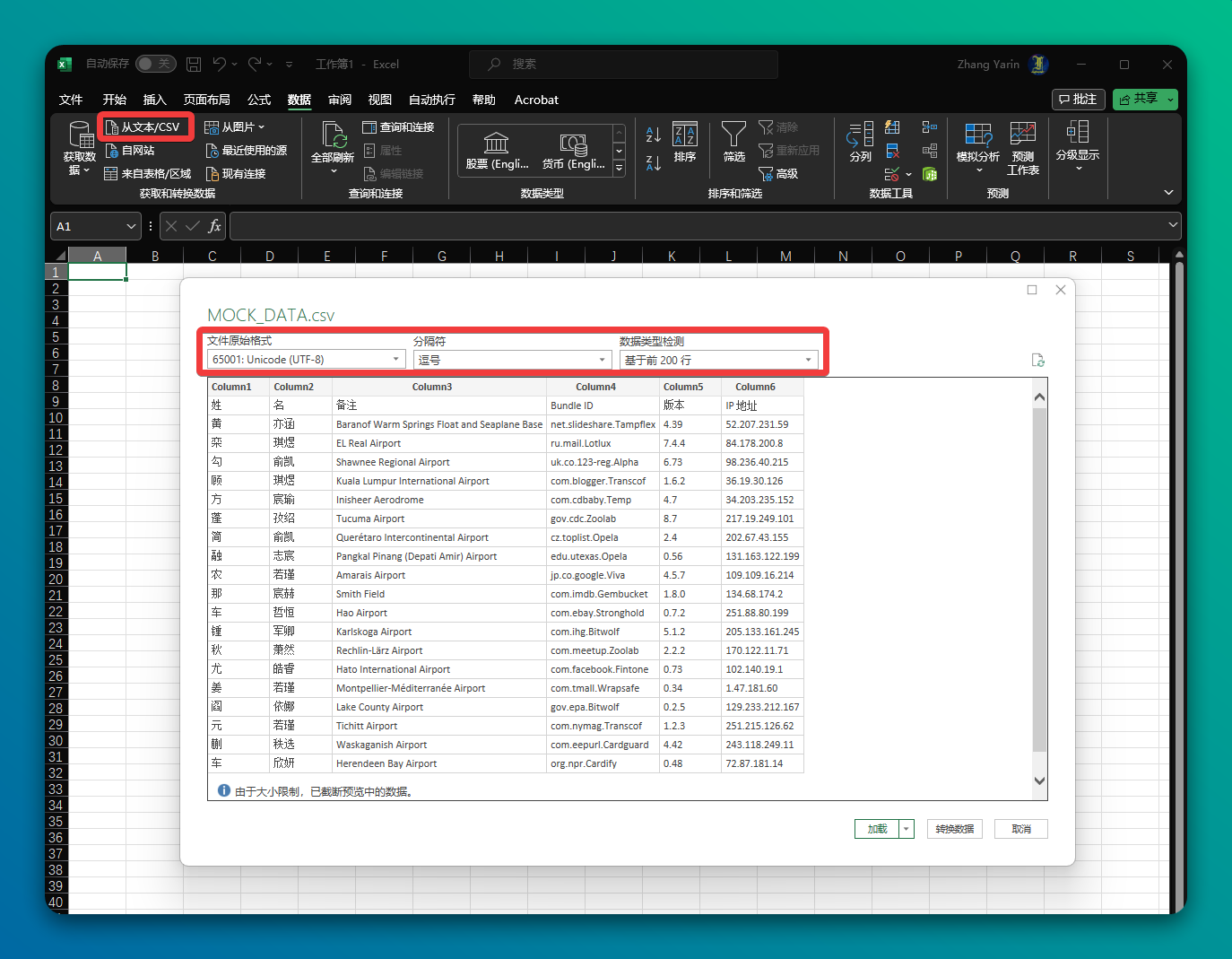
正确的 CSV 打开步骤如下:
- 打开一个空白的 Excel 文件,而不是直接打开 CSV。
- 导入 CSV 文件:
- 在Excel的顶部菜单栏中,点击“数据”选项。
- 选择“从文本/CSV”。
- 这将打开一个文件选择对话框,从中选择希望导入的 CSV 文件。
- 选择正确的编码
- 此时 Excel 会显示一个预览窗口,你可能会看到自动识别后的正确内容,也可能依然是乱码。
- 在“文件原始编码”中尝试选择不同的编码,直到预览窗口中的内容显示正确为止。(常用的中文编码是“UTF-8”、“GB2312”或“Big5”)
- 确定分隔符
- CSV 通常默认使用“逗号”分隔符。如果 CSV 文件使用了其他字符作为分隔符,例如分号或制表符,也应当注意调整。
- 加载数据
- 一旦您确定了正确的编码和分隔符,点击“加载”按钮。这会把数据导入到 Excel 工作表中。
我本以为这是一个非常基础的知识,但我发现还是有很多人不知道。很有意思的是,面对这个问题,我看到不同的人有不同的解决方法。比如把 CSV 放进 WPS、云文档、甚至是钉钉中打开,这样往往可以被自动识别出文件编码,从而免去了导入这一步操作。
Excel 实现“累计求和”的 4 种方法
作者:沨沄极客
摘要:在数据分析过程中,累计求和是一种常见的需求。在 Excel 中,你可以使用多种方法来实现这一功能。
在 Excel 中需要用到累计求和的情况,一般出现在按月、按日统计中,比如计算累计数量、累计销量等。
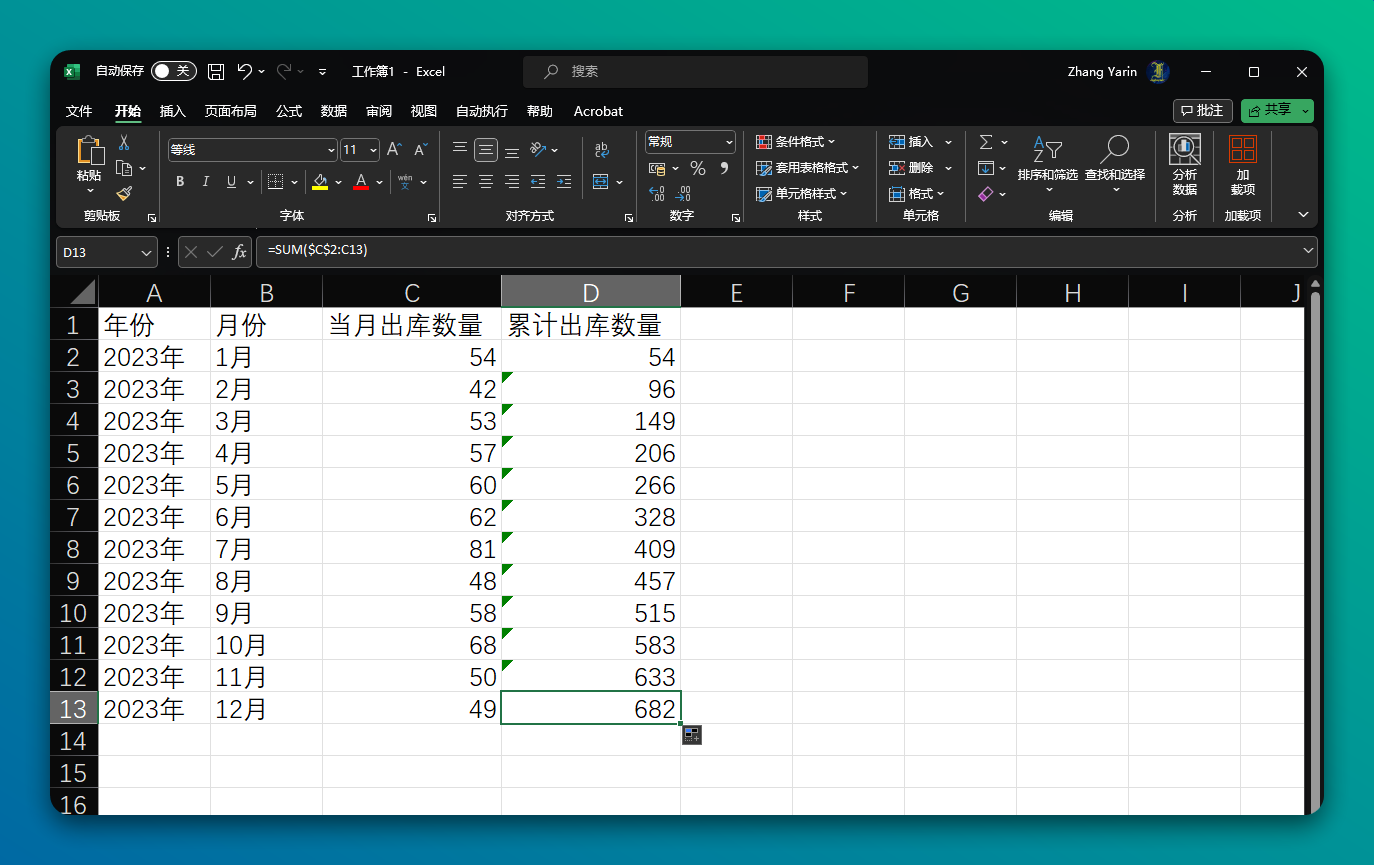
以上面这张图为例,C 列是每个月单月的数量,D 列是从 1 月开始计算的累计求和数量。
使用公式累加
这种方法比较直观,即上期累计数量 + 当期单月数量相加,即可得到档期累计数量。
- 在需要开始累计的第一个单元格(例如 D2)中,输入
=C2。 - 在下一个单元格(例如 D3)中,输入
=D2+C3。 - 将 D3 单元格中的公式向下拖动。
使用 Excel 的 SUM 函数
这种方法是始终累加“从第一行开始到当期”的数据。
- 在 D2 单元格中输入
=SUM($C$2:C2)。 - 将 D2 单元格中的公式拖动到 D13。最后一行的公式即为
=SUM($C$2:C13)。
这里,$A$1:A1 的格式意味着始终从 A1 开始,但结束范围会随着您拖动的行数而改变。
考虑按周期累加的情况
实际情况可能会更复杂一些,比如按周期累加的情况,比如每当跨年分开计算,那就需要再添加一些逻辑。
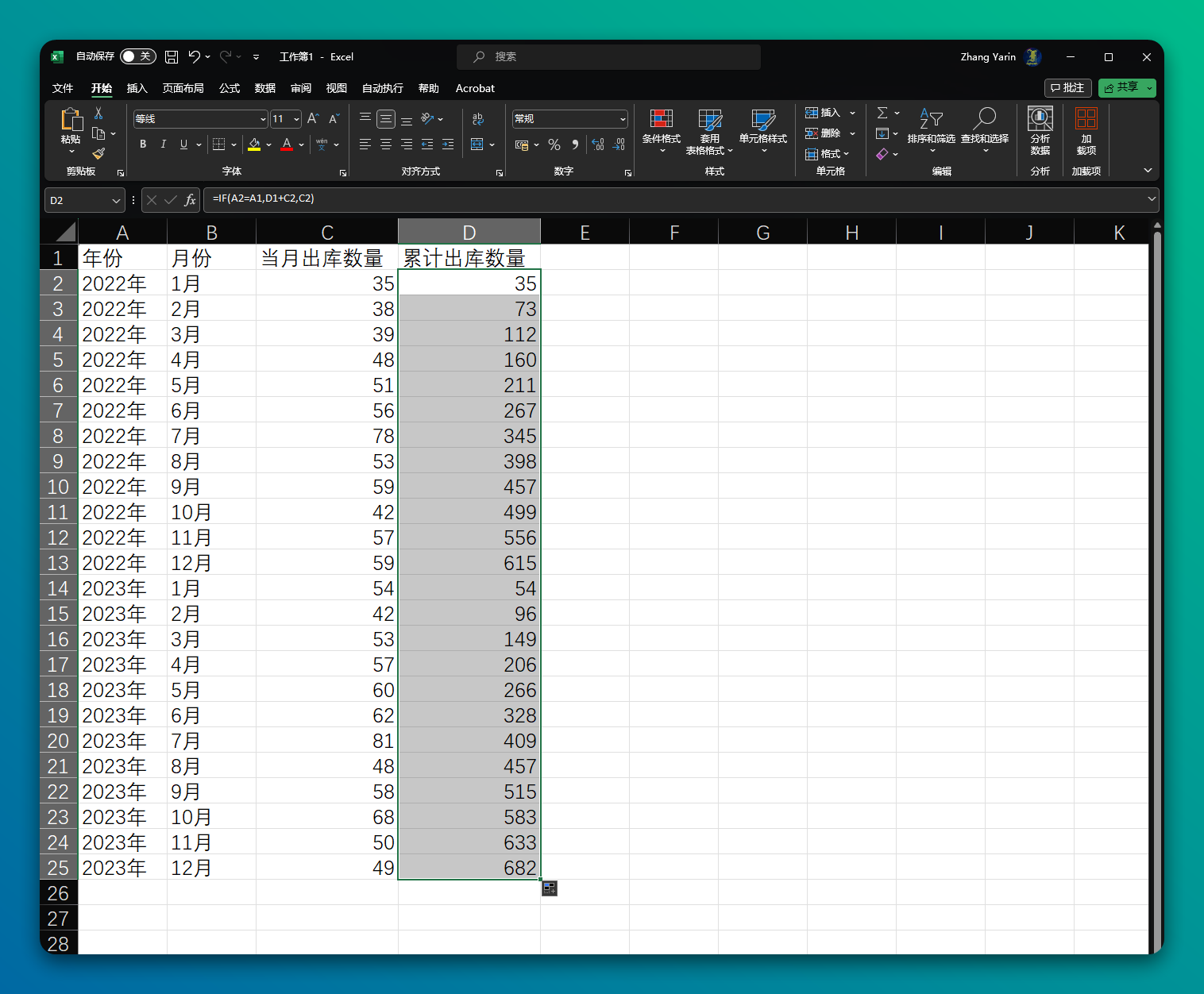
可以在 D2 单元格中写一个公式来实现这个逻辑:“先判断年份字段后,再进行累加,否则就从头开始计算”。
=IF(A2=A1,D1+C2,C2)
这个公式也适用于按季度、按月份累计求和的情况。
不连续的累加求和
现在情况更复杂一些,除了年月数据,还多了一列“仓库”信息,比如“仓库A”和“仓库B”需要分开累加求和。
但是上面的公式只能解决连续的数据,不支持筛选过的数据。
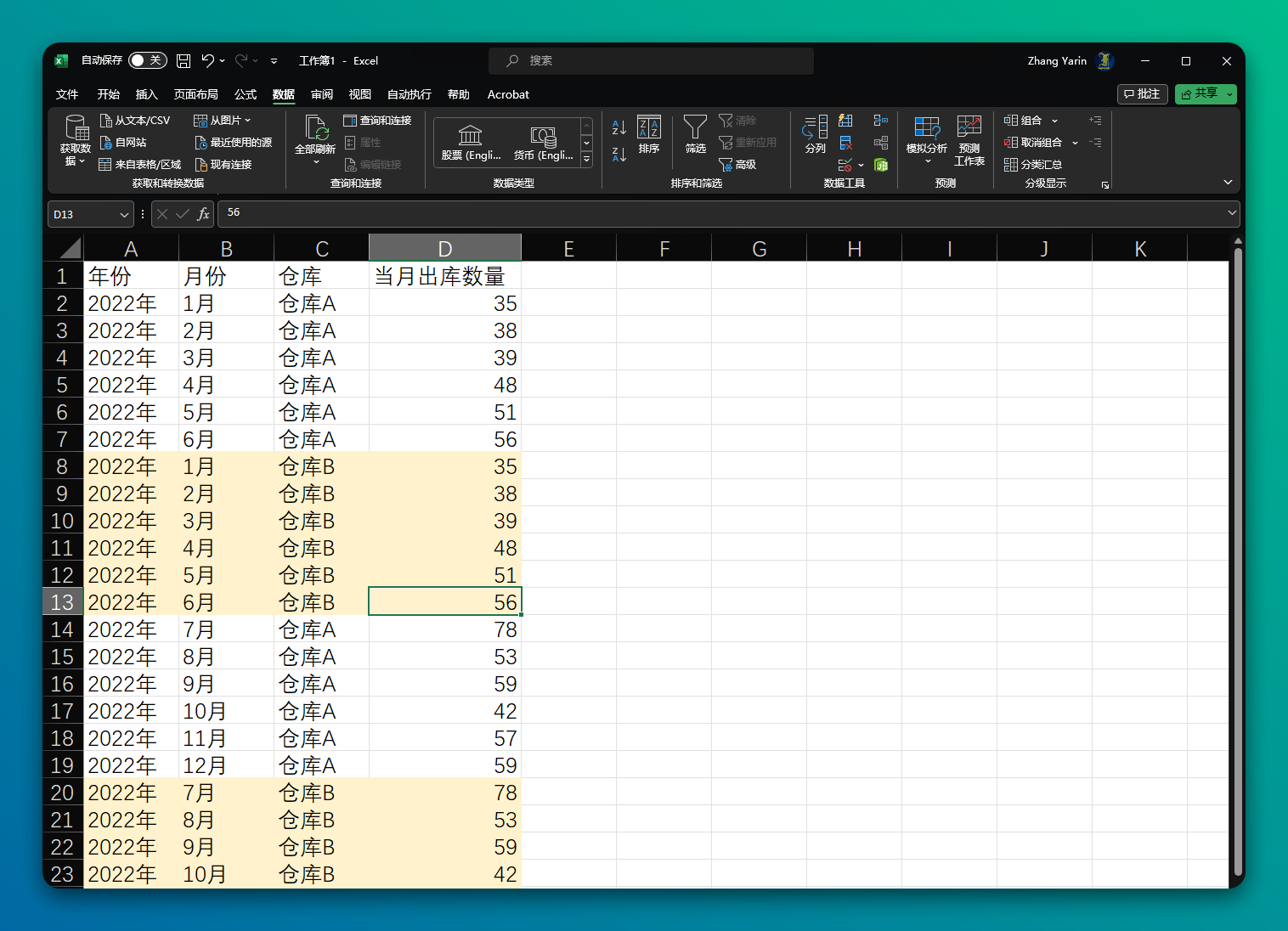
这种情况,就需要改用 SUBTOTAL 函数了。SUBTOTAL 函数的一个特点是,它会自动忽略被筛选掉的行。
累计求和操作,需要使用 SUBTOTAL 函数的 9 代码,这个代码对应求和操作。
=IF(A2=A1,E1+SUBTOTAL(9,D2),SUBTOTAL(9,D2))
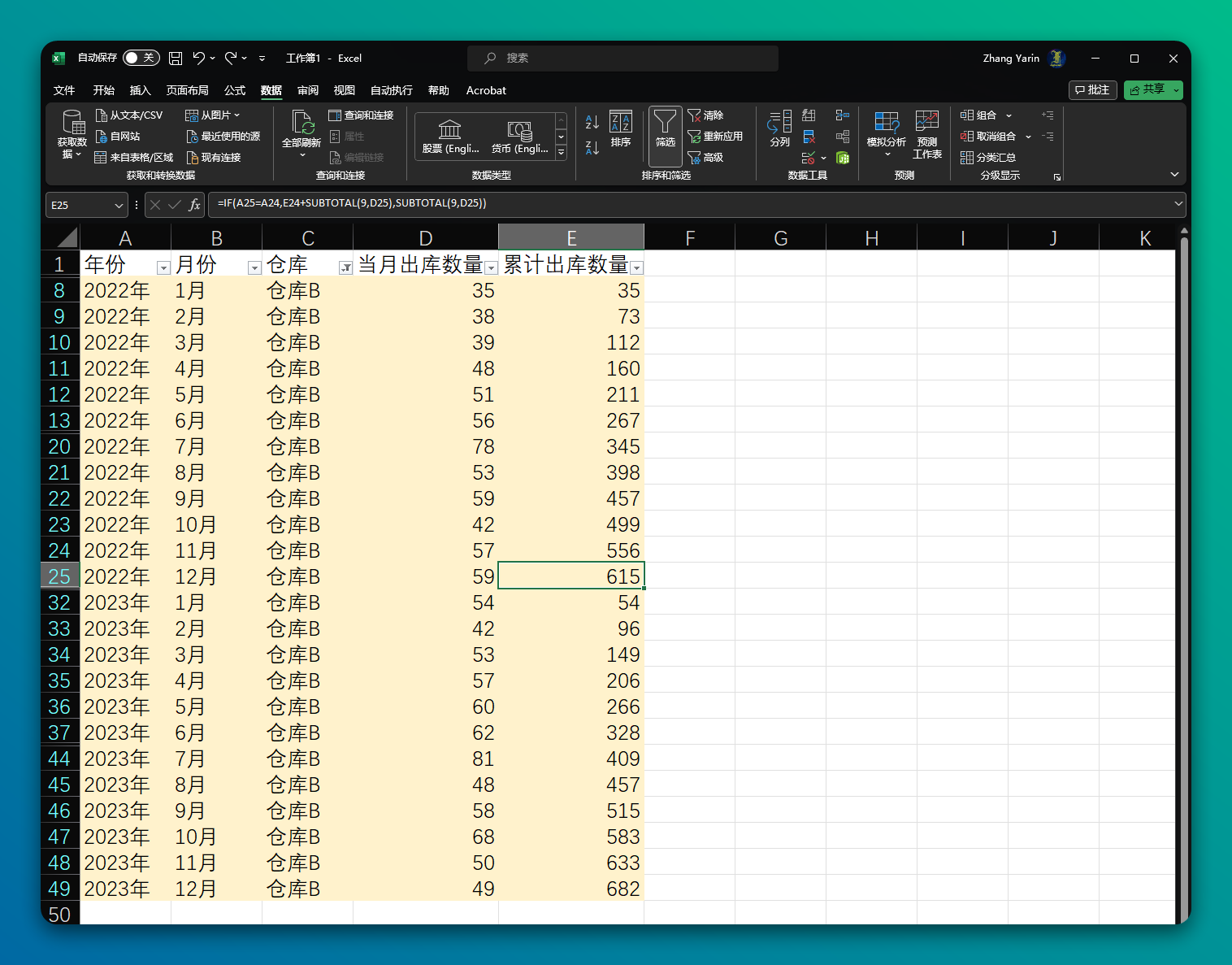
上面这些方法都可以实现累计求和操作。对于大多数任务,使用公式或 SUM 函数应该足够了。
Safari 阅读模式调教(一):修正抓取错误的标题
作者:Minja
摘要:阅读模式难免抓错内容,此时可手动修复。同时,也可借此入门网页元素检查器。
UNTAG 的在线阅读系列文章有幸获得读者的长期支持,不过,虽说不得不打上在线的旗号,专栏中多数作者的态度,却倾向于离线阅读,即先将待研读的资料存至本地,再细细咀嚼,各种原因,可见《一种将线上内容精简格式后保存到本地的方法》《剪藏网页到本地的自动化思路(以 Keyboard Maestro 为例)》等文章。
具体到技术层面,各人固有区别,不过主要的路径之一仍是 Safari 阅读模式,盖其可将大多数网页转换为清爽的版面,以便剪藏网页的主要内容,而不掺入过多无关元素。*可是,实际操作中难免发现种种不合意之处:Safari 继承了苹果公司一贯的仁慈独裁风格,有啥吃啥,抓到什么就是什么,即便抓取标题错误或者抓到广告,也不允许你修改,而遇上国内某些不规范的页面,情况就更糟糕。†
好在所谓的 Safari 阅读模式,不过是 Safari 浏览器从原始网页中提取后重组的页面,本质上和普通网页无异,同样由 HTML 代码组成,只需学一点最基础的编辑技巧既能修剪出合乎心意的页面。未解除过 HTML 的读者也不必担心,本系列文章基本可以依样画葫芦,不用涉足过深;要说起来,HTML 也可以简单视作更复杂的 Markdown‡,是故诚心想涉猎,也非难事。
本篇解决一个最常见的阅读模式瑕疵:标题抓取错误,其实这是网页自身不规范导致的问题,而非 Safari 之过。我经常发现,阅读模式中的网页标题成了网站名称,或者在原文标题后面加上冗长无比的网站介绍,打印后硬生生撑满了整整一页,非常碍眼。原因在于,不少网站错把网站名填入 HTML 中的标题位置中,或者有意无意往掺入网站介绍乃至 SEO(搜索引擎优化)关键词。解决方法很简单:
- 在阅读模式中选中标题,在右键上下文菜单中选择“检查元素”(Inspect Element),即可看到标题部分对应的 HTML 代码;
- 双击盖代码,一般可以使之转为可编辑状态;
- 将抓取错误的标题手动改回正常标题,或者删去其中的无用部分。
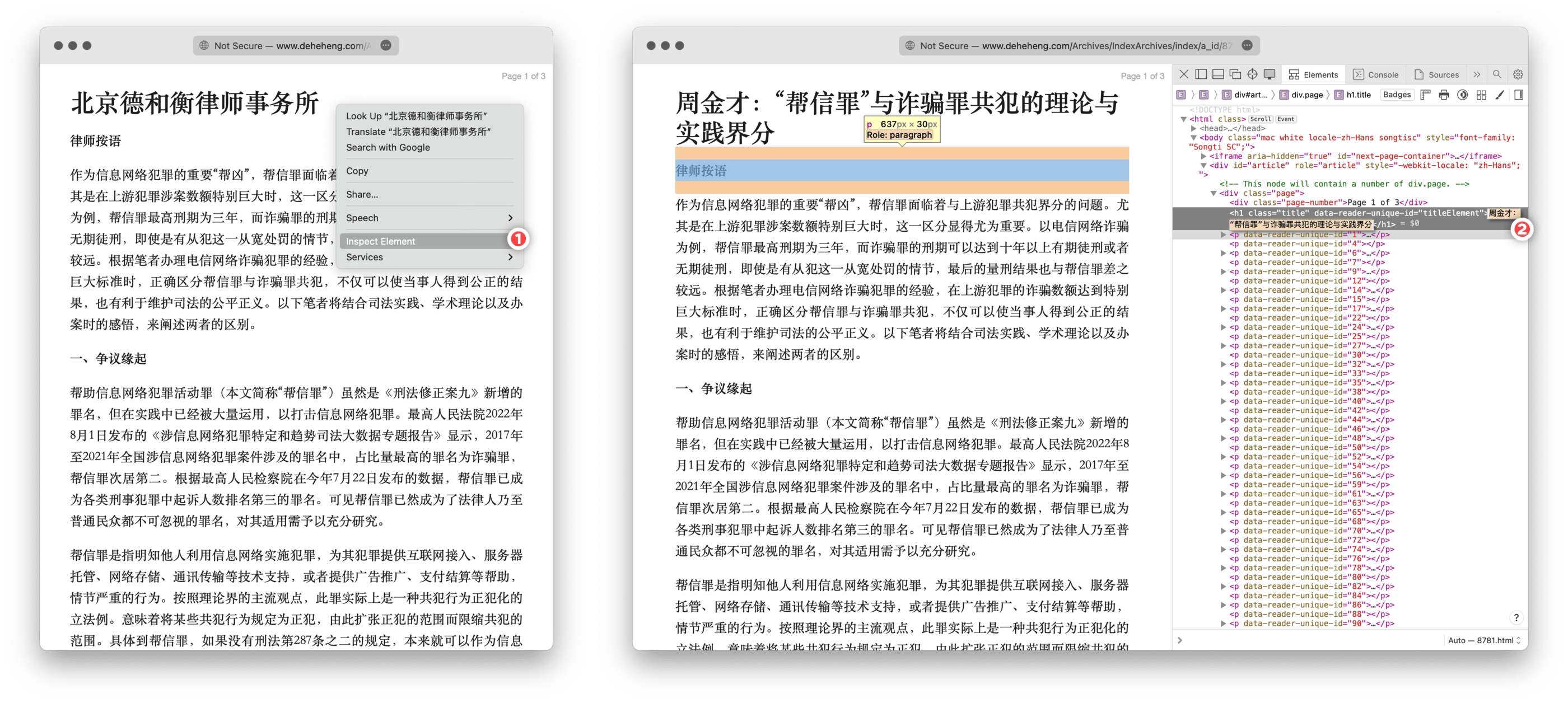
修改会即时生效,阅读模式中的标题会马上改变,接着就能剪藏或打印标题正确的版本。我常常读到一些不错的政法类文章,不过——或许带有一些偏见——很多文章功夫好的人,做网站却不见得专业,本身排版随意,打开阅读模式后更是原形毕露,这时候就要手动修剪一下再保存。
上述操作不会改变网页本身,刷新或重新打开页面后,网页会恢复原装,若不慎操作失误而不知如何是好,刷新重进页面、再度开启阅读模式就好。
*我并非唯阅读模式是尚,盖如果网页本身排版就很精致,则最好将其保留,不浪费作者和编辑的心血;但遇上杂乱的页面,阅读模式仍是万金油。进一步的讨论,可见《剪藏网页到本地的轻量化思路》一文。
†微信公众号已经彻底没救了,那些小编在排版上的创造力简直能让毕加索蒙羞,恕我没有能力解决。其他页面还可以试一试。
‡事实上,Markdown 是简化后的 HTML,两者在许多地方逻辑相似,例如 Markdown 中的 **文字** 表示加粗文字,而 HTML 的写法之一则是 <strong>文字</strong>,同样是用前后的一组标记符号把文本包裹起来,以实现各种样式和功能。
收纳零碎物件的伸缩管|URBAN TOOL
作者:Minja
摘要:从美式 EDC 品牌到全球顶级设计事务所,行家里手偷着用的收纳好物。
或许是身上的工业血统过于纯正,伸缩管鲜见于日常用品。以我所见,似乎只有 nendo 在为乐天设计口香糖包装时考虑过伸缩管方案,以避免糖果吃掉一部分后瓶子会发出哐当声,可惜最终未投产,不然我一定把所有口味都买了——就为了买椟还珠。^1

伸缩管的尺寸可在一定范围内调整,比固定体积的小瓶子更通用。可惜这种粗旷的包装,在国内几乎只存在于机床刀头,淘宝上的通称也是“刀具包装盒”。不过在国外,其应用就广了,许多 EDC(Every Day Carry,每日携带)品牌都喜用伸缩包装盒,甚至几千上万的手工钢笔也不介意采用——不难理解,一种型号的绳索包装盒,就可以覆盖几乎所有常见长度的笔,何乐不为呢。事实上,伸缩盒也很通用,大号的可以当铅笔盒(已经有厂商这么干了),手指大小的迷你款则可以装零碎物件,比如耳塞、数据转接头、回形针等等。

在国内似乎很难单个购买,一般只能批发,尤其是定制的小尺寸,更不可能只买一个了。这倒是让我意外发现了伸缩管的社交功能:这类小工具一般人不知道,即便知道了也不太可能真的去批发几百个,于是我一口气买了三百个,每个只花几毛钱,除了自己用,也随手送朋友。
^1: 日佐藤大:《佐藤大:没有废弃方案》,文化发展出版社2017年版,p35。
用 Shortcuts 将 PDF 打印成 Booklet(小册子)
作者:Minja
摘要:不管你遇到的打印机多么老古董,都有办法打出 Booklet,方便将资料随身携带。
传统印象中,打印文件要不单面要不双面,很难想到还有什么其他花样。不过在实际中,其实还有不少复杂的打印模式,例如把 3x3 的大型海报自动分开打印在9张A4纸上,或者打印那种A5打开、中间用订书钉装订的 Booklet(小册子),等等。我自从工作之后,因为不再混迹于社团,自然几乎没打印过海报,但小册子却时不时需要印刷,例如一些常用的操作手册或者办事指南,还有不太厚的法律法规,我都习惯打印出来,随身携带,坐公交车的时候拿出来翻一翻,比看手机要健康许多——身心两方面。

但并非所有打印机都可以印刷小册子。事实上,能不能打印,完全依赖于你所使用的打印机,那些张口就说行的人,多少是站着说话不腰疼,而你在文印店看到的许多专业级打印机——就是那种和电冰箱一样大的——往往就不能印小册子。小半年前,单位老大换了一台性能极强但是软件稀烂的 RICOH 打印机,我也就告别了小册子模式,只能自力更生。
结果是我自己做了一个 Shortcuts,用于将正常的 PDF 排成小册子的顺序。这么说有点抽象,诸位最好找一本订书钉装订的册子——回忆一下《读者》或者社区里发放的营养指南——如果拆掉钉子,将纸张平铺,不难发现页面是以某种规律排列的,当然,背后枯燥的数学问题我已经解决了,您可以用文章开头的 Shortcuts 动作转换得到新 PDF。
不过,生成的 PDF 不能直接打印,还需要调整一下打印机的参数(这些常用参数倒是再古董的打印机也能具备),以便把 PDF 中的每两面打印到一面纸上:
- 打开双面模式(Double-sided),沿着短边(Short Edge);
- 每面纸打印两面 PDF 页面;
- 布局方向(Layout Direction)选择第一个,即“Z”字形。
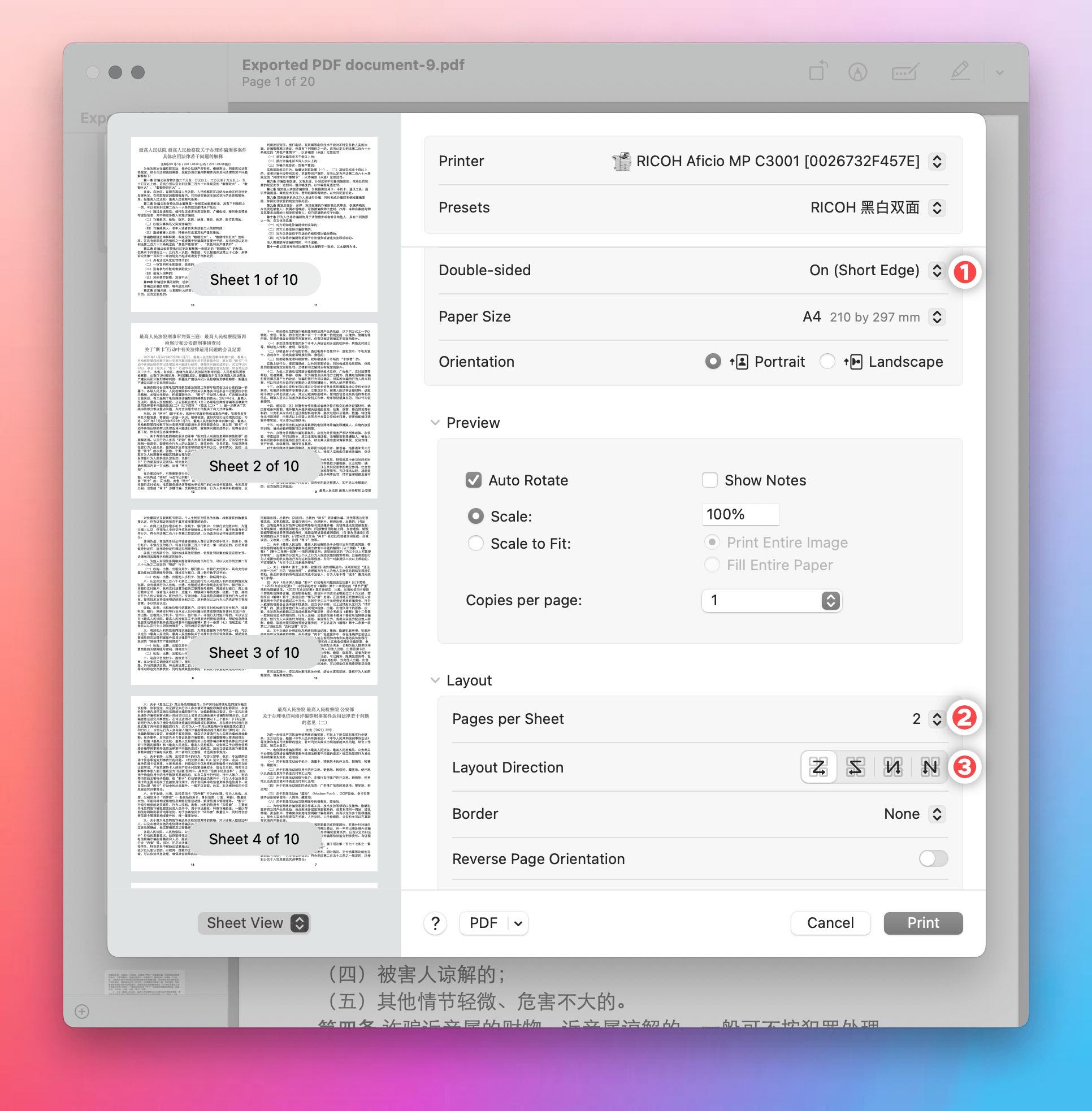
这样打印后,再把打出来的纸张叠在一起,统一对折一次,确认顺序无误后装订起来,就能得到A5尺寸的小册子,可以随身携带。一般的订书机可能较短,不能横跨小册子的宽度把钉子钉上,好在册子一般不会太厚,对折或卷一卷也能塞进多数订书机——但不能是无印良品那种小可爱——的订书钉导槽(bottom track)下方。
显然,这一通折腾的主要目的就是获得小尺寸印刷品,随便找一个单肩包都能塞进去,秋冬时节还可以揣在大衣兜里。至于其他特殊的打印模式,如果您所用的打印机不巧不具备,也不妨思考一下如何自己解决。