

The poor stay poor, the rich get rich
That's how it goes
Everybody knows
——Sigrid, Everybody Knows
对于任何一个认真的人来说,做笔记都是为了日后使用,而不是满足当下的快感。可惜,在适当的时候提取笔记却非易事,我们常常发现自己没有用上旧笔记,偶尔翻看,可能还会诧异:我什么时候写的这玩意儿?遂有一个讽刺却真实的概念:笔记坟场。
人工智能的鼓吹者宣布笔记整理已经终结。但是,人工智能1真的能让坟场将成为花园吗?我持有完全不同的观点。
本文将通过横向比对,论证人工智能可信的前提是能够轻松检验;随后,我会把视角转至纵向,考察前人工智能时代的笔记技术,弄清出笔记的问题及现有方案。当笔记与人工智能两条线交汇之际,我们将看到一段“阳光底下没有新鲜事的”的故事——结构良好的笔记才能受惠于人工智能,而乱糟糟的笔记只能产生更加混乱难懂的文字垃圾。
垃圾进,垃圾出,人工智能也将难为无米之炊,马太效应(Matthew effect)或将一次又一次应验。
笔记的问题:提取
某种程度上,现代人所面临的问题和祖先并无二致。信息的收集、存储以及提取问题,在采集社会时就已有其原型:原始人永远面临着如何采集食物的问题、如何存储食物的问题以及如何在恰当的时候将它们从仓库中挖出来的问题——如果时间太早,食物可能还没有完全成熟;如果时间太久,则会腐烂或被啮齿类动物啃噬。而在各个环节中最具有技术难度,同时也最富有艺术色彩的,恐怕就是提取环节。转换到现在的语境,就是如何使用信息。
几乎所有的信息管理教程和文件管理指南,都止步于如何存储信息,最多延伸到一部分的信息收集话题,可一旦提到怎么“用”(提取)信息,好像就完全是个人问题,与作者无关。这就是以拒绝代替无能,不敢谈提取、利用。
信息的利用并非玄学,无非是在需要时把他们提取出来,这和在恰当的时机从谷仓中挖出麦子有类似之处。而从标签管理、卡片笔记、双向链接到当下翕然成风的人工智能,也都在解决信息提取问题。2
Roam Research 在其白皮书指出,传统笔记一大致命缺陷就是散落四处,好像相互之间缺乏沟通往来的孤岛,在需要使用的时候,人们往往还是要从头造轮子。而在中文互联网上,卡片笔记之所以能够掀起一股浪潮,几乎全部可以归功于少数几个 KOL,他们功在指出遗忘笔记的残酷现实,尤其是那些印象笔记重度用户,十几年下来可能囤积了几千上万条笔记,但几乎不曾翻看或者难以取用,笔记工具终成手机主屏幕上象征光阴虚掷的纪念品。
人工智能也试图回答同一个问题:笔记提取。3我们不必对空胡说,盖十年前的早期人工智能已经提供了具体方案,只是效果让人不敢恭维。比如说文件管理工具 DEVONthink——也常常被用于记笔记——很早就有了 See Also 推荐,早期缺乏现在这样方便的文献关系追踪工具,DEVONthink 遂鹤立鸡群。但平心而论,DEVONthink 推荐很不可靠,因为你必须要把推荐结果通读一遍,才能发现 DEVONthink 是对是错。
人工检验环节是本文的主轴,我们将一再发现,可检验的笔记与结构良好的笔记是一枚硬币的两面,而提取,在存储时已经完成了一大半。人工智能若想易于检验、值得信赖,前提是笔记本身便于检查。
使用人工智能的成本:检验
1983 年的秋天,俄罗斯 Serpukhov-15 指挥中心警报声大作,机器宣布美国发动了核打击。当然,我们现在知道,美国并没有对俄国使用核武器,但当时的错误警报随时可能引发第三次世界大战。千钧一发之际,当时代班的彼得罗夫(Stanislav Petrov)综合其他渠道的情报后,决定不相信计算机的报告。
这一决定拯救了整个世界。
彼得罗夫当时的想法是,他们(其他要求对美国使用核武器的军人)的武器是枪支,而自己的武器是我的大脑。一个代班的公务员竟有不相信机器的底气——还是在森严的俄罗斯!——盖因彼得罗夫在参军之前是工程师,懂得分析其他渠道的情报。换言之,核警报对它而言是可检验的。
时间切回现在,语境转回笔记。在进一步讨论这些用例前,有必要先确定一个标准:人工智能的答案,何时值得采信?DEVONthink 案例和彼得罗夫的功绩已经给出了判断标准,那就是人工智能的推荐结果能否检验:如果你能够检验,那就可以相信它;反之,或者要花费比没有人工智能时更多的时间精力才能弄清对错,那么人工智能的效益就是负的。毫无疑问,人工智能的效果受制于具体任务以及具体素材。
管见以为,在思考人工智能与笔记的时候也存在着一个创造者悖论4,如果只思考笔记,这个话题可能会非常艰涩,但如果考虑一下其他领域,尝试一以贯之,问题倒更有望解决。同时,我也希望发现几个不需要检验,就可以相信人工智能的例子做给我观点的例外——事实上也是另一种补强。
注:人工智能绝非只有在能检验时才有用,但本文讨论的仅仅是笔记,尤其是笔记提取,因此能否检验是最重要的标准。Arvind Narayanan 和 Sayash Kapoor 的 文章 考察了调试、翻译和写小说三个场景并肯定了人工智能的表现。编写或修改代码
ChatGPT 无疑是人工智能浪潮的领航员,而其最坚定且也最真心实意的支持者,大概是软件行业的从业人员。Twitter 和各大论坛上捷报频传,大量帖子展示了 ChatGPT 近乎全能的编程能力:发帖者问了 ChatGPT 如何编写代码,不出10秒钟,ChatGPT 就给出了一段可以运行的代码。我自己也尝试让 ChatGPT 编写代码,写完确实可以运行,甚至比较小众的 AppleScript 也能写。
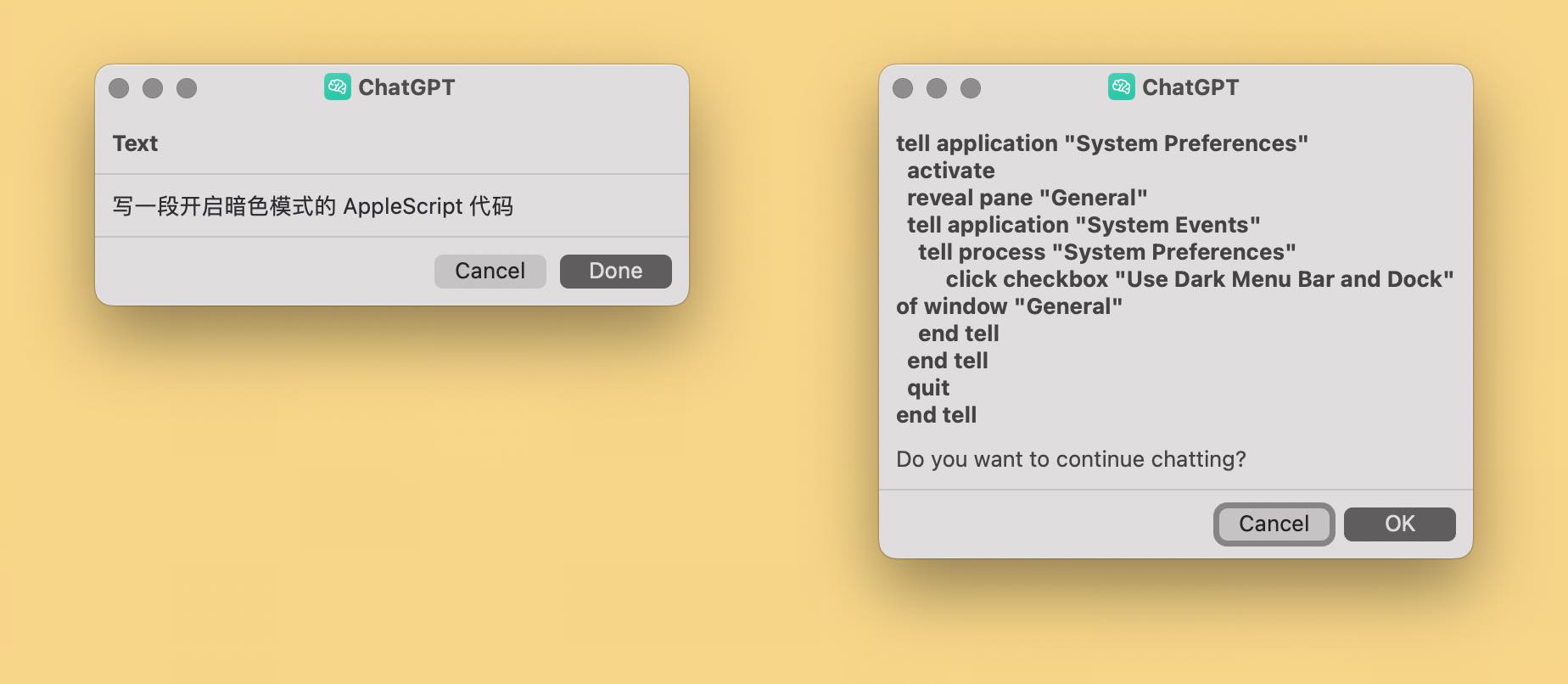
让我们姑且忽略幸存者偏差5,差不多是时候承认人工智能编写的代码确实可以用——或许效率不是最高的,语法也不是最优美的——但 just work,而且恐怕比普通人的代码质量更高。
编写或者修改代码这个例子珍贵之处,不在于它证明了人工智能具有何种能力,而在于证明了一种评判人工智能的标准,那就是能不能验证。代码无疑是最容易验证的东西之一,在程序员圈中有一句名言“闭上嘴巴,放码过来”,说的就是两个程序员在那边胡扯编程模式或者软件设计哲学三天三夜,也不如直接把代码亮出来运行一下。
扒谱子
除了编写代码,ChatGPT 在制作谱子方面的表现也非常惊人。我曾经在《用 Shortcuts 随时随地使用“ChatGPT”》提到,有时我在路上听到有一首好歌,就会拿出 Shazam 识别一下,再问 GPT-3 能不能把谱子给我;如果随身带了乐器,就可以顺手玩一下。
试着演奏 ChatGPT/GPT-3 其实就是在检验答案。这个例子和编写代码本质上没有区别。
翻译文章
不要忘了,远在 ChatGPT 引发热议之前,人工智能已经在其他领域如鱼得水,比如 DeepL 在翻译文章上的惊人表现,以及再早一点 Google Translate 引入神经网络后的质量提升。不过,人工智能之所以在机器翻译上获得认可,原因也是翻译结果可以检验。
阅读机器翻译作品的人,很多时候并不是不懂外语,只是为了节约一些时间;而且熟练的读者会在意对照翻译功能,一句原文一句译文,翻译不对路时,就可以瞄一眼原文、判断翻译是否可靠。有原文,加上一个本来就懂外语的阅读者,才有检验的可能。
如果您留心观察,不难发现,那些抵触机器翻译的人往往是连英语四六级都考不出的家伙6,他们没有能力检验机器翻译哪里错了,因此把人工智能一棍子打死。这类似于那些不愿意减肥的人,却在嘲笑坚持晨跑的你运动不足:跑步要二十五分钟以上才会燃烧脂肪哦!
为画图人工智能生成提示词
一个表面上的例外和 ChatGPT 发生在同一年,那就是人工智能绘画。只要你上网,几乎不可能不知道 Disco Diffusion、Stable Diffusion 和 DALL-E-2 这几款人工智能绘画工具:只要输入一些提示词,他们就可以生成还不错的绘画,有时候甚至让你分不清作者是人类还是机器人。
但是这并非检验主义的例外,相反,批量产出的绘画仍然需要经过检验。我们网站的题图有相当一部分是人工智能生产的,通常我们会生成上百张图片,然后从中挑选一两张最符合文章意境的图片,这就是一个检验的过程。由于我们的文章大部分是方法类,涉及具体操作,因此题图最好能够传达关于工具的信息,比如说一篇关于 Keyboard Maestro 的文章,题图通常会出现一块键盘和一只手套,知道键盘大师的人都能心领神会(键盘和手套是 Keyboard Maestro 标识)。
为数不多的真正例外,是刻意追求抽象效果或者出乎意料的美感,在人工智能绘画热潮初期,大家基本就是在求新、求怪、求异,但这种热情很快就会消退下去,以至于如今再看到蹩脚的抽象画或者半桶水的超现实主义作品,我们或许会批评这“就像是人工智能画的”。
即便是艺术创作,也仍然需要经受考验。
本节小结
从编程、音乐、翻译到绘画,那些得到认可的人工智能应用,往往都发生在可以检验且易于检验的领域。
而人工智能应用存疑的领域,如法庭辩论和医疗,同样说明了可验证性或验证成本何其重要:检验人工智能辩护词的代价可能是被告的性命,检验人工智能药物的代价更是成千上万人的性命。这是两个极端例子,但很有启发性。
人工智能和笔记提取
行文至此,我们大概可以归纳出:人工智能应用最成熟的领域,是其成果可以检验、尤其是轻松检验的领域。接下来的问题则是:人工智能提供的笔记建议,能不能检验?
MPU 论坛上有人将 ChatGPT 的回答称为“单词沙拉”(word salad),这点破了人工智能推荐的本质:它们不是无中生有,而是在你原有的笔记上面的烹饪。原有食材的好坏以及食客自己的水平,方在检验人工智能产物时位居要津。
下文难免涉及晦涩的笔记方法论,但最后的结论却非常简单:如果你的笔记本身结构良好,人工智能确实可以让你如虎添翼;如果你的笔记本来就是一笔糊涂账,那千万不要把任何希望托付的人工智能身上,它只会把水搅得更浑。
前人工智能时代的笔记提取
笔记提取是一个历史悠久的话题,美索不达米亚平原上的人就懂得提取技术,会把笔记标题或者标签写在泥板边缘,这样不用整块儿取出来就能知道大致内容。这一技术一路传承至今,nvAlt 和 FSNote 均有所谓垂直模式,可以像电话号码侧边页一样露出标题,近期笔记一览无余。
文件夹、标签、搜索和双向链接都是提取笔记的技术,而其中卓尔不群的,则是形式化编码。它们在没有人工智能的时代,对于提取笔记的难度居功厥伟;而如今,这些古董技术再一次给人工智能后生们指路:结构越好的笔记,越是可能形式化,越是易于提取。
关系编码
在卡片笔记和双向链接还没有进入公众视野时,国外论坛已有人在严肃讨论链接的问题:只知道“有关”,却无法指明有何关系。当你在笔记中看到一个链接时,如果不看上下文,一般很难知道引用这个链接是为了支持当前观点,还是指出例外,或者纯粹抛出一个问题。
我的笔记系统从较早开始就注重逻辑关系,尽可能把笔记写成推理形式,有大前期、小前提和结论。这样一来,笔记之间通常会形成一个命题网络。应对前述问题,我的方法也非常简单粗暴,就是在双向链接前后加上一些自创编码,以表示支持、否定、并列等关系。随后,借用非常简单的命令行脚本,我做了一个绿野仙踪式的“人工智能”7:输入一个笔记的标题,他会找出反对的笔记、支持的笔记已经单纯的“相关笔记”,方便从中选取立场。
Folgezettel 编码
另一种将逻辑关系形式化的方法可以直接追溯到 Luhmann。他的卡片编码体现了笔记间的关系,举个简单例子,1A、1B 和 1C 三篇笔记,同为 1 号笔记的衍生物,往往是平行概念。8
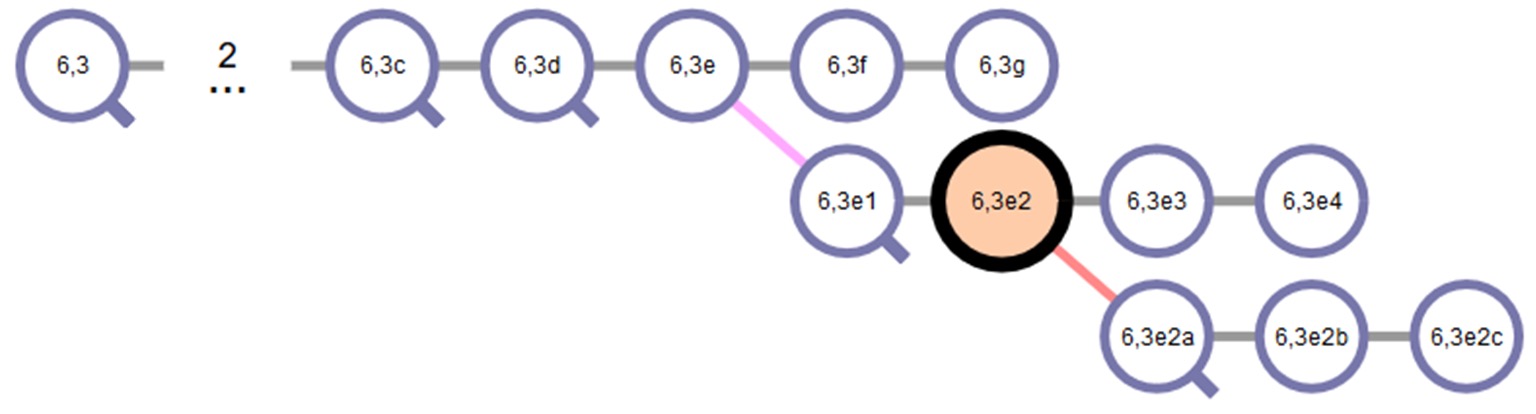
我曾经采取过 Folgezettel,以便在引用笔记时查看相关笔记。例言之,在为某个顾问单位撰写分析报告时(草稿阶段),我想引用一条关于合同无效论的笔记,发现其编码是 1B,那就说明至少存在一条编码为1A 的笔记,有必要检查一下;果然,1A 这条笔记是关于合同有效论的,尽管我为了规避风险而支持无效立场,也必须考虑有效的理由,并说明为何眼下的情况不适用有效论。
形式化编码小结
附加在双向链接前后的编码,以及笔记名称中的编码,都是将笔记内容形式化的方式,属于前人工智能时代的产物,局限性非常明显。
- 这两种编码都需要手工添,直接导致近乎恐怖的工作量。以我的亲身经历而言,写一篇四五百字的笔记,往往牵一发而动全身,需要考虑各种立场,不亚于写篇论文综述。
- 无论如何努力,也有缺漏。我在读书时选修了社会学,做过不少笔记,但后来没有从事相关工作或研究,因此后续的笔记很少引用社会学内容。直到我在本专业领域写了一点东西,才发现自己做的很多价值分析完全可以引用社会学的成熟理论——这说明形式化编码也不能妥善处理笔记提取问题。
- 这些编码本身也不干净。写在正文中的编码,显然有碍阅读,尽管人脑是一个湿件(wetware),看多了就可以跳过去,但把笔记分享给别人时,收到笔记的人就很难受;如果要对外发布,还需要手动删除这些编码,多添事端。
此外,笔记标题中的 Folgezettel 编码要求你一开始就考虑好把笔记放在哪里,这直接违背了现代卡片笔记的根本哲学——先记录后整理。现代卡片笔记软件的聪明之处,在于将唯一识别符功能和定位功能剥离开来,分别由时间戳编码和大纲笔记继承。如果一直抱着鲁曼的编码不放,估计卡片笔记早就把所有人都吓跑了。9
如果你对笔记编码技术感兴趣,可以进一步阅读拙作《卡片笔记前缀编码的艺术》,以了解前述编码技术的细节。不过,阅读本文并不需要那么多知识储备。
人工智能能为笔记做什么
新的媒介在未来或许会一骑绝尘,或许会打开全新的问题空间,让我们当下纠结的事情看上去很可笑。不过在初期,它仍然需要旧技术的扶持,也往往需要先解决现有问题。人工智能在笔记提取方面也是如此,必须先回答旧有的笔记提取难题,再开辟疆界。
重拾传统笔记提取问题
前人工智能时代的形式化编码,试图绕过笔记内容,直接指出笔记间的逻辑关系,惟成效差强人意。人工智能的第一波任务,就包括重新重拾笔记推荐(提取)。
试想,当我在写一篇关于征收土地的分析报告时,可能让人工智能帮我找出所有支持延期收回的理由,同时帮我列出反对立场的依据。形式化编码也旨在解决这一问题,但前文已经提到他们需要耗费大量人工,因而仍然需要人工智能介入。
Maggie 探讨了机器推荐笔记的可能性,Every.to 上有人尝试用 GPT-3 辅助写日记,我自己不想上传笔记,暂时只试着用早期人工智能在本地分析数据。我用的软件和 GPT-3 固然有云泥之别,然而都绕不开检验环节:问题已经不是人工智能能不能推荐相关笔记,还是我们能不能相信其推荐结果。
真正在接受考验的其实不是人工智能,而是写笔记的人和他的笔记。如果你的笔记从一开始就坚持原子化,尤其是坚持以观点为基本单位,在人工智能时代你会如鱼得水,直接处理打包好的观点,而不用反复和原始素材搏斗;相反,如果你的笔记只是流水账,那么人工智能的推荐和建议,完全就是一场灾难。
接着撰写分析报告的例子,如果你的笔记都采用表述清晰的命题形式,那么你看到的就是一系列乡所的立场,这些立场之间是平行、是趋同还是矛盾,一目了然,不需要逐个点开笔记查看原始内容。至于松散的笔记,人工智或许能越俎代庖,帮你提炼出一个观点,但此时你还是得研读背后案例,才能确定人工智能是否传达了你做笔记时的所思所想。我在《卡片笔记是什么(一):黑箱》中提出,笔记可以视为黑箱,以标题统领内容,以简驭繁;而相信笔记黑箱的前提,是诚实、认真地编写它们。
申言之,如果你的笔记只是流水账,那么使用人工智能,无非是在和过去偷懒的自己算总账。
开辟新的笔记提取方式
一种全新的媒介不会只停留在辅助旧工作流的程度,它一定会催生全新的笔记方式。
事在人为,正如 Alan Kay 所言,预测未来最好的方式就是创造未来,与其凭空胡说八道,不如动手做点实验。我在两年前构想了一种笔记健康度检查程序,后来用线性代数粗粗尝试了一下。简单来说,目标就是检查哪些笔记之间联系紧密,哪些笔记之间联系松散,哪些笔记之间存在循环论证,又有哪些笔记的论证链条太长……在纯粹的数学层面,我可以找出笔记连接网络中的特殊结构,但它们的具体意义却不甚明了,因此当时的模型也纯粹是娱乐。后来我在卡片笔记论坛中,发现也有人尝试从网络结构的角度解读卡片笔记,可惜最后也没有把结构和意义普遍挂钩起来。
人工智能或许可以发现笔记网络结构的意义,进而提出优化建议。这个话题会非常大,我自己做的实验不够多,只敢谈谈笔记提取方面的应用。我曾经关注过孤儿笔记问题,即有些笔记写完后再也没有引用过,相当于写完就丢。识别单独的孤儿笔记并不复杂,我之前就用脚本实现过,然而还有大量的“双胞胎型”或“流浪团体型”孤儿笔记,可能一对儿笔记或者三五个笔记之间互相引用,但事后也没有用过其中任何一篇。这一现象常见于进入新领域时,比如我在选修设计类课程时,记录了大量工业设计方面的概念,并且在他们之间创建了不少双向链接;简单的脚本难以把这些笔记挑出来,但是俯视整个笔记网络,他们仍然是游走在边缘的一个封闭小团体,在之后的几年里几乎没有派上用场。
人工智能有能力做得更好,能够发现那些处于边缘的笔记团体;也可以预见,人工智能有能力能发现他们属于什么话题,进而给出能否、以及如何融入笔记网络的建议。
和前一节殊途同归,问题不是人工智能能不能做到上述的一切,还是在它真的做到之后,我们该如何反应:真的照单全收,把孤儿笔记全部收养起来?这其实又落回了个人判断问题:如果你的笔记写得开门见山,人工智能的建议就很容易检验;如果你只是堆积素材,那么人工智能的建议就会变成一系列阅读理解考题,需要逐个花费大量精力研读旧笔记才能回答。
诚然,我的格局不大,不敢说更多,可万变不离其宗,不管人工智能给出怎样的惊喜,依然逃脱不了个人判断,依然需要记笔记的人自己检验。
小结
与西方的圣经遥相呼应,《道德经》也用另一种形式指出了马太效应:天之道,损有余而补不足。人之道,则不然,损不足以奉有余。
本文洋洋洒洒,无非是先贤的脚注,再一次说明了赢者通吃的道理。那些本来就习惯良好的作者,在人工智能时代也可以保持明智判断,能够独立检验人工智能的建议,兼顾提取笔记的效率与可靠;而笔记原本就是一团乱麻的人一旦遇上人工智能,要么花费更多的时间重新检验,要么就被蚁穴丛生的机器答案牵着鼻子走。
“凡没有的,连他所有的也要夺去。”
🛍 我撰写的付费栏目《信息管理,文件为本位的方案》正在 UNTAG 售卖,对本文话题有进一步讨论,欢迎选购。
- 主要是大型语言模型(LLM),不过本文为检索方便和照顾没有任何技术基础的读者,仍然使用“人工智能”的笼统说法。 ↩
- 尽管方法是在存储阶段进行整理,留下提取的线索。这就是所谓的“动态存储”(active storage),在上世纪初期到中叶被贯彻在文献管理领域和家具设计行业。您如今可以买到的 Herman Miller 模块化家具,就出自动态存储提出者 George Nelsons 之手。 ↩
- 人工智能在笔记领域的另一方向是直接替你写笔记,Zettelkasten 论坛和 MPU 论坛上对此有激烈讨论,不过 iA Blog 已经一语终结相关话题:人工智能可以帮你写,但不能帮你思考和体验。鉴于此,机器捉刀一事,本文无需再谈。 ↩
- 创造者悖论(Inventor’s paradox),“越是宏大的计划,越有机会获得成功……宏大的计划如果不是仅仅基于自负,而是基于洞察了超越那些表面现象的东西,它就更有可能获得成功。”见美波利亚:《怎样解题:数学思维的新方法》。 ↩
- 也就是说,只有那些测试成功的人才会发贴庆祝,而失败者则没有兴趣说话。 ↩
- 不考虑文学专业的特殊情况,他们不单单是为了获取信息,还要考察作者的微妙表达,这确实难为当前的人工智能。 ↩
- 绿野仙踪是界面设计中的一种方法,表面上看起来是一个成熟的交互界面,其实背后是人工在操作或响应,就像有人藏在里面的下棋机器人一样。这种设计方法得名于小说《绿野仙踪》中的 boss,看上去是一个诘屈聱牙的怪物,实际上是纸糊的壳子,背后藏着一个操控者,远没有表面看上去那么厉害。 ↩
- 在 Luhmann 的笔记中,Folgezettel 编码原则上仅仅表示卡片处于同一个上下文,而不指出进一步的逻辑关系。但当你做笔记时,完全可以严格一些,遵从一定的逻辑结构。Luhmann 的笔记有一部分已经被翻译为英文,您可以自行阅读,感受一下 Luhmann 的思路是多么奔放。对了,现在的社会学课程大概率不会用 Luhmann 的书当教材,您读完——如果能坚持读完——Luhmann 的笔记就知道原因何在。 ↩
- 严格来说,被 Folgezettel 吓跑是出于后人的误会,Luhmann 没有要求 Folgezettel 拥有层级结构——它只是“序列”,而不是“层级”。可误会已经形成,而且即便没有误会,多数人也无法接受 Folgezettel 这样复杂的系统竟然只是流水帐编号。 ↩