


没有任何一项技术,可以像人工智能一样让人感到恍惚,似乎搜索范式的根基已被撼动。本作动笔之际,第一代 GPT 方兴未已;而本作收笔之时,多模态的人工智能模型已经交付到了每一个用户手上。
人工智能给搜索带来了两个挑战,第一个挑战非常严重:整个搜索技术是否会被人工智能彻底取代,我们如今视为互联网基础设施的搜索引擎,以后会不会全部简化为一个人工智能聊天框?第二个问题则是在否定或回避前个问题的基础上提出的:人工智能会怎样改变辅助现有的搜索技术?
2022 年,以 ChatGPT 为里程碑,一大批人工智能驱动的搜索工具相继问世,这些工具已经对上述两个问题表明而立场:一类工具显然非常自信——典型如 Claude、Perplexity 或 Neeva——坚信人工智能可以彻底取代传统搜索引擎,这类工具通常模仿 ChatGPT 的交互方式,除了一个输入框以外几乎什么都没有,你好像前往了一间赛博神殿,向一个(不知道是否可靠的)电子上帝祈求下达神谕。1
另一类软件相对保守,它们本质上还是传统的搜索引擎,人工智能主要在一旁提建议或做总结,或者仅仅在背后提供动力。例如 Microsoft Bing 搜索以及迟到了大半年的 Google 搜索,都开始在搜索结果顶部插入人工智能生成的简短回答。
无怪乎,西方世界感叹:人工智能搜索引擎大战开始了。不过,抛开媒体辞藻不说,无论这些工具开发商有意无意,它们都旗帜鲜明地站在了替代主义或辅助主义其中一个立场上。因此,现在是讨论人工智能和搜索引擎关系最恰当的时机,我们有足够的案例,同时又亟需找到方向。
第一波冲击
人工智能带来的最大冲击,显然直指传统搜索引擎存在必要性,毕竟,如果你拿起手机——在理想情况下,你甚至不需要拿起它,甚至连“嘿Siri”或者“OK Google”都不必说,只需把脸转向某个智能设备——就有机器人帮你整理好答案,为什么还要自己在一长串的网页中辛苦总结、提炼?
作为一个例子,Siri 搜索就饱受批评,除了几个内置的问答功能,它基本只会给你弹出一串链接,让你自己去搜索,说白了,Siri 搜索在多数情况下约等于语音输入法加浏览器输入框,完全感觉不到任何人工智能。确实,很多时候,我们希望尽快知道答案,而不是获得一长串的搜索结果。
——但,追求答案恰恰反映了人们关于搜索的根本误解:相当一部分人,或许是绝大多数人,他们只想要答案,而不是信息源。
诚然,如果你只想知道煮鸡蛋的最佳时间或者炒四季豆怎样避免变黑,那么米其林三星主厨和你老妈给的答案不会有什么区别。但是,如果你想知道乳腺癌早期应该接受哪些治疗,或者等你被无故裁员时如何维权,此时百度搜索边上的小广告和一个执业医师或执业律师给出答案将有天壤之别。
关键在于,信息太多了,而其中相当一部分亟待检验。有些问题太容易检验,以至于信息源其实不是什么大问题。比如家常菜的做法,如果你不深究原理和营养配比,那么几乎任何一个通用搜索引擎都不算差。我父亲厨艺相当不错,但他只需要百度,根本不去钻研深奥的料理书,因为他三餐都自己做,当场就能验证搜索结果是否可靠。
也有人无法理解,为什么有人相信 GPT 生成的代码?很简单,shut up and run the code。代码能跑就能跑,不能就是不能,和谁写的没有关系,而你只需一秒就能知道它有没有用。
当然,做菜包含了太多常识,我们很容易发现哪些博主在造假,例如用翡翠般的生蒜苗伪装成品(成品一般是暗绿色)或用宝石般的生茄子冒充熟菜(煮过通常会变黑)。但更专业的知识则不那么容易亲自检验,此时,信息源就是背书。
如果本作只能让你记住一件事,希望那就是:重视信息源。人工智能日益强大,或者说正因为人工智能日益强大,你才更需要检查信息来自何处,而不是随意轻信人工智能。那些定制化的人工智能(例如 GPTs)像极了角色扮演游戏的主角,假装自己什么知道,但你凭什么相信这些电子大脑比一个做了一辈子律师或法官的老人更值得信赖?
技术作家 Rao 指出,世界上的信息可以分为设计数据(Design knowledge)和构成数据(Constitutive knowledge),前者可以短时间内演绎出来,后者需要艰难检验、千锤百炼。人工智能所生产的数据是前者,或许看上去头头是道,但通常没有经过现实世界的检验;而一旦你想验证它们,之前飞快上升的速度曲线就会瞬间放缓。我在和读者的往来中也曾提出,人工智能的检验很可能是个 NP 问题2,验证答案的时间还不如拿去自己重做一遍——就构成数据而言。
……overall, generative AI produces untested design data, not reality data. Which means it will run into the same sorts of problems human- generated design data does, when tested against reality.(总体而言,生成性人工智能产生未经测试的设计数据,而不是现实数据。这意味着,当根据现实进行测试时,它将遇到与人类生成的设计数据相同的问题。)
尽管对死者有些不敬,但可以确认,那些听信莆田系医院广告而最终失去生命的人,或许从一开始就搞错了一些东西。悲哀的是,多数人其实和这些往生者的心态完全一样,只不过还没有踩到地雷罢了;同样可悲的是,世界之所以相对稳定和平,人工智能先驱也没有被抬上火刑架,只不过因为多数人根本不懂技术且漠视技术。对于绝大多数人来说,根本不需要讨论 ChatGPT 是否会成为新的机械降神,毕竟,百度搜索对多数人来说已经是电子上帝了,人工智能无非是二世而已。
来源问题本质上是信息质量问题:信息是否容易检验?是否需要背书?能够意识到这些问题的人,恐怕从一开始就不必担心他会成为电子上帝的殉教者。但本文还是有必要简短总结:如果某个人工智能旨在取代传统搜索引擎,那么它本质上只是提供了替代信息来源,而信息应当加以检验,此时,如果人工智能只是给你统计结果而没有原始数据,那么所有检验负担就落到了使用者身上。没有背书。易言之,人工智能是否会取代搜索引擎,只取决于你敢不敢冒如此大的风险。
第二波冲击
如果人工智能不那么傲慢,并不企图完全取代传统搜索引擎,它们又将扮演怎样的辅助角色?
Microsoft Bing 和 Google 搜索代表了貌似最为低调的形式:总体上,你看到的东西和以前一样,只不过在搜索框最下面——或者说搜索结果列表最上方——会有一小段人工智能生产的简要回答。
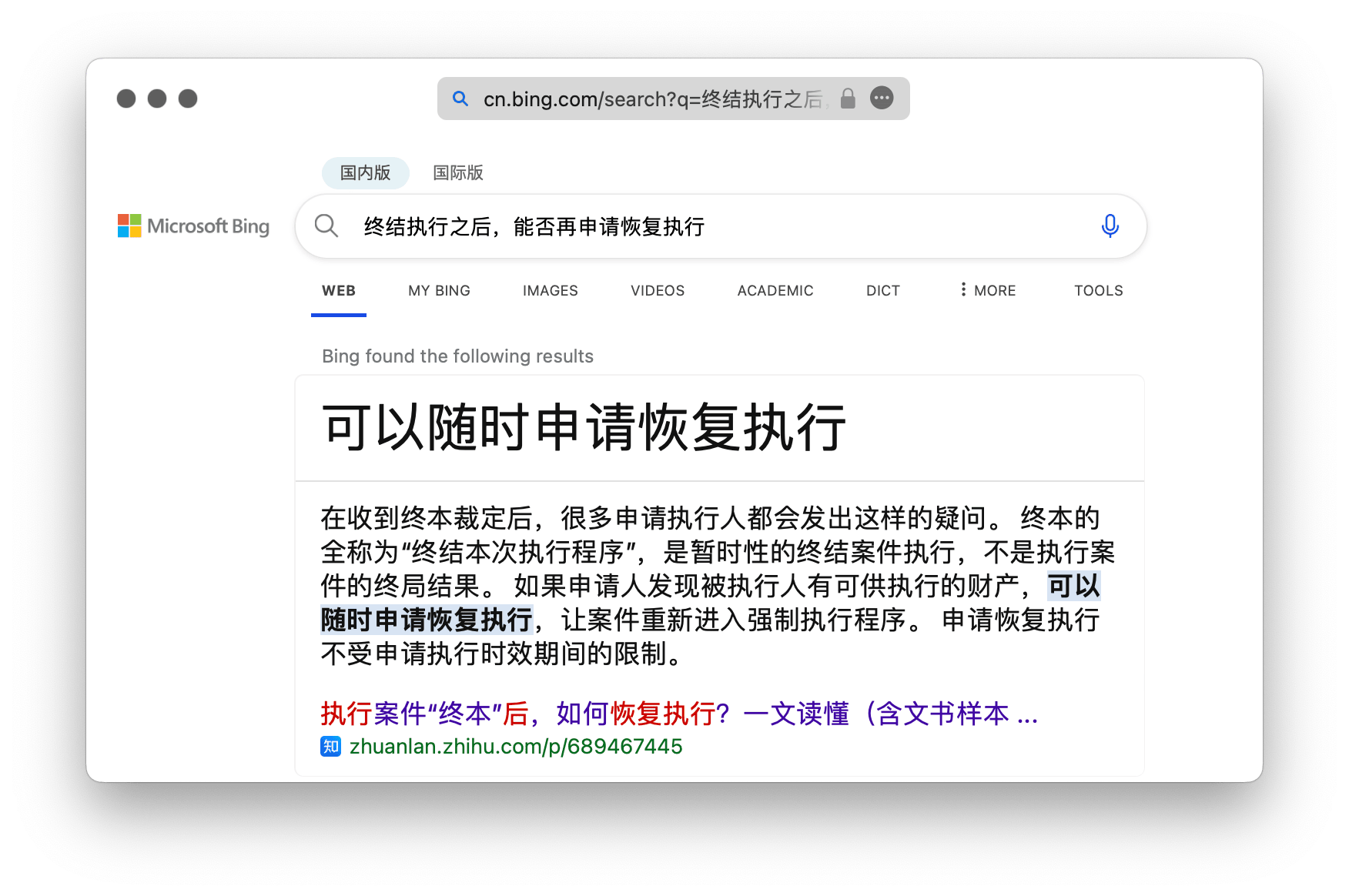
大概是因为 Bing 和一批替代主义者同时登场,似乎没什么人抱怨 Bing。然而,当 Google 也推出类似的搜索建议且不允许关闭时,立即引发众怒。这种反应其实在预料之中:人工智能概要从根本上撼动了搜索引擎的中立性,如果它们还有中立性可言的话。Google 在一段时间内还将洋葱新闻当作真实消息来源,万幸,有个暴力方法可以抹除 Google 中的人工智能垃圾。
虽然搜索引擎服务商在排序算法上大有手脚可作,而且它们也早已公然插入广告3,但人工智能概要恐怕会更可怕:它以搜索引擎提供者、平台服务者无可质疑的权威身份,正面回答了你的问题,引导了你的检索方向。4当我问一个法律问题时,Microsoft Bing 不动脑子就给了一个答案,如果我并不熟悉相关领域的法律细节,我很可能会相信它,或至少把这个答案当作主流立场。5
然而,无论回答本身是否正确,信息搜索者的处境都非常糟糕:如果答案是胡乱生成的,那当然很糟。事实上,我遇到的多数答案都是胡诌,有时答案所引用的文章完全持肯定立场,Microsoft Bing 也会给我一个否定的答案,就算你用 macOS 自带的缩句工具,确率估计也比所谓的人工智能高。
如果答案比较准确,同样令人毛骨悚然。当然,类似于泡面煮几分钟最好吃这类问题,合理回答本来就集中在一个区间内,人工智能也变不出什么花样(可以观望一样有什么新花样),但搜索者最关心的往往是复杂问题,或许至今为止都还有争论。此时,人工智能总是急于站队和带节奏,像一个刚刚入学、尚未从高考胜利中回过神来的本科生一样,跳到你跟前给出一个无比自信的回答。6
话说回来,几个主要的搜索引擎起码尽了“提示义务”,用特殊颜色围住了人工智能答案,至少在和你正面交锋。如果搜索引擎在排序算法里面也引入了人工智能,无法想象后果如何。最近几年人们不停抱怨 Google 搜索和 YouTube 搜索越来越难用,不知道是不是人工智能在幕后作祟?归根结底,人工智能也只是一种软件,大型语言模型也只是一个模型,而正如评论员 Steven Levy 在上世纪所发现的,软件或模型的生产商很容易将其意识形态藏在工具之中,这比“垃圾进,垃圾出”的警句更可怕,因为工具本身就已经很有倾向性。
An often-repeated truism about computers is “Garbage in, Garbage Out.” Any computer program, no matter how costly, sophisticated, or popular, will yield worthless results if the data fed into it is faulty. With spreadsheets, the danger is not so much that incorrect figures can be fed into them as that “garbage” can be embedded in the models themselves. The accuracy of a spreadsheet model is dependent on the accuracy of the formulas that govern the relationships between various figures. These formulas are based on assumptions made by the model maker. An assumption might be an educated guess about a complicated cause-and-effect relationship. It might also be a wild guess, or a dishonestly optimistic view. (关于计算机的一个经常重复的真理是“垃圾进,垃圾出”。任何计算机程序,无论多么昂贵、复杂或受欢迎,如果输入的数据有问题,都会产生毫无价值的结果。对于电子表格,危险不在于不正确的数字可以输入它们,而在于“垃圾”可以嵌入模型本身。电子表格模型的准确性取决于支配各种数字之间关系的公式的准确性。这些公式基于模型制造商的假设。假设可能是对复杂的因果关系的有根据的猜测。这也可能是一个疯狂的猜测,或者一个不诚实的乐观观点。)
我个人推测,人工智能技术已经在搜索引擎中运用多时了。斯诺登会告诉你,在技术领域,任何可能做的事情都已经做了。或许我们连这句名言都不需要引用,只需看看日益增长的数据总量和人工智能的整理能力,就足够猜想,任何一家不想破产的搜索引擎服务提供商都不可能拒绝人工智能,即便这是一场浮士德式的交易。
小结
以上种种关于人工智能的担忧,不仅没有削弱,反而强化了本作一贯的立场:信息源才是检索的黄金原则。如果你害怕神谕般不可置疑的回答,如果你担心搜索引擎结果列表边上的浮窗,其实你只需要做过去十几年里你一直在做的事情:打开原始链接。
当然,如果人工智能已经影响了搜索结果,悄悄把一些东西推到前面,偷偷又让一些网页遭遇神隐,那么,我们唯一见还能够庆幸的事情就是:世界上不止一个魔鬼,如果你怀疑谷歌已经违背了不做恶的承诺,那么,你可以看看其他恶魔给出了怎样的答案。我们唯一的希望就是恶魔们不要结为同盟,如此一来,至少一个理智的人可以在交叉比对之中找到属于他的真实。
除了——有时候甚至包括——煮溏心蛋需要几分钟这种太简单的问题之外,当我们在搜索框里面打字的时候,其实我们想要和网络那头的某个真实心灵交流。
- 部分工具也提供参考链接,但就像那些蹩脚的论文一样,你根本看不出“参考”了什么。如果还要我自己检查一遍,我要这些搜索引擎做什么? ↩
- NP(non-deterministic polynomial)问题指可以在多项式时间内验证其解是否正确,但不保证能够在多项式时间内计算出来的问题。 ↩
- 尽管根据不少地区的法律,至少要标明哪些信息是广告。 ↩
- 而且,我暂时找不到任何法律依据让这些服务者承担责任。 ↩
- 配图中的问题是我故意刁难 Microsoft Bing 的,我猜到它会用“终止本次执行”相关的答案来回答我关于“终结执行”的问题,因为实践中前者更热门,Bing 更有可能将其作为统计学意义上的正确回答。 ↩
- 在我父亲那个年代,教授可以甩这样的学生一个巴掌,但是你不能对搜索引擎服务商做任何事情,甚至你的咒骂或者疯狂砸键盘的动作都会变成数据回收到电子上帝的大脑中,方便它以后用更加亲切的方式控制你。 ↩