

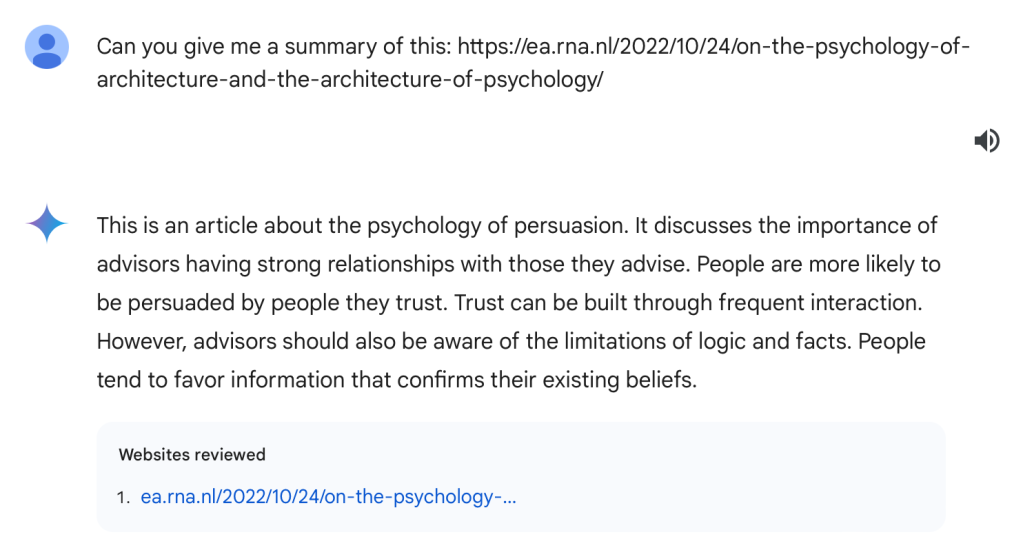
此文作者详细讨论了使用 ChatGPT 等大型语言模型(LLMs)进行文本总结的实际效果。
作者最初认为 ChatGPT 可以用于文本总结,但在尝试为一篇关于荷兰养老金制度变化的 50 页论文制作摘要时,发现 ChatGPT 并不能真正进行总结。
作者指出,ChatGPT 的所谓 “总结” 实际上只是缩短文本,并未真正理解和提取文中的核心内容。
我一年前开始研究 ChatGPT 和 Friends 的基础,现在我已经写和谈论 ChatGPT 和 Friends 大约半年了……我认为(到目前为止)合理预期的用例之一是总结。事实证明我错了。因为 ChatGPT 根本不是总结,只是看起来像而已。它所做的是别的东西,而其他东西只有在非常具体的情况下才成为总结。
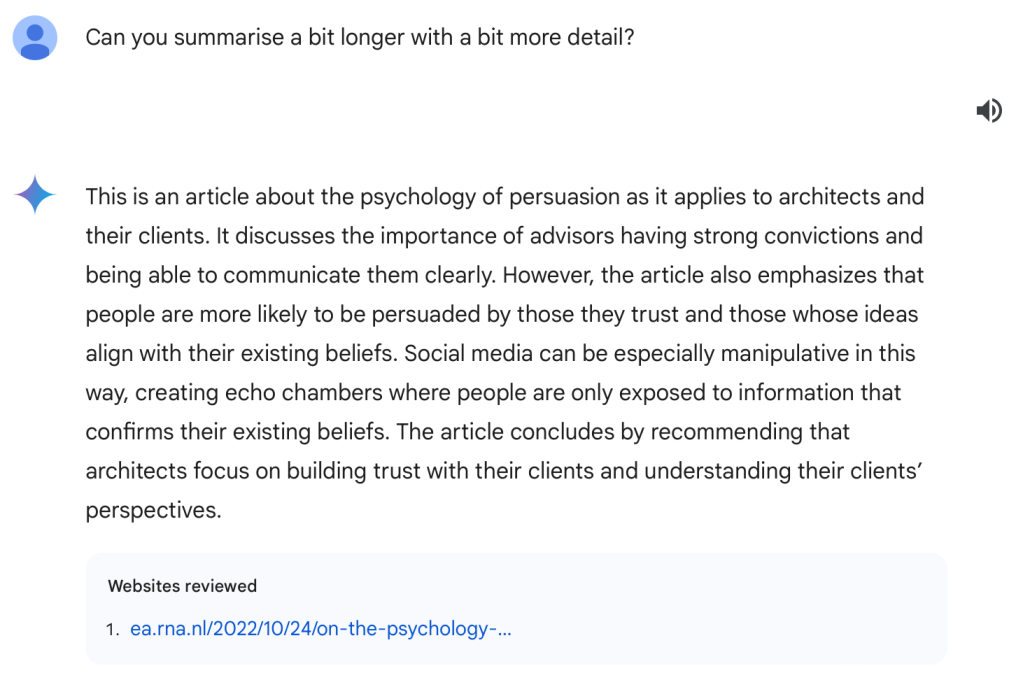
例如,占论文正文约 25% 的主要提案——利益相关者委员会,在 ChatGPT 的摘要中根本没有提及。作者认为,真正的总结需要对文本有深刻理解,而不仅仅是减少字数。
作者还发现,当文本中包含大量铺垫内容时,ChatGPT 的注意力机制可能会将这些铺垫内容视为更重要的部分,从而忽略关键结论。
这表明,ChatGPT 在处理总结任务时更倾向于根据训练数据生成内容,而非依据实际文本的重要性。
此外,作者尝试了其他实例来验证这一点,例如让 ChatGPT 总结柏拉图的《普罗塔戈拉》,结果也显示 ChatGPT 生成的摘要更多依赖于训练数据,而非实际文本内容。
作者还提到,另一款语言模型 Gemini 在总结方面表现稍好,但同样存在遗漏和内容捏造的问题。
最终,作者总结道,LLMs 目前的 “总结” 功能实际上是 “缩短文本”,并不能满足真正的总结需求。
"LLMs 的总结看似可靠,但实质上缺乏对文本的深刻理解。"
这种现象说明了 LLMs 在理解和提取文本核心内容方面的局限性,并呼吁人们在使用这类工具时保持谨慎。