

书目可以采取多种合适,从 Excel、Airtable 到纯文本,请自己斟酌。本人习惯使用纯文本存储数据,且已使用 Taskpaper——一款纯文本任务管理工具,本质就是清单、大纲、列表——多年,故取此格式。我不能摘星星,但我能把它们存入银行。我在一张小纸条上写上我的星星的数目,然后把它锁进抽屉里。——圣埃克苏佩里
钟情阅读之士,爱将阅读比作随身携带的避难所(语出毛姆);而顺着类似的空间隐喻,我们将原本遮风避雨即可的避难所越建越大,以至于竟成了巍峨耸立的城堡。在好读书之人中间,滑向收藏家的不在少数,不仅在电脑上搭建宏伟的书库,还强度关山、设法同步到移动设备上——“可以不用,不能没有”,是这一群体最响亮的口号。
但全盘同步书库一事,既成本太大,也难见其必要;苟寄希望于移动设备与桌面齐平,惟成为永不抵岸的荷兰人,耽误了阅读本身。相比变成背负书库的信息蜗牛,制作一份随身携带的书目更为轻松,同时也足够用于检索。
随身图书馆的幻觉
随身图书馆,是当下各个书城平台极力营造的形象,然而读者对其中书籍多仅有阅览权限,而并不真正拥有原始文件,故与其说是图书馆,不如叫它们为借阅室比较好。在现有著作权制度下,真正意义上的图书馆,只能由读者自行维护。
一旦揭掉“随身图书馆”“移动图书馆”等词语的营销意义,它们马上就会变成一个空壳。盖图书馆断非书堆,不是找一个文件夹、往里面塞满一堆书籍就大功告成。是否备有作者、出版社、发表年份等信息?能不能跟随阅读进度,给书籍打上自定义的标签?可不可以快速组织一个书单,牵出一串相关书籍?这些都是图书馆的本职功能,而移动端目前不能,在相当长一段时间里估计力有未逮。
我曾将专业书悉数扫描为 PDF 文档,放入 DEVONthink 中,期盼着在 DEVONthink To Go 上随时翻阅,以减轻携带纸质书之苦,不幸因为同步不稳而作罢——但这只是故事的开始。尽管没有同步整个书库,DEVONthink 倒是显示了待同步书籍的占位符,而原始文件的大小、评级和标签等元数据也一应俱全——DEVONthink 无心插柳,制作了一份书籍的索引目录,就像图书馆的馆藏信息。
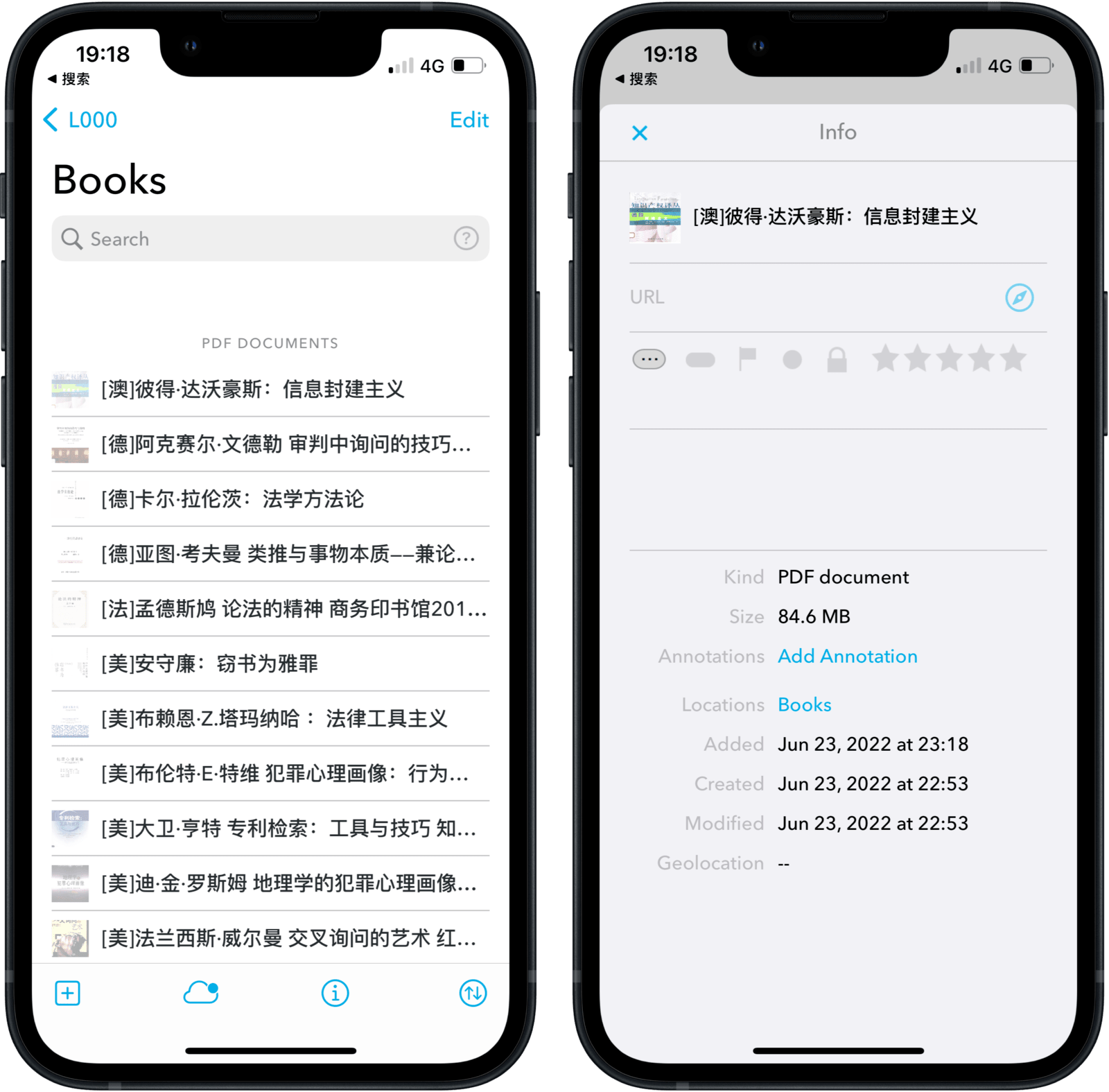
同样是半杯水,也有两种观察视角。一个无法点击的文件图标,在别人眼中相当于一个系统错误;但我看见这些“空文件”身上的海量信息,并为之激动难寐、转辗反侧。不过,DEVONthink 毕竟不善于检索中文,手机端的交互也敷衍了事,浏览书目还是需要另一个软件——就在写下待办事项并为之苦思之际,我瞥见了任务管理软件的界面。
后退一步,水落石出。
用 Calibre 编制书目
制作书目,首先需要一个书籍信息管理工具,最大众的选择就是 Calibre,而洋气一些的人也可能使用 DEVONthink;如果屈居于在线书城的话,则恕我无能为力。本文以免费图书管理软件 Calibre 为例,以求通用。
古谚有云,目录有收藏家之目录,也有读书人之目录。而将 Calibre 的书籍信息导出为随手可查的书目,实际上即使尽了收藏家的职责,又做了读书人的工作。就前者而言,他的工作就是编排书籍本身,让查找图书更加方便;而读书人的功夫则贯穿阅读和编目的整个环节。自图书入库之时,阅读便随之开始,他必须了解图书所属的领域,知道作者的年代背景,最好还了解一些发行商和出版年份。读书人的目录,不仅服务于找到某本具体的书,更应引导接下来的书籍利用。功夫在于把书读厚读薄之间,而不只是把书排列整齐——这里的阅读是广义的,不只是为学术进行的阅读,也包括放松但不放纵的阅读,比如一个推理小说爱好者,也需要知道流派、手法、结构甚至诡计类型。就连漫画也值得认真对待,可以辅以书目,而非抓到什么资源就胡乱咽下去。
如此,Calibre 扮演的角色,便是阅读的过程记录;而书目,则是阅读轨迹的一个切面,虽然比起整个书库,其着实短小,却也能看出来路,指示去向。一定程度上,可以用对付 Excel 的思路来使用 Calibre,即切换到列表视图,然后像管理表单一样充实 Calibre 书库中的条目信息。打理书库本身并非本文重点,我更关心如何将书籍导出为易读的格式。
首先还是得从 Calibre 导出书籍信息。点击菜单栏项目“Create catalog”(如果你迷失于菜单栏之茫茫,请考虑使用快捷键之王),就可以看到一个类似自助餐吧台的界面,供你选择需要导出的信息。
- 在“Catalog options”页面下选择要导出的格式,鉴于后续要用自动化工具修整为 Taskpaper 格式,建议使用纯文本格式,比如 CSV;
- 转到“CSV/XML options”页面,选择要导出的书籍信息。
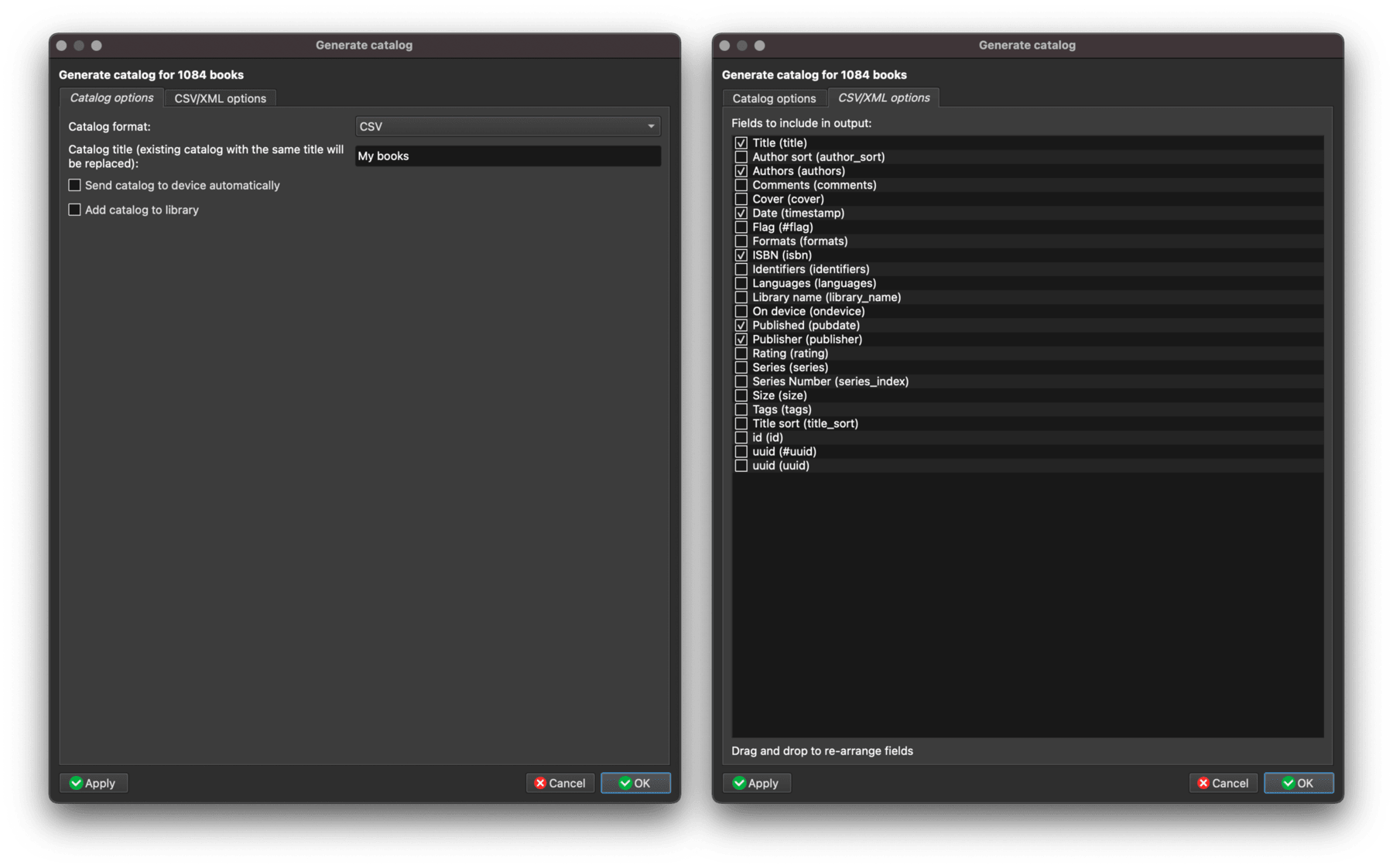
迨勾选完数据,就可以导出一份纯文本表格。
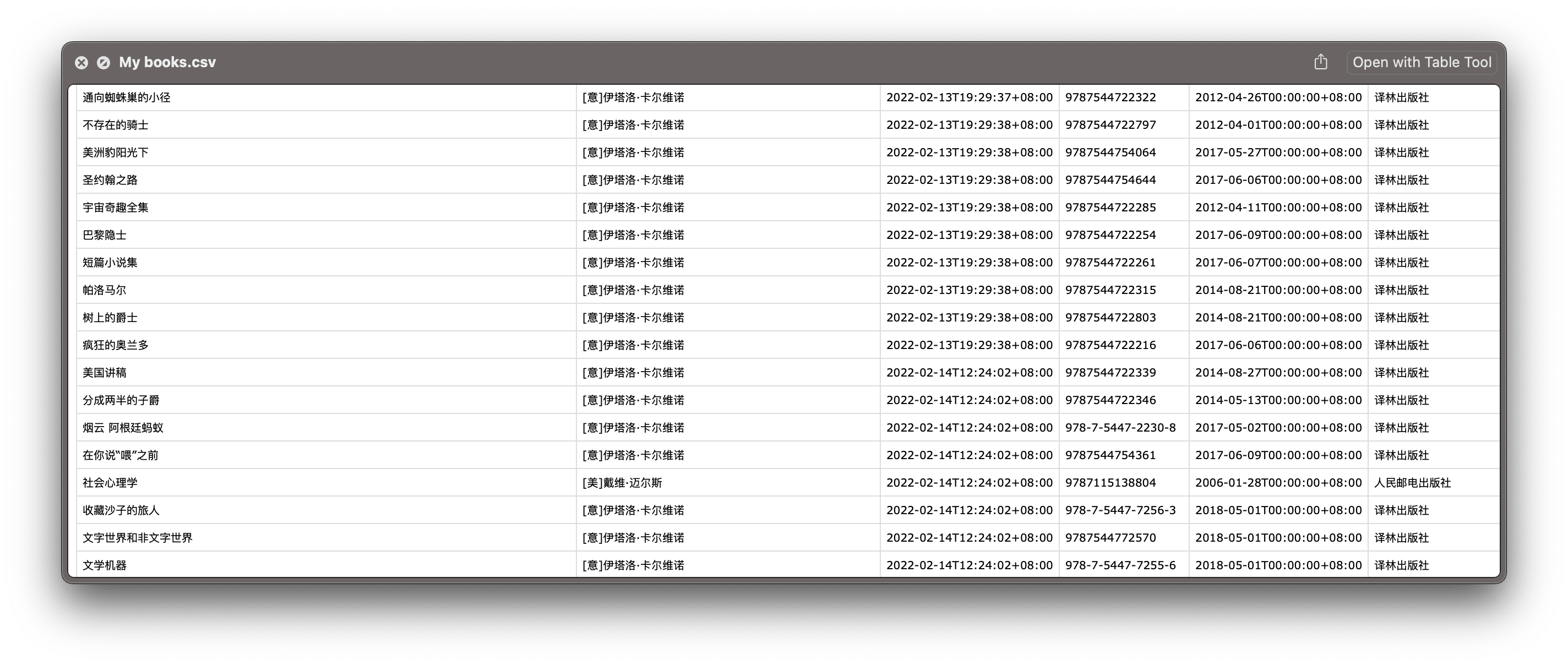
不过,目前的表格只是半成品,苟直接丢到手机上,好像是某种微缩纪念品,并不利于阅读。想象一下有人在微信上丢给你一份上千行的 Excel 表格,大概能感同身受。
用 Taskpaper 浏览书目
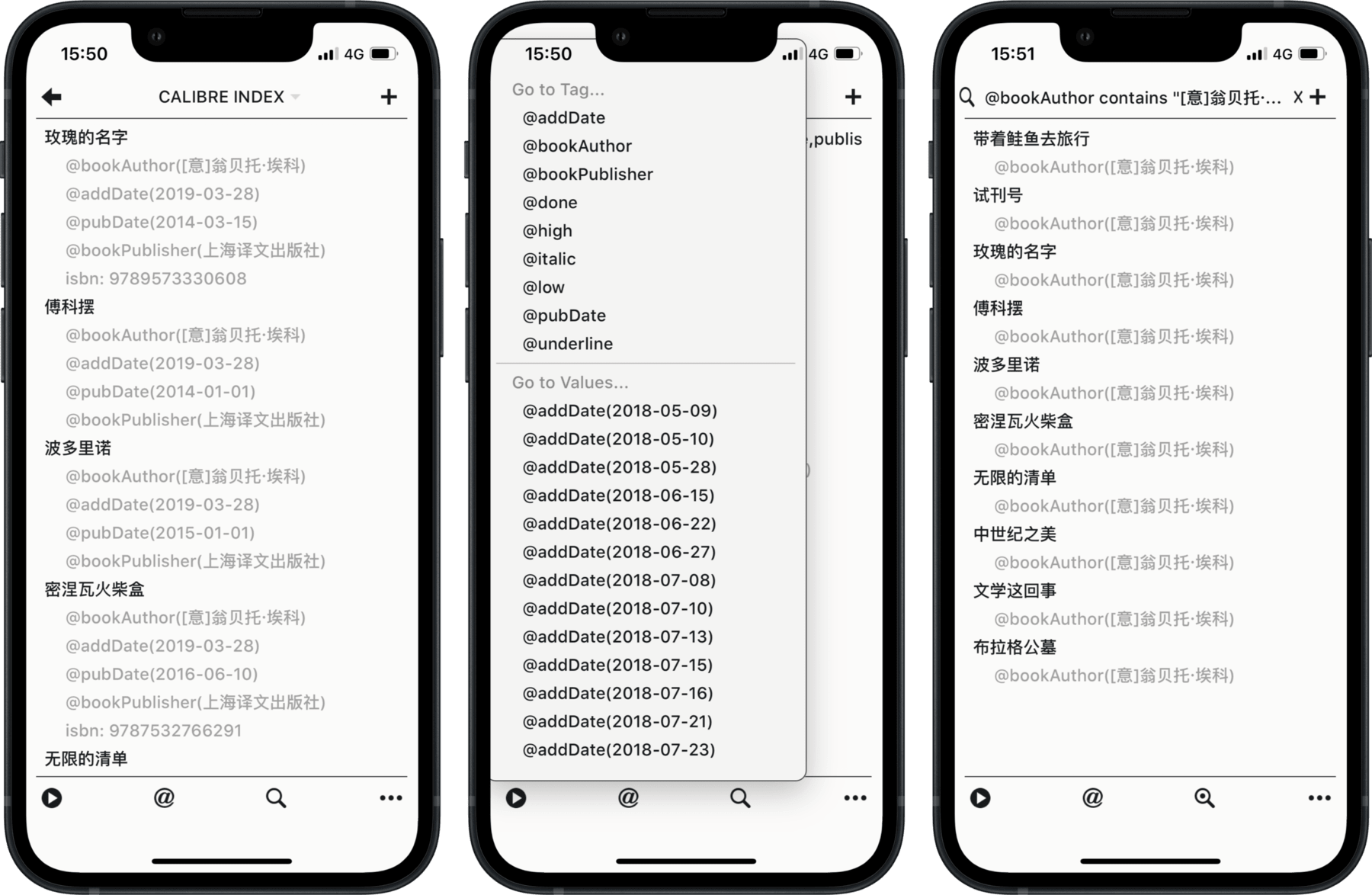
浏览书目,也需要恰当的工具。面对手机屏幕,表格的思维定势应当刨除,清单才是更适合竖长屏幕的格式;而基础的清单又不足以容纳丰富的书籍信息,理想的工具应当是带层级的清单或大纲——任务管理工具就此进入视野。而任务管理工具多矣,苟选择格式封闭者,则属于方才逃离书城的斯库拉巨岩,却又跳进另一个封闭系统的卡律布狄斯漩涡。几个条件纵横交叉,便只剩 Taskpaper 和 todo.txt 这类纯文本任务管理工具。我手上都是 Apple 的设备,故选择了有原生应用的前者;而 Windows 用户,可以考虑后者。
Taskpaper 的语法格式和表格同构,此系转换的基础。以下是 Taskpaper 中的任务清单,每项任务后都附有数个属性及其值;在任务管理中,这些“键-值”对可以理解为标签组。下一个代码块含有与任务清单相同的信息,但是采用了表单形式。至于如何获得 Taskpaper 格式的书目,既可以用 Excel 或 Numbers 手动制作,也可以写个脚本批量转换。不过各人所需的书籍元数据大相径庭,文末提供的脚本只能起到参考作用。
- task_1 @k1(v) @k2(v) @k3(v)
- task_2 @k1(v) @k2(v) @k3(v)
| | k1 | k2 | k3 |
| ------ | -- | -- | -- |
| task_1 | v | v | v |
| task_2 | v | v | v |
例如,《玫瑰的名字》的作者是意大利人翁贝托·埃科,在 Taskpaper 中就可以采用标签组的语法,写成 @author([意]翁贝托·埃科)。这不仅仅是为了整齐划一,更要发挥标签的作用——过滤。在手机等设备上,输入文字并不方便,但只要实现备妥了诸项标签,则过滤书籍只需要点击几次屏幕。在 Taskpaper 中,点击标签 @author([美]尼尔•斯蒂芬森),则所有埃科的作品,都将汇集一处——这一特性当然不限于手机,即便在电脑上,我也乐意使用书目,求其轻便,而非每次都直接浏览书库。
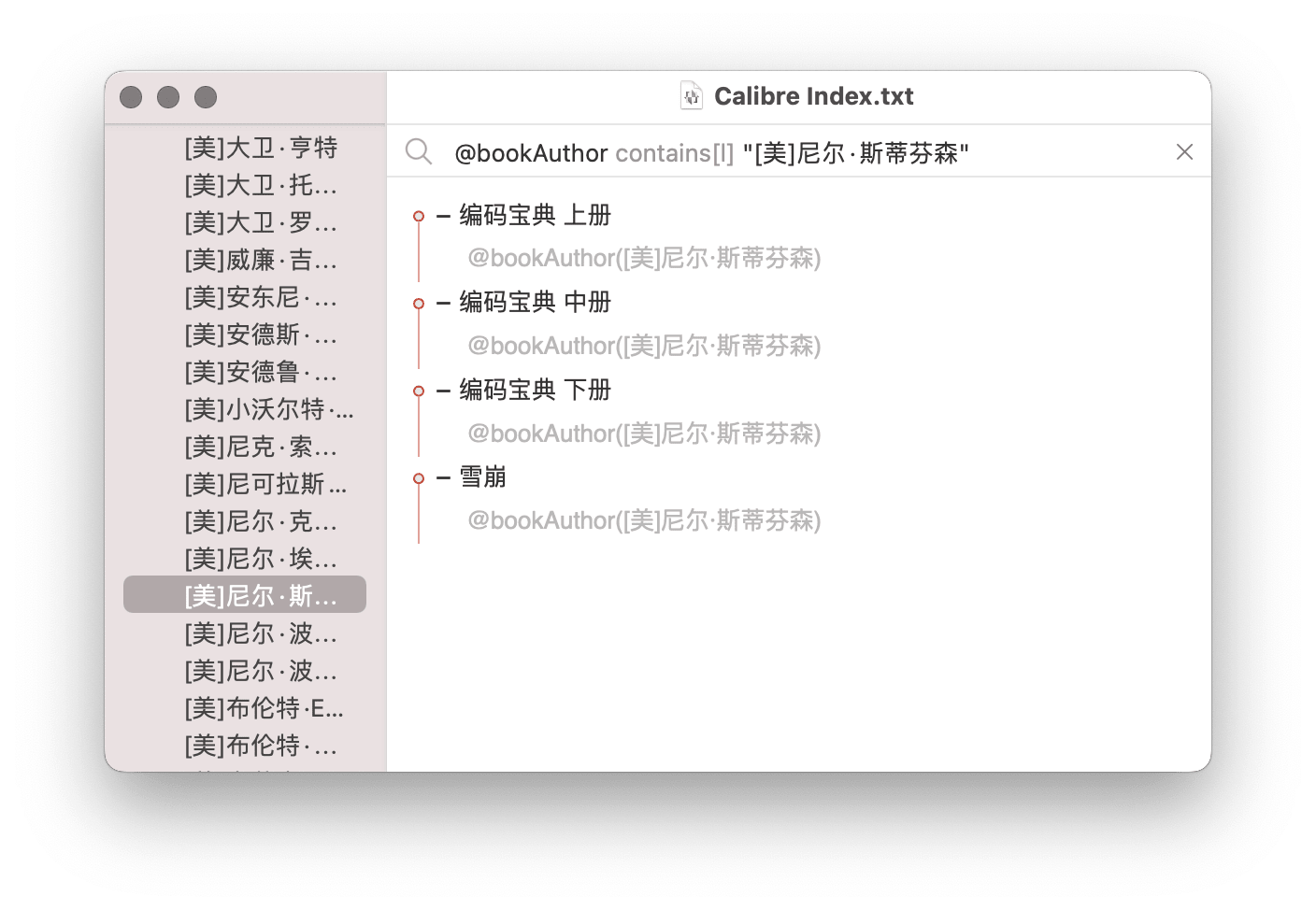
过滤时,标签提供了无限多的维度,正如文件管理器中的标签能够取代文件夹,书目中的标签也可以代替书单,并较之更为灵活。
组合或者创建一些关键字,就可以指出某个研究或自娱自乐——有时候两者兼具——的方向。例如新兴的区块链法律或个人信息犯罪,没什么靠谱的资料,都需要读者自己探索书单;通过几个标签的组合,就可以创建一系列智能书单,指导交叉领域的究学路径。再如复杂系统,对此话题哲学家有话要说,物理学家不吐不快,数学家更是当作老本行津津乐道,而科幻小说和推理小说作家也能提供充满启发的视角——其实约翰·霍兰严肃的科学著作,就以莱姆的科幻小说做引子。你可以将某个暑期项目的名字当作标签,轻松整理出一份汇集硬科学、哲学、科幻小说甚至亚主流漫画的书单。
至于为何不直接使用文件管理器,理由也非常简单:在书房里不应该吃吃喝喝,同理,最好也不要把书库和日常文件混杂成一团。例如把 Finder 作为书库,则其中的标签会贯穿整个文件管理器;如果你有志于给标签编码、分类,那么书籍上的标签轻轻松松就能毁掉文件管理器的标签体系。总之,管理书籍,务必使用专门的软件,如同即便身处陋室,也要隔出一角看书的空间。
结语
不过,在两个隔海相望的遥远领域中发现关联,并为止会心一笑,往往需要巨大的投入,这是一个残酷而又甜蜜的事实。编辑目录并非一蹴而就,而是要随着阅读不断深入,或者说没有阅读,尤其是通读,那就没有靠谱的目录。
实际上,一旦做出读书人和藏书家的区分,创建书目也就没有听上去那样迂腐。在传统书籍管理软件中,我们总是遵循收藏家思维,一本书都不能落下;当手机成为义肢之后,顺理成章,也希望能够从随身的避难所里抽出任何一本书——不管是一个作者笔下的几百本小说,还是某位画家等身的集子。然而读书人却不求无限的书籍,利玛窦远渡重洋带着《圣经》,马尔克斯随身带着博尔赫斯的作品集。
盖读书并非囫囵吞枣,甚至需要刻意与原稿原件保持一定距离(这里的原件也包括电子文档)。出门在外,更重要的是检索馆藏条目,而非一头扎进书堆。讨论一个新课题,或者分析一个疑难案件,第一件事情不是马上钻进书堆,而是先从随身携带的书目中调出可能有用的条目,摸索可能的方向。如果按照前文流程来制作目录,其中项目都应来自亲手编制1,拿出来的文献多少有点把握,交谈的时候便能对答如流,而不是毫无底气、全靠数量诈别人——苟若太依赖书库,总是大手一挥,以为数据库够大就必然质量喜人,其结果往往比百度搜索的第一页好不了太多。
惟远离充其栋宇的书籍,它们方能化为漫天的星辰,连成指引航向的北斗。
以下为转换 Calibre 所导出数据之格式的示例脚本。#cat "/Users/Min/Downloads/My books.csv" \
# | sed -e "s/T..:..:..\+..:..//g" \
# | awk -F,\" '{ print $3 }' \
# | tr -d "\""
index="/Users/Min/Downloads/Calibre Index.txt"
cat "/Users/Min/Downloads/My books.csv" | while read line;do
bookName=$(echo "${line}" | awk -F,\" '{ print $1 }' | tr -d "\"")
bookAuthor=$(echo "${line}" | awk -F,\" '{ print $2 }' | sed -e "s/ & /,/g" | tr -d "\"")
addDate=$(echo "${line}" | sed -e "s/T..:..:..\+..:..//g" | awk -F,\" '{ print $3 }' | tr -d "\"")
pubDate=$(echo "${line}" | sed -e "s/T..:..:..\+..:..//g" | awk -F,\" '{ print $5 }' | tr -d "\"")
bookPublisher=$(echo "${line}" | awk -F,\" '{ print $6 }' | tr -d "\"")
bookISBN=$(echo "${line}" | awk -F,\" '{ print $4 }' | tr -d "\"")
echo "- $bookName" >> "$index"
echo " @bookAuthor($bookAuthor)" >> "$index"
echo " @addDate($addDate)" >> "$index"
echo " @pubDate($pubDate)" >> "$index"
if [[ $bookPublisher != "" ]];then
echo " @bookPublisher($bookPublisher)" >> "$index"
fi
if [[ $bookISBN != "" ]];then
echo " isbn: $bookISBN" >> "$index"
fi
done
- 我拒绝使用豆瓣书籍信息插件,坚持手动录入并校对数据。 ↩