

对于微博上的内容,我好像有一些天然的“轻视”,在使用微博的前几年里从未想过要主动收集该平台的资讯,基本刷过就算。某次想起有网友发过一则软件技巧,一翻点赞记录,却发现微博点赞列表里满是被删除、无权访问、或者涉嫌违规的提示。
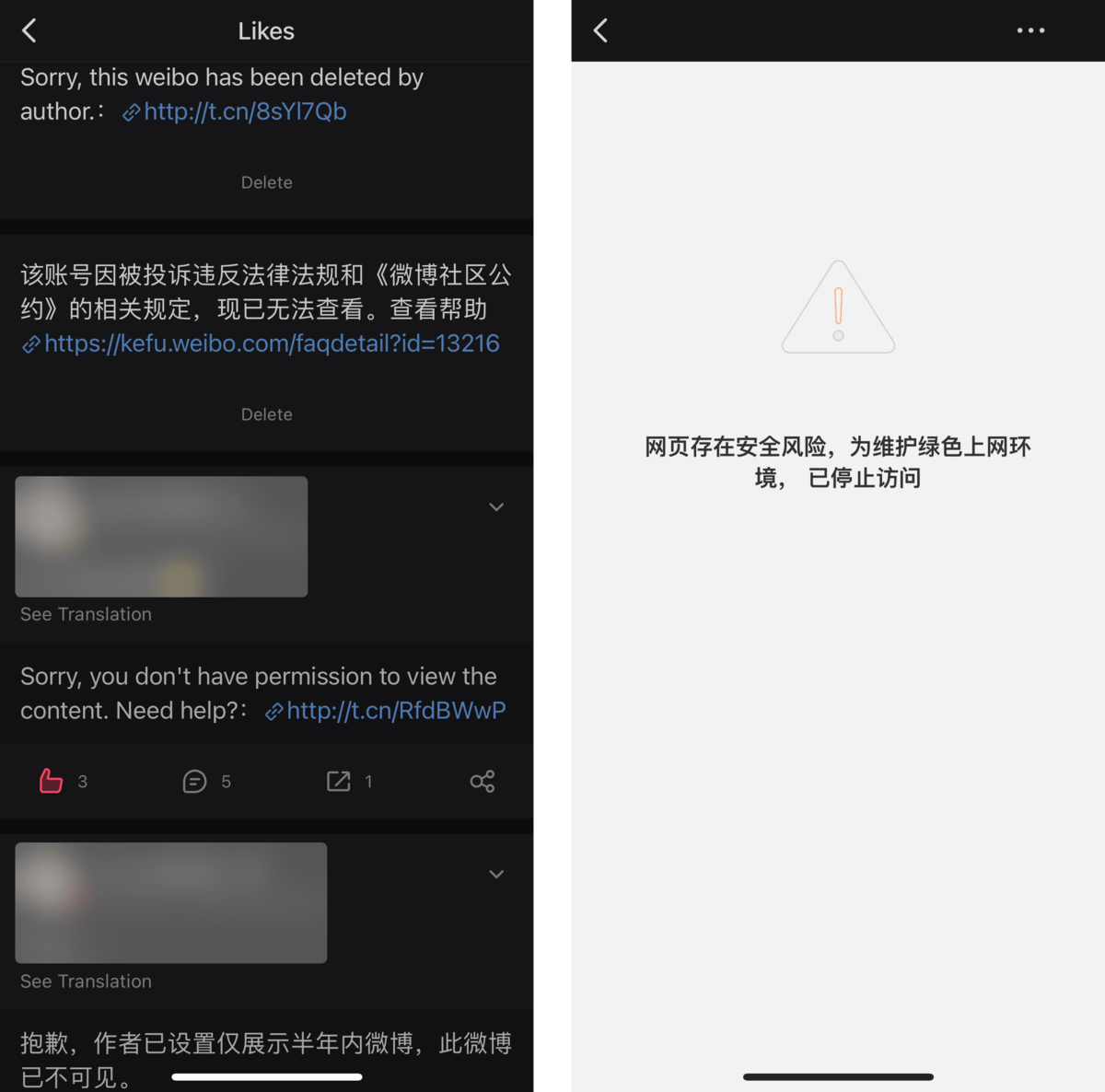
这时候我猛然意识到,微博里数据根本不属于自己,而当它们失效时,根本无从得知失去了哪些信息。自然而然地,我又把做摘抄提上了日程,或者说,把微博内容也纳入 DEVONthink 摘抄体系1。你可以在下面下载 Shortcuts 动作,并在我的 GitHub 上第一时间收到动作更新。
莫如说,任何平台、渠道都应当一视同仁,但凡遇上有价值的信息,最好当即捕获到本地。需要公道地指出,在微博摘抄这个场景下可能有频繁的图片存储需求,故微博的印象笔记收藏功能比我的 Markdown 方案更好,如果诸君对收集图片的要求较高,大概没有比使用服务更简捷的了;如果摘抄内容以文字为主,并且希望和来自网页、Instapaper 或 Kindle 的摘抄统一管理,则本文方案更合适。
微博摘抄流程
微博客户端多矣,出去官方普通版、国际版、极速版,还有墨客、奇点等第三方客户端,不想装软件的人可能还会选择网页版或 PWA(Progressive Web App,渐进式Web应用)……这些不同终端的图文呈现方式千奇百怪,似乎希望 Shortcuts 适配那么多客户端是不太可能的。所以本文选择了一种直抵病灶的思路:获取一则微博的链接,然后解析其背后的数据,最终整理成 Markdown 格式存入本地。
从官方各个版本的微博,到第三方开发者的客户端,只要能够找到分享链接,就可以使用本文 Shortcuts 动作。以微博国际版为例,使用方法如下:
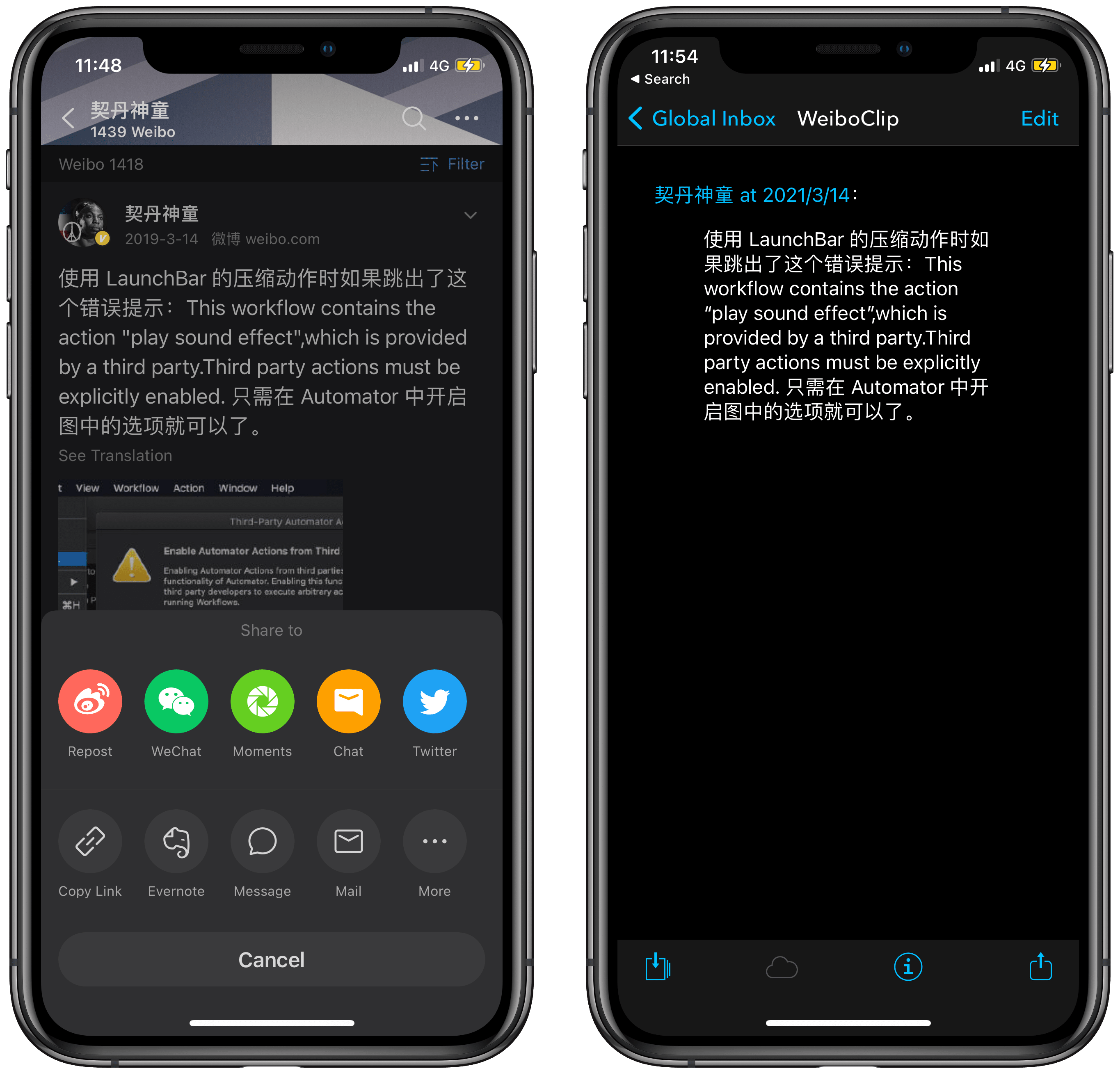
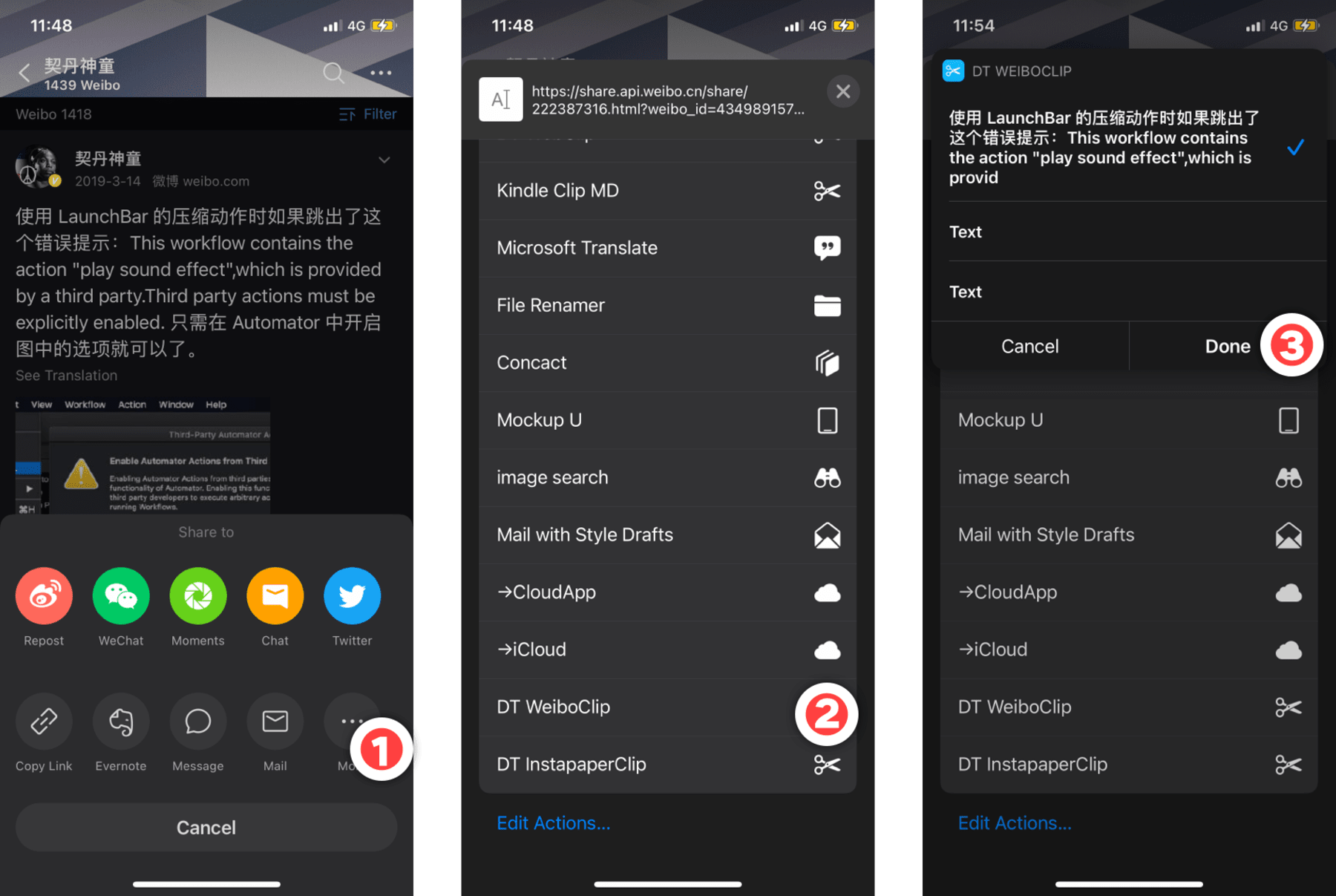
- 在目标微博的右下角找到分享按钮,并点击弹出窗口的“More”选项以启动系统分享菜单;
- 在系统分享菜单中运行“DT WeiboClip”动作,稍等 Shortcuts 读取数据;
- 在弹出菜单中选择所需内容存入 Markdown 文件。这一步中,Shortcuts 会按行拆分微博正文(及评论),方便剔除空行、整行表情以及评论等“水分”。
Markdown 文档的内容与网页摘抄略有不同,从网页摘录内容时通常需要标题、链接、正文以及阅读时间,而微博的发布时间可能更重要,因为其时效性更强,平时刷到的往往也是新鲜发布的微博。具言之,微博摘抄的模板如下:
[发布者 at 发布时间](微博链接):
> 微博内容
存入 Markdown 后,DEVONthink 会将第一行渲染为超链接,需要回溯原始微博时点击这一链接即可访问。当然,留下链接只是举手之劳,做微博摘抄的出发点就是避免原始链接失效无法浏览。总之,通过这一套摘抄流程,就能够把感兴趣的文字微博抓取到本地。
从不同的摘抄场景看 Markdown 的优势
微博摘抄的思路从网页摘抄一脉相承,存储格式同样是 Markdown,浏览工具照旧是 DEVONthink(以及其他 Markdown 编辑器),自动化调味料依然是 Shortcuts;不过,微博和网页的摘抄格式却有细微差异,前者没有具体时间(稍久的内容就就不能精确显示到分钟),后者则有,并且可以添加一小段 HTML 代码来美化排版、使时间靠右排布。
这种微妙的格式差异化在 Markdown 中非常容易实现,以后我们讨论 Kindle 摘抄时,还会引入标题语法 ## 来显示摘抄目录,根据书籍来源回顾摘抄——这当然也只需要几个简单的 Markdown 标记。从这几个不同场景下的摘抄需求可以看出,最好一开始就选择一种宽容度较大的存储格式。
进一步说,Markdown 的标记还赋予了 Shortcuts 更强的自动化能力。微博摘抄其实是网页摘抄的“降级版”,毕竟一则微博通常之后做一次摘抄,不太可能存在网页摘抄中的“去重”(即将来自同一篇文章的摘抄汇集一处)要求;网页摘抄就比较麻烦,需要设计一套机制把新摘抄“插入”原 Markdown 文档中的指定位置。
之前我使用印象笔记或 Evernote 充当容器时,勉勉强强钻了 HTML 语法的一个空子,混用 <p> 和 <div> 两种标签当作此篇文章之摘抄与前后两篇文章的分界线,而它们在视觉效果上几乎没有差异——这当然是一种不值得鼓励的 Hack,在导出笔记到其他服务时就就会被电脑识别出猫腻;而 Markdown 语法则自始不需要这些小把戏,其自带的 []() 标记就是一种天然分界符。一言以蔽之,Markdown 拥有“天然安全性”,而挪用 HTML 标签只是一种明修栈道、暗渡陈仓的“工程安全性”,天知道哪天迁移笔记时出什么幺蛾子。
Markdown 的另一优势则是不挑食,随便一个编辑器就能打开,最差的情况下——没有安装任何编辑器——还可以用自带的 Files 浏览大致内容,虽然不好看,起码不至于杂乱不堪。
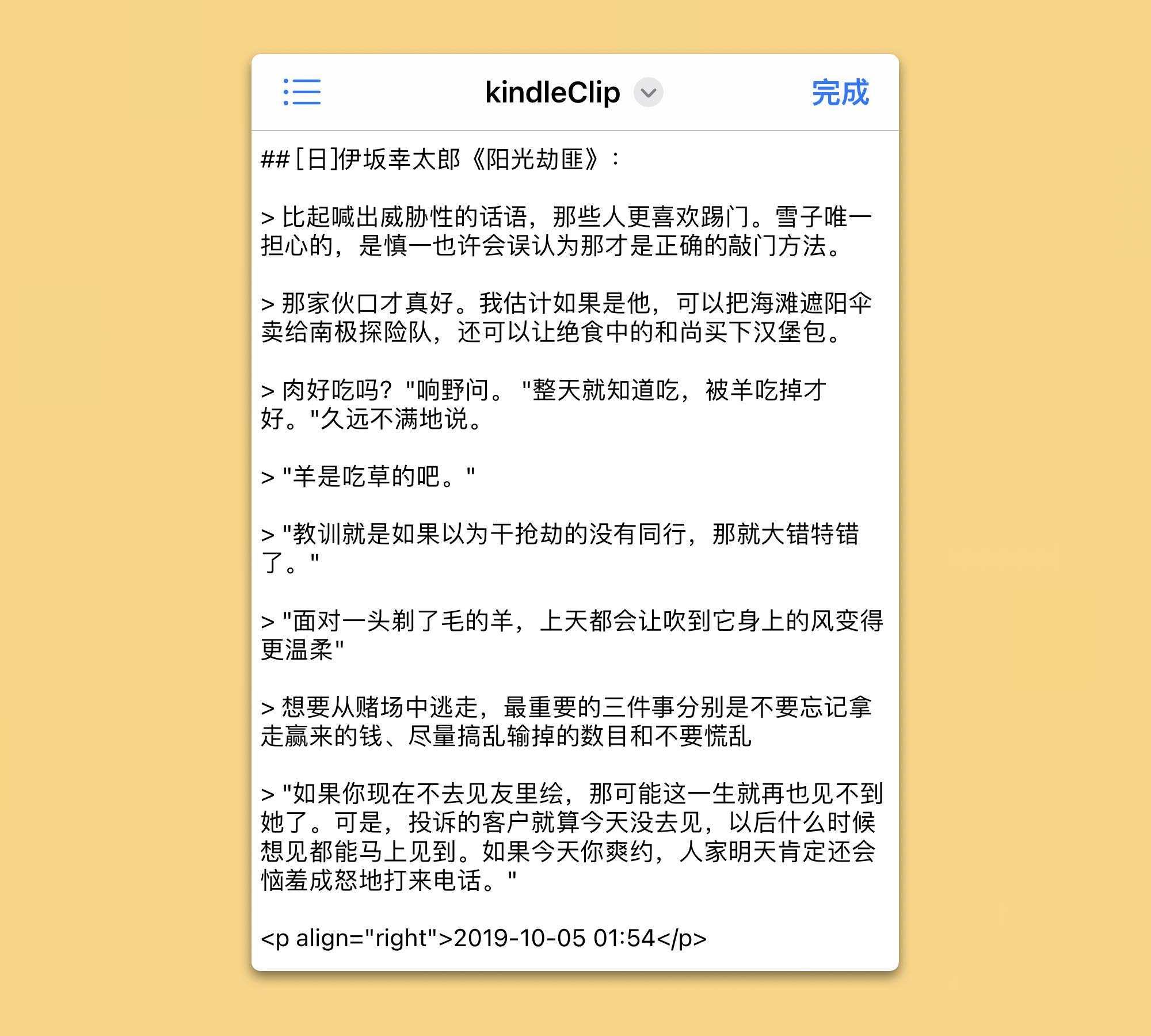
下可兼容系统文件管理器,上也能套用 CSS。在《用 DEVONthink 做网页摘抄,夺回数据所有权》一文中,我已经展示过在 DEVONthink 中引入 CSS 来美化网页摘抄的效果,微博摘抄既然与中此前的方法同宗,同样可以使用这些 CSS 主题,能屈能伸。
最后,Markdown 不存在“同步设备数量”这种限制,我的摘抄毫无疑问地属于自己,不存在各种付费方案来剥夺我访问个人数据的权利。想想吧,如果你有“苹果三件套”,就意味着不掏钱的话只能在其中两台设备上查看印象笔记中的摘抄,这种寄人篱下的着实古怪。
承上启下的一节
和微博对标的信息渠道是 Twitter,但很可惜,Twitter 不允许通过 Shortcuts 的“Get Content of URL” 访问其数据(从技术上讲,Twitter 页面必须在开启 Javascript 的环境下才能打开,这通常意味着要在浏览器或客户端里手动打开页面,而不能通过 Shortcuts 等自动化工具获取数据。),这无疑封堵了自动化摘抄的途径,不过好在只是堵了其中一环,日后如果能够绕过这一藩篱,仍然可以融入 Markdown & DEVONthink 摘抄体系。
至此,在线阅读摘抄系列文章已经发布了两篇,后续还会发布几篇,尽可能覆盖到主流的信息渠道。在未来的文章中,Markdown 纯文本、DEVONthink 文件管理和 Shortcuts 自动化这些思路还会继续发光发热。
- 还是再琐碎几句,DEVONthink 只是 Markdown 摘抄的容器之一,完全可以使用任何其他支持的 Markdown 软件。 ↩