

曾有一张流传甚广的图片,图上只有一支铅笔和一盒磁带,发布者留言:知道这项技能的人都老了。

发布者所谓的失传技能,是指当磁带卡住时用铅笔转动磁带。年轻的读者别说此技能,恐怕连磁带都不认识,搞不好连带橡皮擦的六棱柱铅笔都没见过(我真的见过这样的小孩)。
随着数字音乐——更不要说流媒体——流行,转磁带之技注定失传。然而,时髦事物背后也带着资本的意识形态,新一代不是简单地掌握了新技能的集合,而是更多地追求无缝技术、用户体验和傻瓜式功能。
付钱解决一切?这恐怕有些问题。我诧异地发现,即便在生产性的领域,例如制作电子书时,多数人也习惯了将目标与消费混同,总喜欢问“我该买什么软件”。事实上,很多事情不应该或根本不可能用钱解决,你可能需要重拾种种低技术,尤其是被遗忘的上一代技能。
本文试以从英文扫描版 PDF 自制双语 EPUB 电子书为例,展示一套低技术的电子书制作流程,借此谈谈为何需要在数字时代掌握基本手艺。
不少重要的出版物——主要是年代较早的——并没有真正意义上的电子版,充其量,你只能找到扫描版。若是中文也罢,可这世上多数重要的书籍是用英文写的,于是我们一下子被好几道围栏隔在外面,最后往往只能不了了之,搁置这些材料。我最近刚好遇到一本文采斐然但只有英文扫描版的书籍:知名广告人 Gossage 的 Is There Any Hope for Advertising。不同于传统印象中的广告狂人,Gossage 以其对广告的批判著称,其思想至今在西方互联网上有回音。我一方面想看 Gossage 的书,可另一方面,这于我而言毕竟是业余杂书,我实在没空抽时间啃原文。于是,我将扫描版英文书 PDF 制成了中英双语的电子书,快速消化(Gossage 的文风相对平实,译成中文后损失不大)。

如果你寄希望于某个神奇的一键式转换软件,恐怕只会失望,因为扫描版 PDF 并不能直接转换为文本格式,不仅页眉页脚会混入正文,换页时被截断的句子也无法正常翻译,你好像往一台香肠灌装机里倒入了混着碎骨头的肉末,成品难以下咽。
但如果我们抛弃傻瓜相机式的思维,认认真真看看手头的 PDF,兴许会发现,其实只需一点手工劳动,就能打通自动处理的各个环节。这些手艺,就像在去除数字世界中的骨头碎,只需少量人工劳动,就能让 OCR 和对照翻译等工业机器顺利运作。
让我们开始处理这份棘手的 PDF。OCR 往往是自制电子书的第一环,借此提取文本,随后才能编排或翻译,但通常情况下,书籍的页眉页脚等枝节部分也会混入 OCR 结果,把原本连贯的文本切得七零八落,导致后续无法正常编辑或翻译。

其实,在 OCR 之前就可以批量移除页眉页脚。只需借助原生的预览工具(Preview.app),选定所需部分,按下快捷键 ⌘Command-K,即可裁下正文,撇去边角。但凡书籍扫描时不至于过分歪斜,你就可以先在侧边栏中批量选中多个页面,随后统一裁剪。当然,目录、版权页、章节第一页可能有特殊排版,尚需分开裁剪。
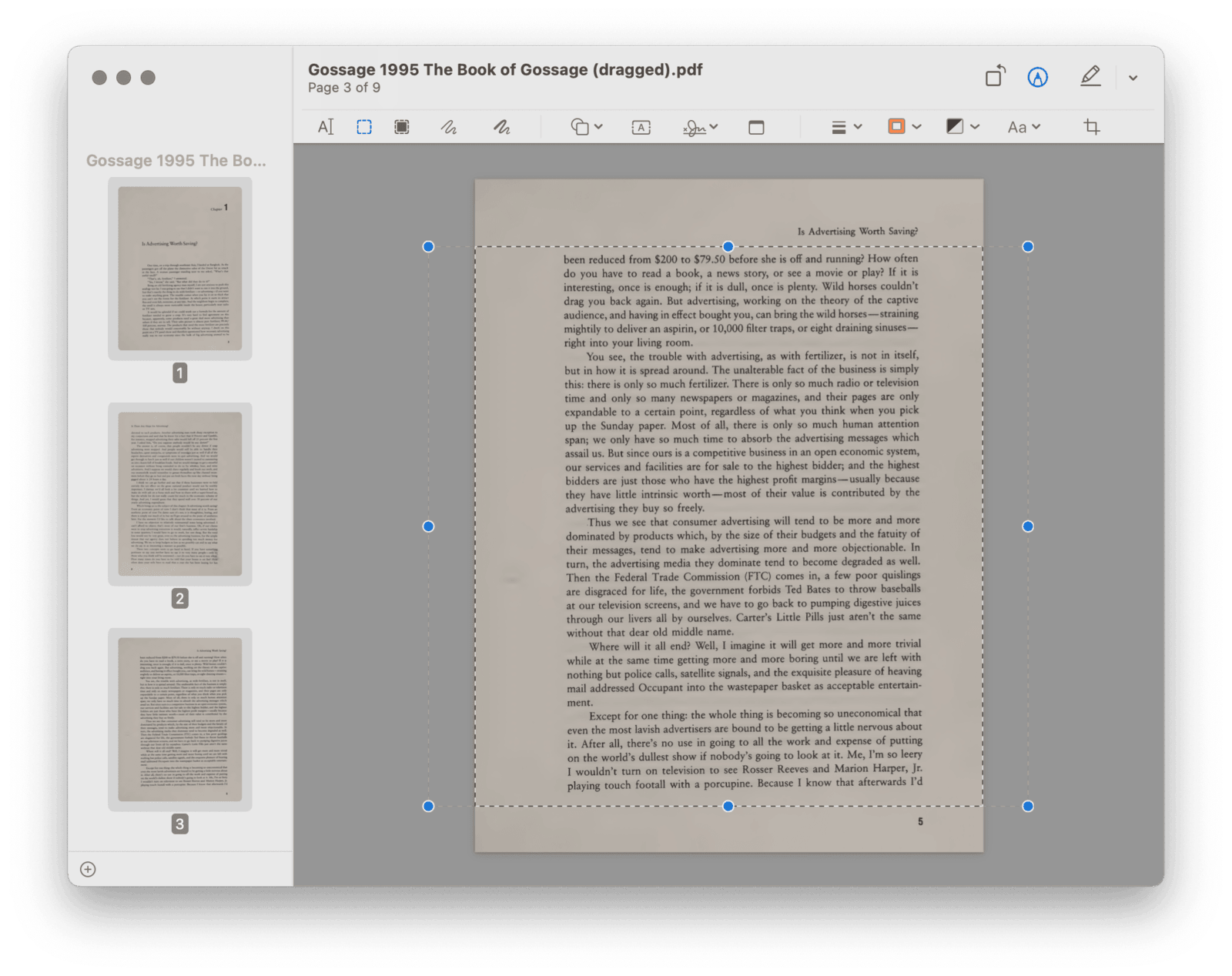

视书籍不同,偶尔也要裁掉页边的注释方能正常 OCR。Is There Any Hope for Advertising 倒不存在这种情况,但我购买的不少台湾地区出版物则喜欢在页边钩玄提要,虽说方便了读者,却难为了 OCR 引擎。这类书籍若需转为文本版本,我也会事先剪掉页面边缘。
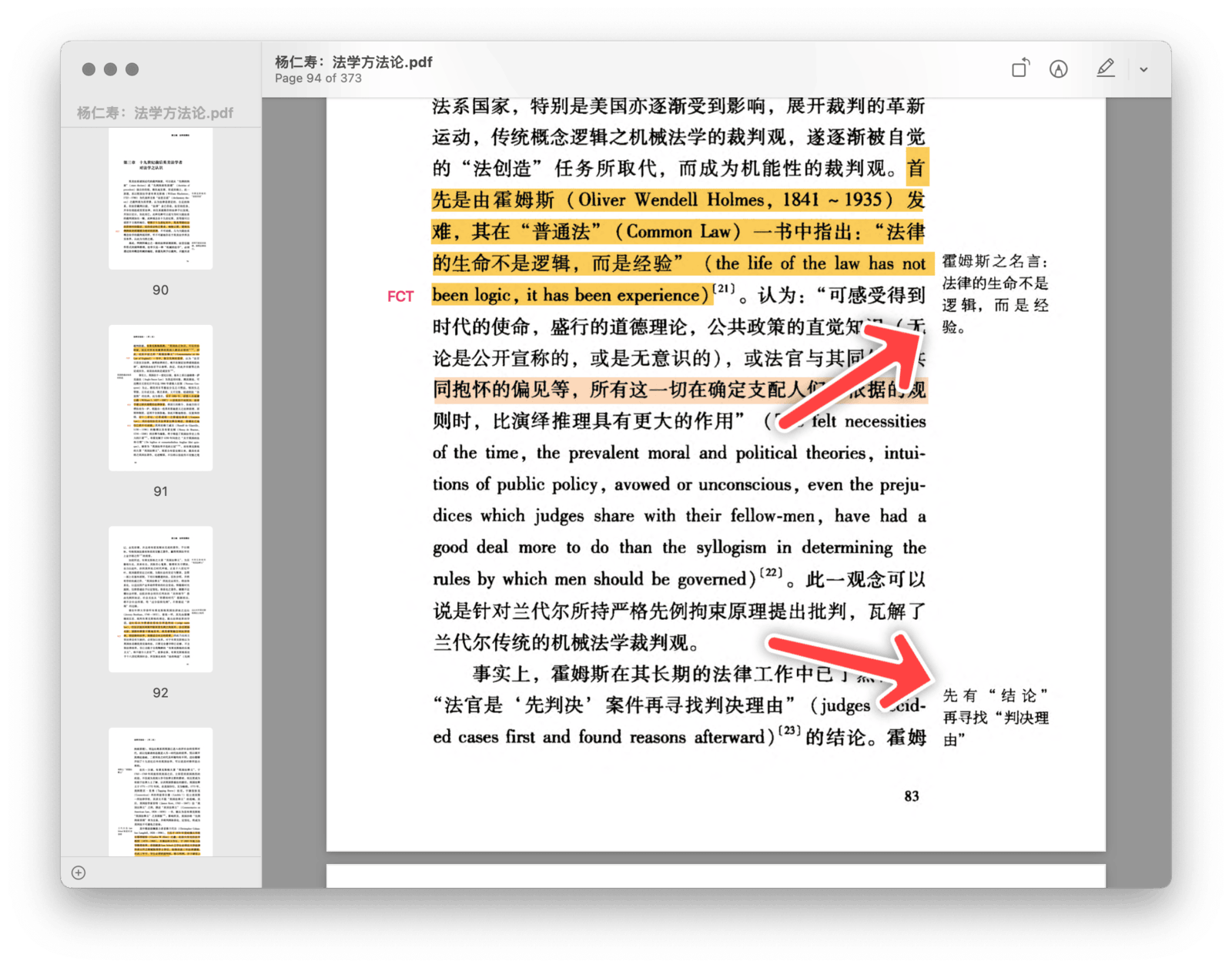
一旦切出正文,OCR 通常会势如破竹,很快可以得到整齐的文本。顺予指出,事先裁剪还可以避免乱码,我曾在 UNTAG 付费栏目中分析过 OCR 乱码问题,发现部分原因在于书籍版面复杂,而一旦切掉上下左右的多余文本,只留整齐的逐行文字,OCR 引擎的压力也会小很多。
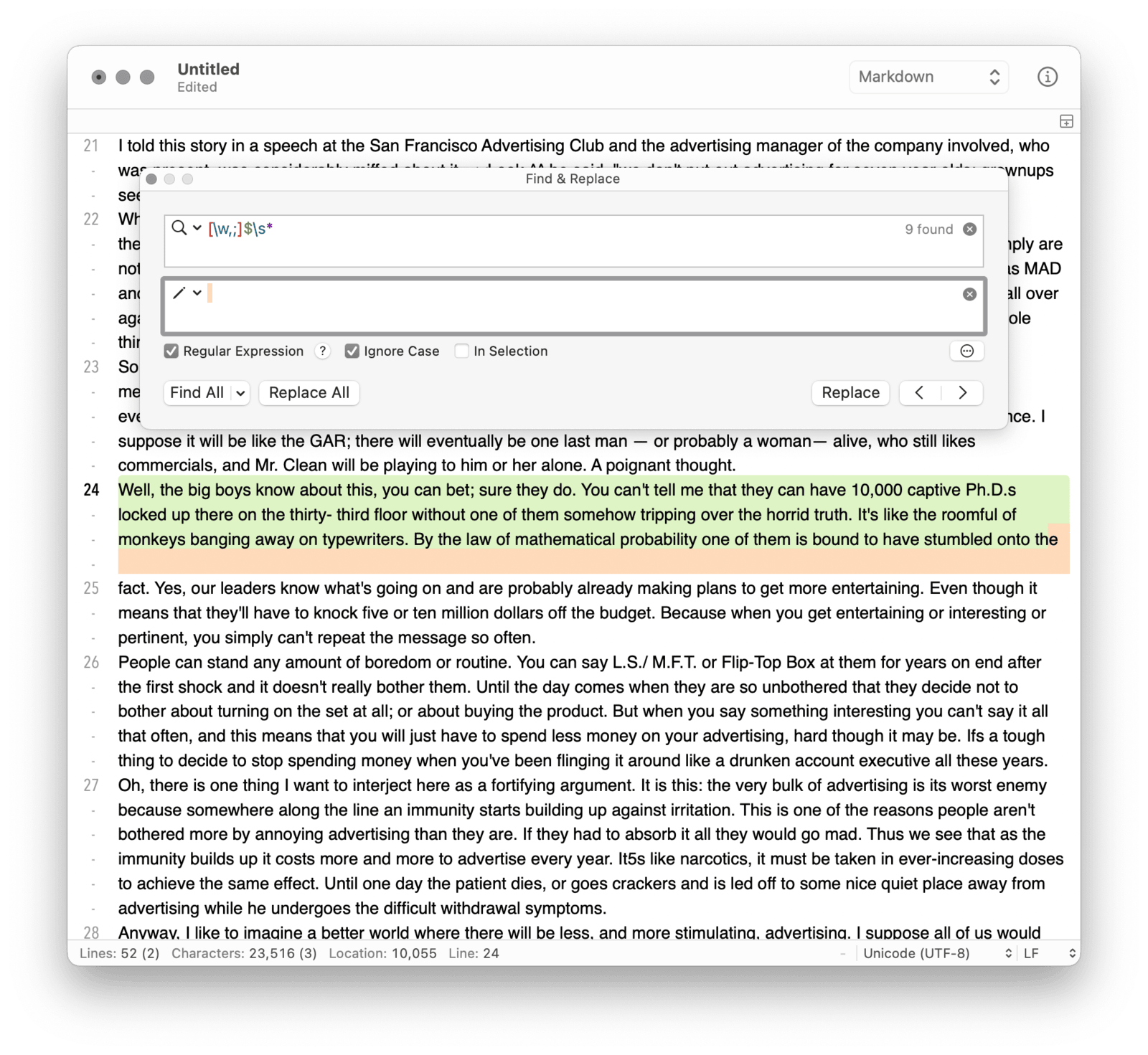
至此,应该已经得到了不掺杂质的文本。但就英文资料而言,换页时往往会带上换行或多个空行,导致连贯的句子被分成两部分,翻译时也显得莫名其妙——毕竟,一句话被砍作两段,结果即便就是前后都不正常。为此,还需修复多余的换行。
此时完全不需要逐个手动修复。转念一想,大可把换行修复任务还原为简单的字符替换问题:凡是不以标点符号结尾的段落,基本就意味着此处因为换页而被意外截断,故只需借助正则表达式找到它们,再统一消除多余换行或空行。你需要找到匹配 [\w,;]$\s* 的文本,然后将其替换为空格。熟悉正则表达式的读者可自行选择工具,不熟的话,可尝试免费的轻代码编辑器 BBEdit 或 CotEditor。
拓展阅读:
俟得到修整完毕的文本,终于可以进入翻译环节。您可以选用现成的翻译工具,甚至是 Microsoft Word 内置的翻译功能,我个人更偏爱自己的对照翻译方案。

拓展阅读:
几番辗转下来,终于获得了一份原文与译文并肩的电子书,既可在电脑上阅读,也可以塞进手机或 Kindle,随时翻阅。回顾全程,自制一本电子书可能经历四五个版本的文件,估计早已让追求无缝技术的读者浑身冷汗了吧。
诚然,这样处理书籍,少则十几分钟,多则一个小时,实在无法和一键转换、一键翻译的商业方案相提并论。但是在这些时髦工具不奏效时,苟愿意稍稍花费一些时间,你就获得了世间独此一份的资料,领先同侪一步。
说到底,与抽丝般的漫长阅读之旅相比,这点手艺活儿的时间,实在不值一提。