

阅读没有目录的 PDF,如同不带地图就去陌生之境涉险。
可惜,在线书城割据的当下,提供书籍下载的厂商本就凤毛麟角,进一步提供 PDF、还给你做好目录的,我所知只有图灵社区^1,而在2023年之后,这颗仅存的硕果也不复了。
好读书之士,几乎只剩自制目录一途(姑且不论花钱找人代劳),此时却会发现并不方便。Windows 上的工具不少,但我用得不多,不评论;macOS 这边则在闹饥荒,而且还两极分化,要不基础如 PDFOutline,要么就过于追求自动化,反而很容易失效^2。
或许在完全人工与全自动化之间,尚有第三条路径——半自动化。我并不奢求某款神奇软件能从扫描版 PDF 中自动提取文字并创建目录,只求能够保证:在已有文字版目录时,能据此在 PDF 中添加目录。
一旦将获取文字版目录(包括页码)和在 PDF 中创建目录两件事分开,那么略显笨拙却极其可靠的半自动化方案,也就浮出水面。
会员请登录以下载 Keyboard Maestro 动作。

第一步:获取文字版目录
全手动添加目录的工具尚有几款,比如本文选择的 PDFOutline,以及诸位想必非常熟悉的 PDF Expert(但这玩意儿需订阅,我没买,故不评价)。手动操作,本质上就是创建创建一个条目(entries),再填上对应的页码,非常机械,也的确很累人,而且和扣扣子一样,一旦漏了或重复一次,后续的目录页码可能就会全部乱套。本文所取的方案,即先获取条目和对应页码,编成表格,最后再用 Keyboard Maestro 模拟键鼠操作、创建目录。
第一步当然是先获得目录信息,即条目和页码。最幸运的情况下,有些文字版 PDF 本身就可以拷贝目录;不过多数书籍可能还是要上网查询,除了最容易想到的豆瓣,也可以从京东、当当、大書城(megBook)等电商网站上看看有无目录,另外,出版商也可能提供目录及页码。
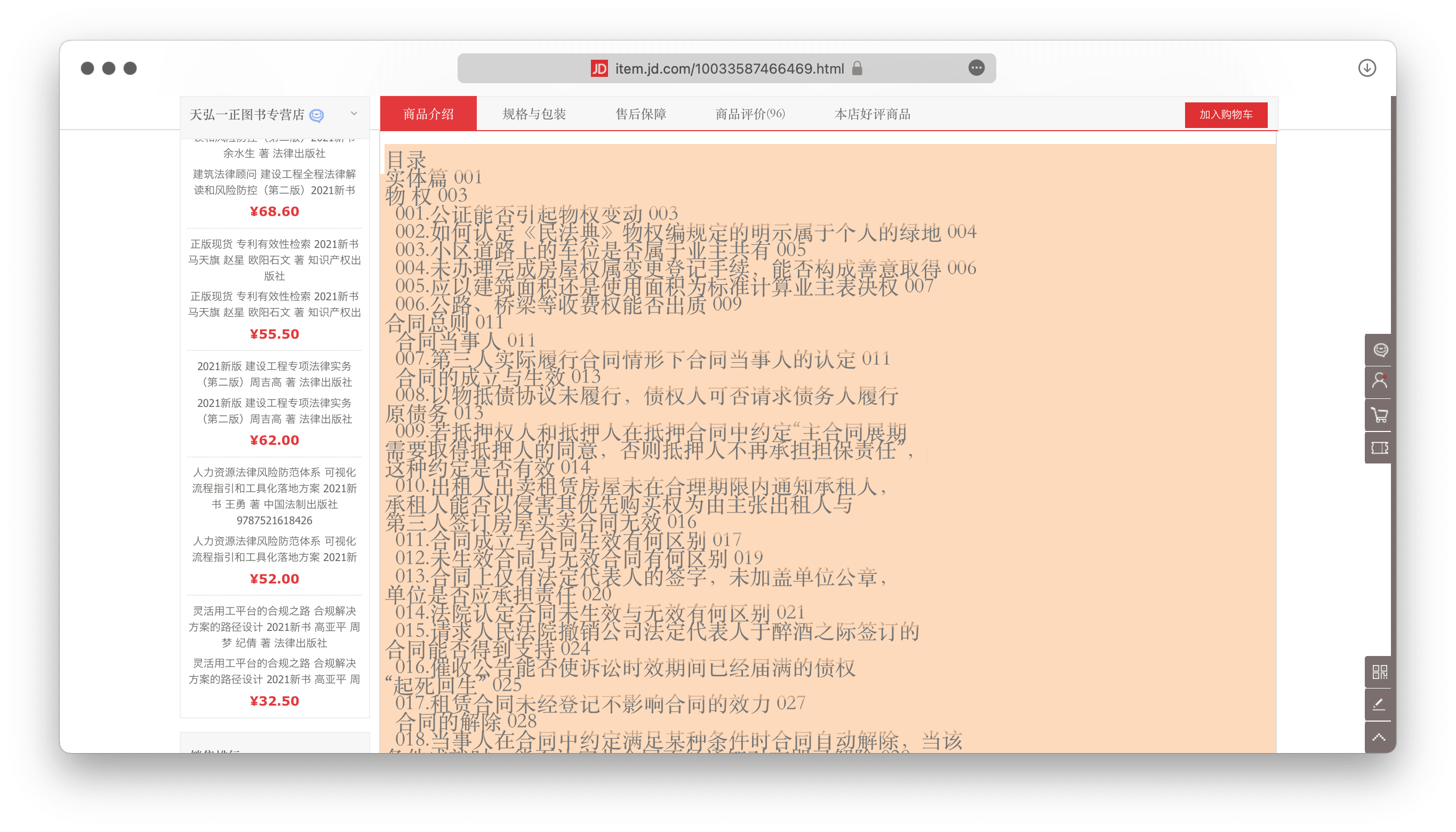
实在运气不好,还剩下手动提取文字这最后一条路。所幸如今 OCR 工具普及——最不济,还能用微信——三百来页的书,若有四五页目录,大概也只需要几分钟就能复制下来,常接触外文书籍的,还可以参考《Keyboard Maestro x OCR,在多语言环境中轻松抓取文字》。
手工制作目录固然要一些力气,但比起难如抽丝的阅读,这点时间实在 微不足道,个人使用大概已经足够。说到底,这篇文章也不是给终日制作盗版书之徒写的。
第二步:整理成 Numbers 表格
获取条目和页码后,就可以制作一份表格,将数据收拾整齐,以便在后续步骤中 Keyboard Maestro 可以准确获得所需数据……